[5] Fuzzing: Art, Science, and Engineering 논문 보고서
5 INPUT GENERATION
Test Case 의 내용에 따라서 버그가 트리거 되는지 직접적으로 결정되기 때문에, 입력값을 만드는 것은 퍼저를 설계하고 개발할때에 가장 중요한 부분(design decision)이다.
전통적으로 fuzzer는 1. generation-based fuzzer 2. mutation-based fuzzer로 분류된다.
Generation based fuzzers 에서는 Model이 PUT에 의해 예상되는 입력을 알려주고 이를 기반으로 Test Case를 생성한다. 우리는 이런 fuzzer를 model-based fuzzers라고 부른다
반면에 mutation-based fuzzers는 PUT에 의해 예상되는 입력에대한 정보가 전혀없이 주어진 seed 입력값을 mutating 하여 Test Case를 생성한다. 이 때 seed는 입력의 예시이고 seed가 아무리 많더라도 모든 PUT의 입력가능한 경우의 수(expected input space)를 전부 표현할 수는 없기 때문에 Mutation-based fuzzer는 일반적으로 Model이 없는 것으로 간주된다.
- generation-based fuzzer(model-based fuzzer)
- PUT의 입력 형태를 고려한 Model 있음
- model이 PUT에 가능한 입력값을 알려주고 이를 이용해서 test case를 생성함
- mutation-based fuzzer
- 일반적으로 PUT의 입력 형태를 고려한 모델이 없다고 간주
- seed를 mutation하여 입력값을 생성함
5.1 Model-based (Generation-based) Fuzzers
Model-based fuzzers는 PUT이 받아들일 수 있는 입력 또는 실행을 설명하는 주어진 Model을 기반으로 test case를 생성한다. 이 Model은 예를 들어 입력 형식을 정확하게 characterizing 하는 문법이나 파일 type을 식별하는 magic value과 같이 덜 정확한 제약조건(less precise constraints) 같은 것이다.
- 덜 정확한 제약조건(less precise constraints) : 어떠한 인풋에 따라 로직이 실행되는지 여부를 결정하는 조건을 제약조건이라 함. 이 중 덜 정확한 제약 조건이라는 의미는 아마 예시가 파일type을 식별할때 사용되는 magic value로 되어있는걸 보면 magic value 처럼 특정파일 type에 따라 추측하는 것이 매우 쉬운 제약조건과 같은 경우를 느슨한 제약 조건으로 이해하면 될 듯.
5.1.1 Predefined Model
일부 fuzzer는 사용자가 구성할 수 있는 Model을 사용한다.
예를 들어 Peach, PROTOS 및 Dharma는 사용자가 직접 세부사항을 결정한다.
Autodaf'e, Sulley, SPIKE및 SPIKE 파일은 분석가가 자체 입력 Model 을 만들 수 있는 API를 제공한다.
Tavor [240]은 또한 확장 백커스-나우르 형식(EBNF)으로 작성된 입력 규격을 받아들여 해당 문법에 부합하는 test case를 생성한다.
- EBNF (Extended Backus-Naur form )
-
컴퓨터 과학 에서 EBNF ( Extended Backus-Naur form ) 는 메타 구문 표기법 계열이며 , 그 중 어떤 것이든 context-free 문법 을 표현하는 데 사용할 수 있다 . EBNF는 컴퓨터 프로그래밍 언어 와 같은 형식 언어 를 형식적으로 설명하는 데 사용된다 .
-
마찬가지로, PROTOS, SNOZE, KiF 및 T-Fuzz와 같은 네트워크 프로토콜 fuzzer도 사용자가 프로토콜 세부사항을 결정한다.
커널 API fuzzer는 System call 템플릿의 형태로 입력 Model을 정의한다.
이러한 템플릿은 일반적으로 system call이 예상하는 argument의 수와 type을 입력으로 지정한다.
