문제 해결
지난주 금요일에 기존 로컬 환경에서 개발한 것들을 AWS EC2 우분투 서버에서 작동하도록 해보았다. 그때 로컬에서는 정상적으로 작동하던 기능들이 우분투로 가자 제대로 기능하지 못했다. 연세대 도서관 홈페이지 크롤링은 아예 안됐고 서강대 도서관 홈페이지에서는 첫번째 도서의 대출현황만 불러와지지 않았다.
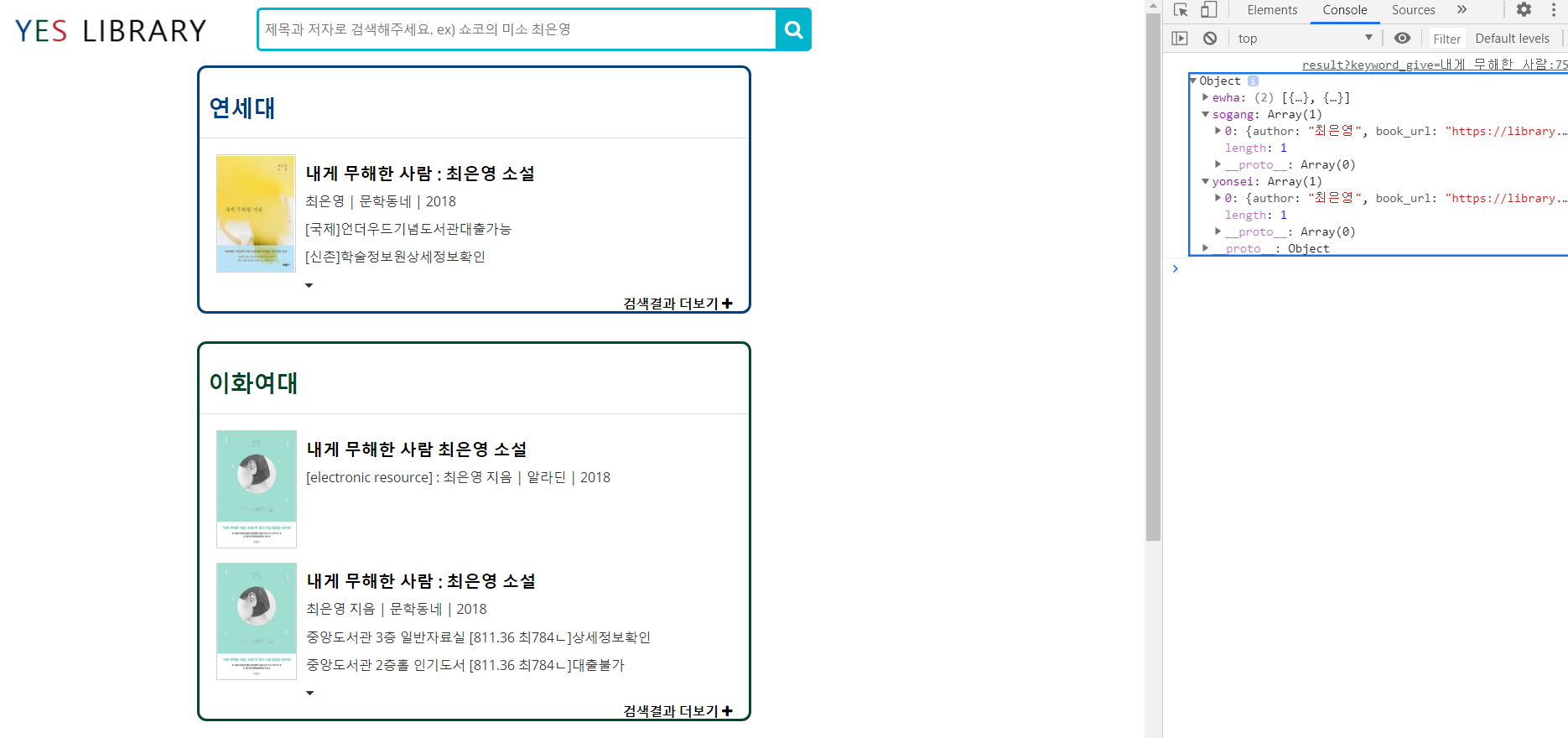
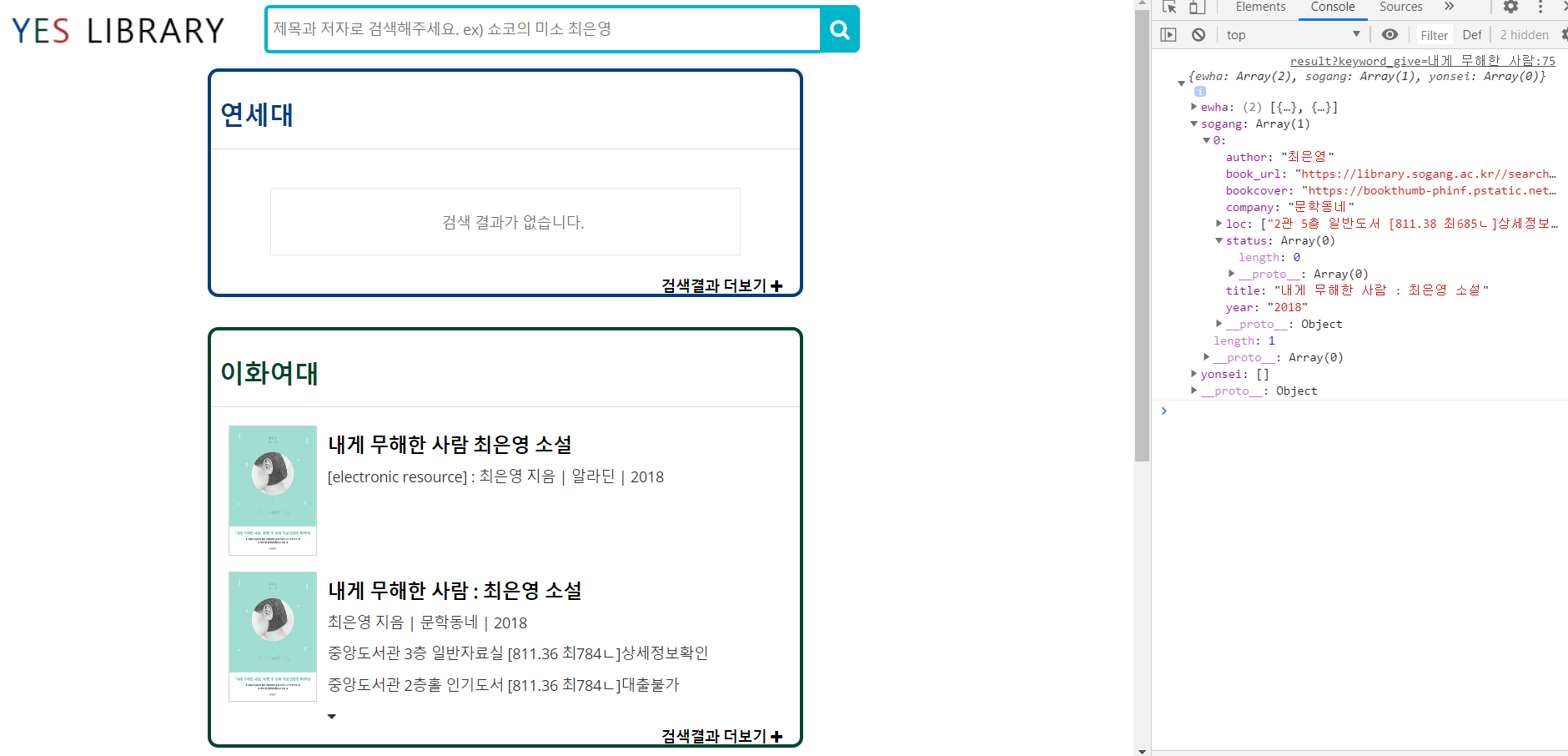
이 문제를 해결하기 위해 주말동안 이리저리 계속 코드를 수정해봤는데도 문제를 고치지 못했었다. 로컬에서 개발할 때는 selenium이 제어하는 브라우저를 볼 수 있으니 어느 부분에서 문제가 생기는지 즉각적으로 볼 수 있었는데 linux 환경에서는 selenium의 작동 상황을 볼 수 없으니 막막하게 느껴졌다. 그래서 튜터님께도 계속 조언을 구하고 스파르타 코딩클럽 슬랙 전체 잡담방에도 질문을 올렸다.
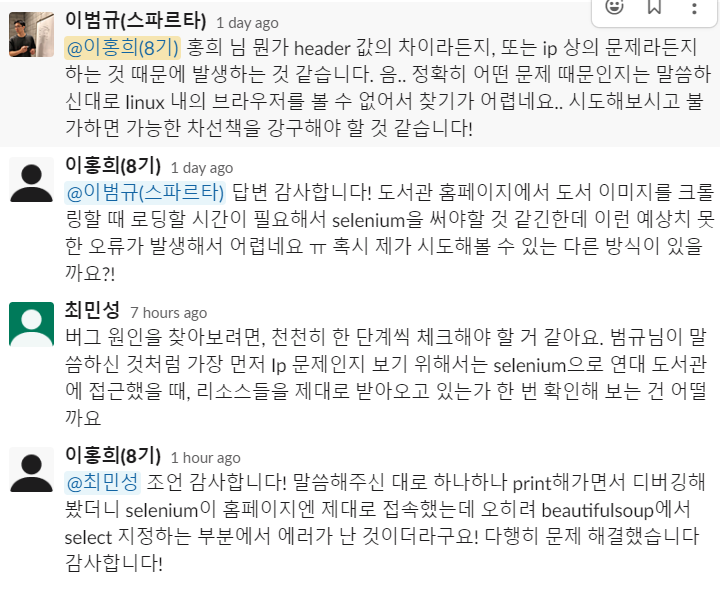
