1. 검색 결과 화면 기능 더하기
1. 검색 결과 더보기 옵션 구현
지금은 각 도서관 검색결과에서 2권씩 가져오는 것으로 설정해두었는데 추가로 더 보고 싶은 사용자들을 위해 도서관별로 검색 결과 더보기 버튼을 추가했다. 그 버튼을 누르면 각 도서관 검색 결과 페이지 링크로 이동하도록 했다. 이는 javascriptd의 switch문을 이용해 함수의 인수로 입력받은 대학 이름과 검색어에 따라 목표 url이 변경되고 해당 대학 block에 append 해주는 함수를 통해 구현했다.
function more_result(uni_name, keyword) {
switch (uni_name) {
case 'yonsei':
var uni_url = "https://library.yonsei.ac.kr/main/searchBrief?q=" + keyword;
var temp_html3 = ` <div class="more-result">
<a href="${uni_url}">
검색결과 더보기
<i class="fa fa-plus" aria-hidden="true"></i>
</a>
</div>`
$("#yonsei-blocks").append(temp_html3);
break;
case 'ewha':
var uni_url = "http://lib.ewha.ac.kr/search/tot/result?st=KWRD&si=TOTAL&service_type=brief&q=" + keyword;
var temp_html3 = ` <div class="more-result">