- argument와 parameter의 차이점 : Parameter는 함수 혹은 메서드 정의에서 나열되는 변수 명. Argument는 함수 혹은 메서드를 호출할 때, 전달 혹은 입력되는 실제 값.
단어 번역 의미 Parameter 매개변수 함수와 메서드의 입력 변수(Variable) 명 Arguemtn 인자, 전달인자 함수와 메서드의 입력 값(Value)
Model을 사용하는 fuzzer
커널 fuzzing에서 Model을 사용하는 발상은 System call을 위해 수동으로 선택한 test case와 OS의 견고성을 비교한 Koopman 등의 주요 연구에서 비롯되었다.
Nautilus는 범용 목적의 fuzzing(general-purpose fuzzing)을 위해 문법 기반의 입력값을 생성하고 seed trimming을 위해 문법을 사용한다(제3.3 참조).
- seed trimming → seed 크기 줄이기 : 시드가 작을수록 메모리는 더 적게 소비하고, 더 높은 throughput을 유도한다. 따라서 어떤 퍼저는 퍼징을 하기 전에 먼저
시드의 크기를 줄인다. 이런 기술을seed trimming이라고 한다. 시드 트리밍은 PREPROCESS에서 메인 fuzzing loop을 수행하기 전에 수행되거나, CONFUPDATE의 일부분으로 수행된다.
다른 model 기반 fuzzer는 특정 언어 또는 문법을 대상으로 하며, 이 언어의 model은 fuzzer 자체에 내장되어 있다.
예를 들어, cross fuzz 및 10 DOM 퍼지는 랜덤 문서 객체 모델(DOM) 객체를 생성한다. 마찬가지로, jsfunfuzz는 자체 문법 model을 기반으로 랜덤이지만 구문적으로 정확한 자바스크립트 코드를 생성한다.
- jsfunfuzz - 구문적으로 정확하기에 실행이 가능한 랜덤 입력값이 생성
QuickFuzz 는 test case를 생성할 때 파일 형식(format)을 설명하는 기존 Haskell 라이브러리를 활용한다.
Francerts, TLS-Attacker, TLS-Attacker 및 llfuzer와 같은 일부 네트워크 프로토콜 fuzzer는 TLS 및 NFC와 같은 특정 네트워크 프로토콜의 model을 갖고 설계된다.
“Language fuzzing using constraint logic programming”,”Fuzzint the rust typechecker using clp”에서는 제약 논리 프로그래밍을 활용하여 문법적으로 정확할 뿐만 아니라 의미적으로 다양한 test case를 생성하는 방법을 설명하고 있다.
LangFuzz 는 입력으로 제공되는 seed 세트를 파싱하여 코드 조각을 생성한다. 그런 다음 조각들을 무작위로 결합하고, seed를 코드 조각들과 mutate시켜 test case를 생성한다.이러한 LangFuzz는 문법을 이용하기 때문에 항상 구문적으로 올바른 코드를 생성하고 자바스크립트와 php에서 사용된다.
BlendFuzz 는 LangFuzz와 유사한 방식이지만 그 대상이 XML 및 정규 표현식 파서라는 점에서 차이가 있다.
5.1.2 Inferred Model
최근에는 사전에 정의되거나 사용자가 제공하는 model에 의존하지 않고 model을 추론하는 방식이 주목을 받고 있다.
자동화된 입력 형식(포맷)과 프로토콜 리버스 엔지니어링에 대한 연구가 많이 있지만, 소수의 fuzzer만 이 방식을 사용하고 있다.
instrumentation(§ 3.1)과 유사하게 model 추론은 PREPROCESS 또는 CONFUPDATE에서 진행할 수 있다.
5.1.2.1 Model Inference in PREPROCESS:
일부 fuzzer에서는 Model을 전처리 단계에서 추론한다.
TestMiner 는 적절한 입력을 예측하기 위해 Literal과 같이 PUT에서 사용할 수 있는 데이터를 찾는다. seed set와 문법이 주어지면 Skyfire 는 데이터 기반의 접근 방식을 사용하여 확률론적 Context-Sensitive Grammar를 추론한 다음 이를 사용하여 새로운 seed set을 생성한다.