튜터님들의 조언에 따라 변수 하나하나 아래에 print문을 넣어서 디버깅을 해보니까 어느 부분에서 문제가 생겼는지 알 수 있었다. 막연히 linux에서 selenium이 불안정하게 작동해서 그런게 아닐까 생각했었는데 디버깅 결과 오히려 beautifulsoup로 가져온 soup에 다시 원하는 선택자를 select로 지정하는 과정에서 에러가 발생한 것이었다. 크롤링하고 싶은 부분의 클래스명으로 다시 지정하자 크롤링이 정상적으로 되었다.
서강대 홈페이지에서 도서 대출현황 정보가 크롤링 되지 않는 문제는 click()의 대상이 되는 element의 xpath를 더 구체적으로 지정해주자 해결되었다.
# /a를 추가하였다
jss = driver.find_elements_by_xpath("//p[@class='location']/a")
js_count = 0
for js in jss:
js.click()
time.sleep(0.5)
js_count += 1
if js_count == 2:
breakTIL
- 디버깅하다가 결국 잘 모르겠으면 하나하나 찍어봐야 한다. 이 변수에 내가 원하는 값이 잘 들어갔는지.
- 로컬 환경과 AWS EC2 서버 환경, window와 linux처럼 프로그램 실행 환경이 바뀌면 여기선 잘 작동하던 코드가 저기서는 잘 작동하지 않는 일들을 마주할 수 있다.

개발꿈나무 무럭무럭 자라는 중!