<a href="${uni_url}">
검색결과 더보기
<i class="fa fa-plus" aria-hidden="true"></i>
</a>
</div>`
$("#ewha-blocks").append(temp_html3);
break;
case 'sogang':
var uni_url = "https://library.sogang.ac.kr/searchTotal/result?st=KWRD&si=TOTAL&q=" + keyword;
var temp_html3 = ` <div class="more-result">
<a href="${uni_url}">
검색결과 더보기
<i class="fa fa-plus" aria-hidden="true"></i>
</a>
</div>`
$("#sogang-blocks").append(temp_html3);
break;
default:
break;
}
}2. 검색 결과가 없을 때 보여주는 화면 구현
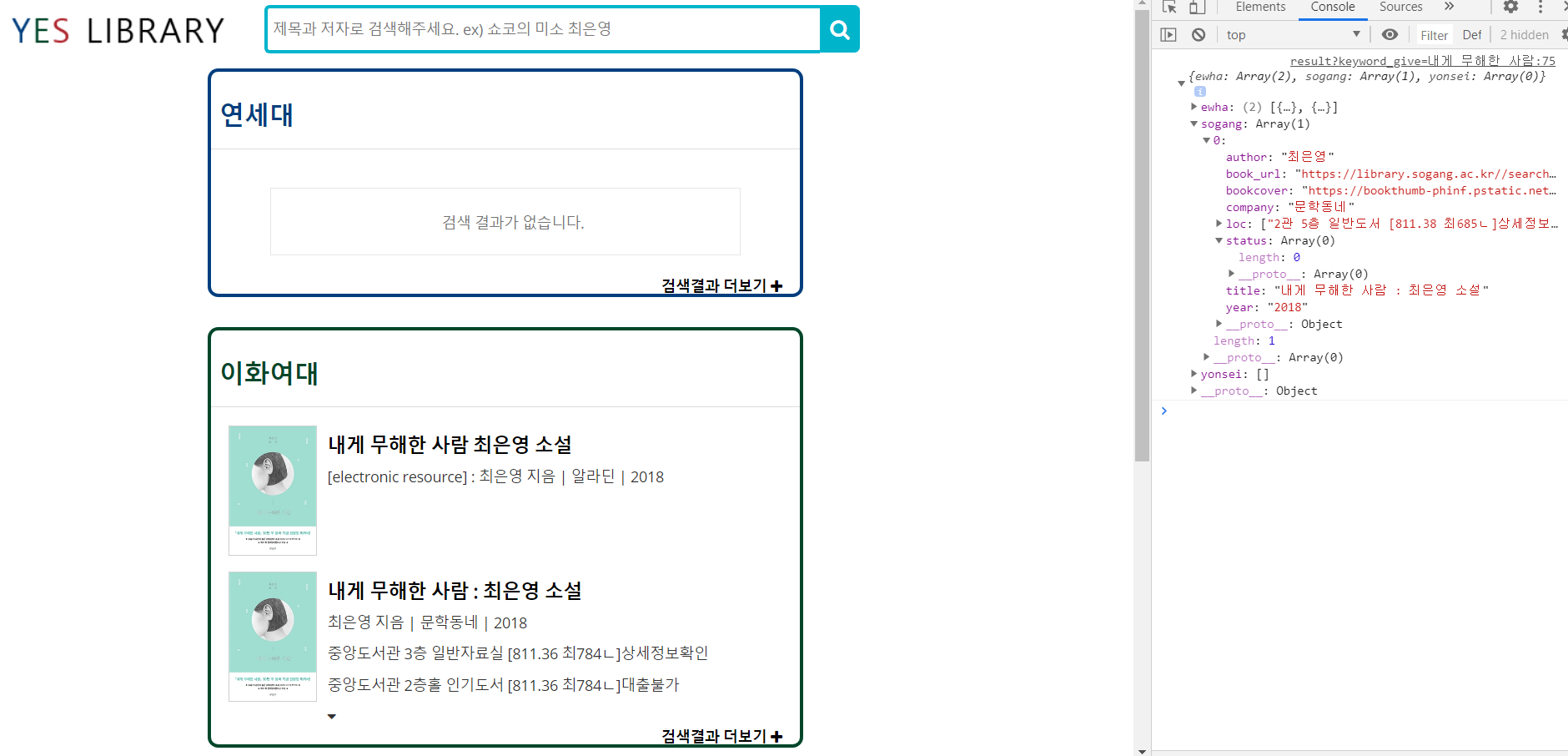
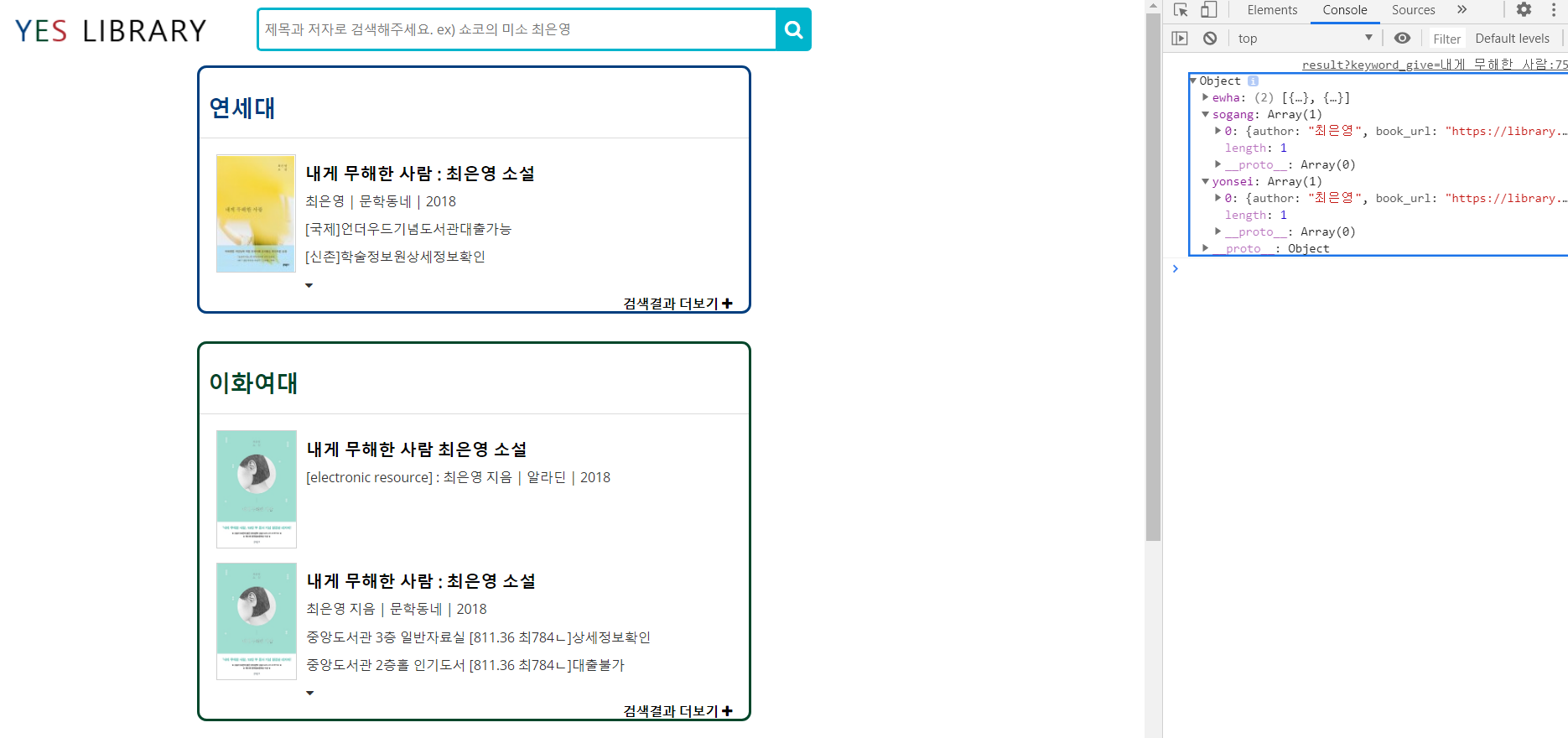
각 도서관 홈페이지에서 검색어에 대한 검색 결과가 없으면 '검색 결과가 없습니다' 라는 화면을 보여준다. 이 경우 통합검색 서비스에서도 이 대학 도서관에는 검색어에 대한 결과가 없다는 것을 보여줘야 한다. 이를 위해 도서관 홈페이지에 검색결과가 없는 것은 크롤링 결과 title이 없을 때로 정의하고 이 경우 도서관 홈페이지를 크롤링 하는 함수를 종료한다.