⇒ 어떤 형태로 입력받는지 모르니까 PUT안에서 사용하는 데이터 뭐가 있는지를 참고하여 확률론적 context-sensitive grammar 하여 새로운 seed set(입력값 예시)를 생성한다. 이는 이전 작업들과 달리, 의미적으로 유효한 입력(semantically valid inputs)을 생성하는데 중점을 둔다.
-
Context-Sensitive Grammar(문맥 의존 문법)에 대한 설명
문맥 의존 문법(context-sensitive grammar) → 예를들어 ㄴAㄱ 이라는 상태에서 A를 a로 바꿔주려고 할 때 a도 ㄴaㄱ 형태로 앞뒤에 ㄴ과 ㄱ이 있어야한다는 것임. 이 때 ㄴ과 ㄱ이 문맥이고 이 형태일 때만 바꿀수 있기 때문에 문맥의존 문법이라고함. 문맥 자유문법은 앞뒤에 뭐가오든 바꿀수가 있음.
문맥의존문법

문맥의존 문법 예시

IMF는 시스템 API 로그를 분석하여 커널 API 모델을 학습하고, 추론한Model을 사용하여 일련의 API 호출을 호출하는 C언어 코드를 생성한다.
CodeAlchemist 은 자바스크립트 코드를 "code bricks"로 분할하고 어셈블리 제약조건을 계산한다. 이 어셈블리 제약조건은 의미론적으로 유효한 test case를 생성하기 위해 서로 다른 brick을 조립하거나 병합할 수 있는 지에 대한 조건이다. 이러한 제약 조건은 정적 분석과 동적 분석을 모두 사용하여 계산한다.
-
CodeAlchemist 의 방식

//을 통해 주석 단것 하나하나가 다 code brick임.
a가 들어오면 이걸 시드를 통해서 아래와 같은 Abstract syntax tree를 만듬
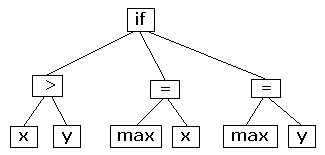
그리고 code alchemist는 이 abstract syntax tree를 js 구문단위로 나누어 code brick을 만들고 이를통해 제약조건 계산하고 새로운 테스트케이스를 만듬.
“Neural Fuzzer”와 “Learn&Fuzz : Machine learning for input fuzzing”은 신경망 기반 머신러닝 기술을 사용하여 주어진 테스트 파일 세트에서 Model을 학습하고, 추론된 Model을 바탕으로 test case를 생성하는 방식을 사용한다.
“Automatic text input generation for mobile testing”에서 텍스트 입력값을 대상으로 위와 유사한 접근 방식을 제안했다.
5.1.2.2 Model Inference in CONFUPDATE:
각각의 fuzz 반복 후에 모델을 업데이트 하는 fuzzer도 있다. 예를들어 PULSAR는 프로그램에서 생성된 캡처된 네트워크 패킷 집합으로부터 네트워크 프로토콜 model을 자동으로 추론한다.
학습된 네트워크 프로토콜은 프로그램을 fuzzing 하는 데 사용된다. PULSAR는 내부적으로 state machine를 구축하고 어떤 메시지 토큰이 상태와 상관관계가 있는지 매핑(연결)한다. 이 정보는 나중에 state machine의 더 많은 상태를 커버하는 test case를 만드는 데 사용한다.
-
state machine → 현재 하고 있는 것에 따라서 무슨 상태인지 확인
https://underflow101.tistory.com/55
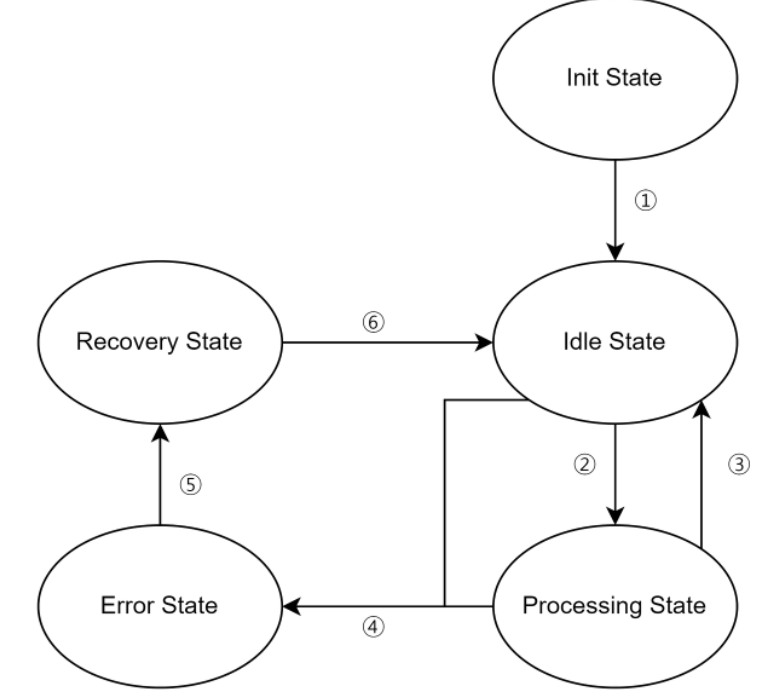
A) Init State에서 디바이스의 각종 이닛을 처리하고,
① 이닛 프로세스가 모두 종료되면
B) Idle State로 향하고 대기한다.
② 센서나 외부 입력이 감지되면
C) Processing State로 향하고 입력값에 대한 처리를 진행한다.
③ 입력값에 대한 처리가 끝났다면 이를 디스플레이에 표시하거나 서버에 전송하고
D) 다시 Idle State로 향한 후 대기한다.
④ 만약 Idle State나 Processing State에서 에러가 발생했다면, 에러 코드를 가지고서
E) Error State로 향하고 에러 코드를 분석한다.
⑤ 만약 에러 코드가 복구 가능한 에러라면,
F) Recovery State로 향해서 복구를 진행한다.
⑥ 복구가 끝이 났다면
G) Idle State로 다시 되돌아가서 대기한다.
“Enemy of the State: A state-aware black-box web vulnerability scanner” 에서는 입출력 동작을 관찰하여 웹 서비스의 state machine를 추론하는 방법을 제시한다. 그런 다음 추론된 model을 사용하여 웹 취약점을 찾는다.
“Protocol state fuzzing of tls implementations”도 위와 유사하지만 TLS를 대상으로 하며 “LearnLib:A library for automata learning and experimentation” 를 기반으로 구현한다.
“Synthesizing program input grammars”는 일련의 I/O 샘플에서 context-free 문법을 합성하고, 추론된 문법을 사용하여 PUT을 fuzz 한다.
마지막으로, go-fuzz 는 grey-box fuzzer로, seed pool에 추가하는 각각의 seed model을 구축한다. 이 model은 seed를 이용해서 새 입력값을 생성한다.
5.1.3 Encoder Model
fuzzing은 종종 특정 파일 형식(포맷)을 구문 분석하는 디코더 프로그램을 테스트하는 데 사용된다. 많은 파일 형식(포맷)에는 해당 인코더 프로그램이 있으며, 이는 파일 형식(포맷)의 내포된 모델(implicit model, 무조건적인 모델?)로 생각할 수 있다.
-
인코더 프로그램은 파일 형식(포맷)에 대한 기본적인 구조를 가지고 있으며 이 기본적인 구조에 대한 정보를 test case를 만들 수 있는 model로 생각할 수 있음.