title = li.select_one("p > a")
if title is None:
return
else:
title = title.text그러면 ajax에 담겨있는 각 대학의 list는 빈 리스트가 되고 빈 리스트가 넘어오게 되면 '검색결과가 없습니다.' 라는 값을 append하는 함수를 실행하고 기존에 수행하던 검색 결과를 추가해주는 함수를 수행하지 않는다.
function make_card(uni_name, uni_list = []) {
if (uni_list.length == 0) {
empty_result(uni_name);
return;
} // 아닌경우 계속 진행function empty_result(univ) {
let empty_temp = `<p class="no-data">
<span>검색 결과가 없습니다.</span>
</p>`;
$("#" + univ + "-blocks").append(empty_temp);
}2. 웹서비스를 런칭하기 위한 작업들
스파르타 코딩클럽 6~8주차 수업 내용을 기반으로 아래 작업들을 수행했다.
-
AWS EC2에서 서버 사기
-
EC2 서버에 filezilla를 통해 지금까지 작업한 파일 옮기기
-
필요한 패키지 설치하기(pip, bs4, flask, selenium, pymongo)
linux 환경에서 selenium을 활용하기 위해서 selenium 패키지 설치하기, chrome 설치하기, chromedriver 설치하기, headless 방식으로 chromedriver 실행하기의 과정을 수행했고 이 블로그(https://dvpzeekke.tistory.com/1)의 많은 도움을 받았다.
-
SSH 접속을 끊어도 서버가 계속 작동하도록 하기
# 아래의 명령어로 실행
nohup python app.py &
# 아래 명령어로 미리 pid 값(프로세스 번호)을 본다
ps -ef | grep 'python'
# 아래 명령어로 특정 프로세스를 죽인다
kill -9 [pid값]- url 뒤에 붙는 포트번호(5000)을 없애기
80포트로 들어오는 요청을 5000포트로 포워딩 시켜줘야 한다. 이를 위해 포워딩 룰을 입력한다.
sudo iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j REDIRECT --to-port 5000- 가비아에서 도메인 구매하기(http://yeslibrary.shop/)
- og 태그 붙여 공유할 때 활용하기
# <head>~</head> 사이에 입력
<meta property="og:title" content="내 사이트의 제목" />
<meta property="og:description" content="보고 있는 페이지의 내용 요약" />
<meta property="og:image" content="{{ url_for('static', filename='ogimage.png') }}" />3. 해결해야 할 문제
local 개발 환경에서는 도서관 홈페이지 크롤링과 그 데이터를 HTML로 보여주기가 의도한대로 기능하는 것과 달리 AWS EC2에 리눅스 우분투 서버를 이용하면 연세대 도서관 홈페이지 크롤링과 서강대 도서관 홈페이지 대출현황 데이터 크롤링이 제대로 되지 않는다.
4. TIL
- 수행하던 기능을 종료하고 block에서 빠져나가고 싶을 때 쓰는 return과 break의 차이. return은 함수 종료. 함수 내부에서 쓰이면 값을 반환하며 함수의 실행을 종료하고 함수를 호출했던 지점으로 돌아간다. break는 반복문 종료. for, while, switch 등 여러 번 반복되는 loop에서 탈출한다. 함수 자체에서 빠져나가는 return과 달리 break는 함수 안에서 쓰인 반복문에서만 빠져나간다는 차이가 있다.
- switch문에서는 각 case마다 실행할 코드를 지정해주고 break를 해주어야 한다.
- 웹서비스를 런칭하기 위한 일련의 과정을 수행하면서 현재 배포되어 사람들이 사용하고 있는 웹서비스의 원리를 알 수 있었고 리눅스의 기초적인 사용법, 도메인의 의미 등을 알 수 있었다.