MutaGen 은 인코더 프로그램에 포함된 이 암시적 모델을 활용하여 새로운 test case를 생성하는 고유한 fuzzer이다. MutaGen은 mutation을 활용하여 test case를 만들지만, 기존의 test case를 mutation 하는 대부분의 mutation-based fuzzer와 달리(§ 5.2 참조), MutaGen은 인코더 프로그램을 mutation 한다.
-
pdf reader의 테스트 인풋값을 생성하는 케이스를 바탕으로 한 일반적인 mutation과 mutagen의 비교
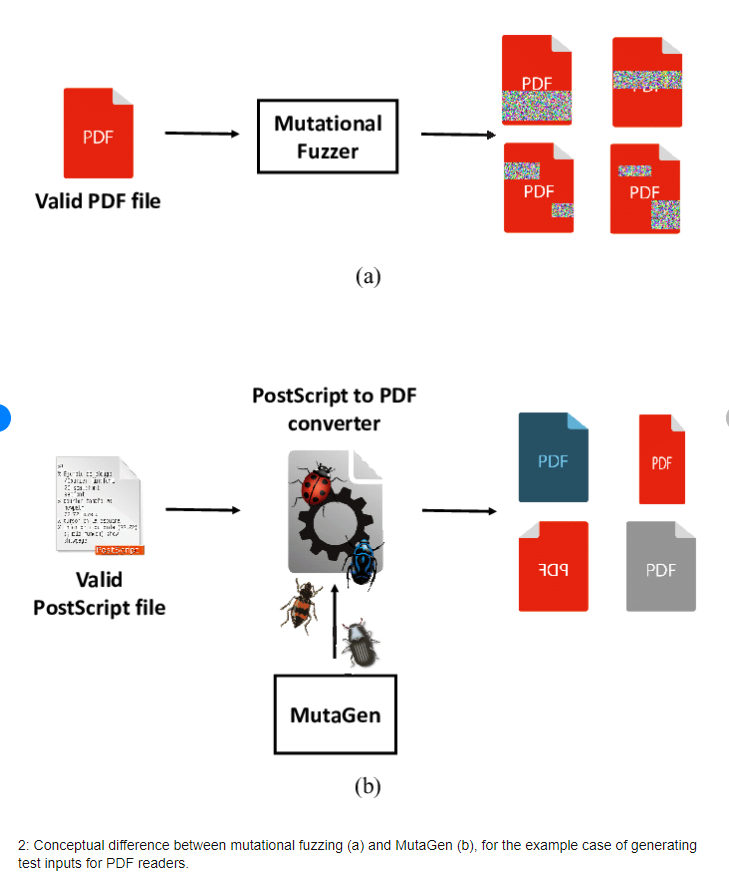
특히, 새로운 test case를 생성하기 위해 MutaGen은 인코더 프로그램의 동적 프로그램 슬라이스(관심 지점의 값에 영향을 미칠 수 있는 프로그램 명령문 집합)를 계산하고 실행한다. 핵심 아이디어는 프로그램 슬라이스가 인코더 프로그램의 동작을 약간 변경하여 약간 변형된 test case 를 생성한다는 것이다.
- program slice - 관심지점의 값에 영향을 미칠 수 있는 프로그램 명령문 집합을 computation(계산)하는 것 즉 어떤 명령 집합이 내가 원하는 지점에 영향을 미치는지 찾는 것을 의미 https://en.wikipedia.org/wiki/Program_slicing 컴퓨터 프로그래밍 에서 프로그램 슬라이싱 은 slicing criterion 이라고 하는 관심 지점의 값에 영향을 미칠 수 있는 프로그램 명령문 집합, 프로그램 슬라이스의 계산 입니다 . 디버깅 에 프로그램 슬라이싱을 사용하여 오류 소스를 보다 쉽게 찾을 수 있습니다. 슬라이싱의 다른 응용 프로그램에는 소프트웨어 유지 관리 , 최적화 , 프로그램 분석 및 정보 흐름 제어 가 포함 됩니다.
5.2 Model-less (Mutation-based) Fuzzers
기존의 무작위로 테스트하는 방법은 특정 경로로 가기 위한 조건을 만족하는 test case를 생성하는 데 효율적이지 않다. 간단한 C언어로 된 문장이 있다고 가정하자: if (input == 42) 만약 입력이 32비트 정수일 경우 올바른 입력 값을 랜덤하게 추측할 확률은 1/2^32이다.
MP3 파일과 같은 잘 구성된 복잡한 입력값을 만들어야 할 경우 무작위로 만든 test case가 적절한 시간 내에 유효한 MP3 파일을 생성할 가능성은 극히 낮다.
결과적으로, MP3 플레이어는 프로그램의 더 깊은 부분에 도달하기 전에 파싱 단계의 무작위 테스트에서 만든 test case 대부분이 막힐 것이다.
⇒ 파일 시그니처.. 파일 구조.. 등등 다 만족해서 MP3 형식의 파일을 만들어낼 확률은 정말 극히 드물다. 심지어 만든 인풋으로 실행도 막힐 가능성이 높음
이 문제는 white-box 입력 생성 뿐만 아니라 seed-based 입력 생성을 사용하도록한다(§ 5.3 참조). 대부분의 model-less fuzzer는 seed를 수정하여 test case를 생성하기 위하여 PUT에서 입력값이 되는 seed를 사용한다.
⇒ 인풋을 어거지로 넣지는 말고, seed를 참고해서 input을 생성하고자함
seed는 일반적으로 파일, 네트워크 패킷 또는 일련의 UI 이벤트와 같은 PUT에 의해 지원되는 유형의 잘 구성된 입력값이다. 유효한 파일의 일부만 변형함으로써, 대부분 유효하지만 PUT의 crash를 유발하는 비정상적인 값을 포함하는 새로운 test case를 생성하는 것이 가능하다. seed를 mutate 시키는 방법은 다양하며, 일반적으로는 다음과 같다.
→ 즉 seed는 PUT을 실행할 때 넣을 수 있는 입력값의 예시이다
5.2.1 Bit-Flipping
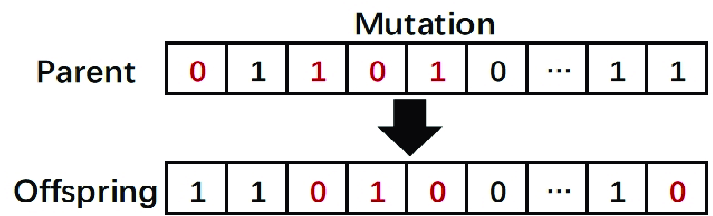
Bit-flipping은 많은 model-less fuzzer에서 사용되는 일반적인 기술이다. 어떤 fuzzer에서는 고정된 수의 비트를 뒤집는 반면, 다른 fuzzer는 무작위로 뒤집을 비트의 수를 결정한다.
일부 fuzzer는 시드를 무작위로 mutation 하기 위해 mutation 비율이라는 사용자가 정할 수 있는 매개 변수를 사용한다. 이는 INPUTGEN 을 단일 실행시에 뒤집을 비트 위치 수를 결정한다. 이 mutation 비율의 예를 들면 fuzzer가 주어진 N 비트의 seed에서 K개의 랜덤 비트를 뒤집으려할 때 이 경우 fuzzer의 mutation 비율은 K/N이다. SymFuzz는 fuzzing 성능이 mutation 비율에 따라 달라지며, 최적의 mutation 비율은 PUT 마다 다르다는 것을 보여주었다.
좋은 mutation 비율을 찾기 위한 몇 가지 접근법이 있다.
BFF 및 FOE는 각 seed에 대해 지수적으로 스케일링된 mutation 비율 집합을 사용하고 통계적으로 효과가 있는 것으로 입증된 mutation 비율에 더 많은 반복을 할당한다. SymFuzz 는 white-box 프로그램 분석을 활용하여 각 seed에 대해 적절한 mutation 비율을 추론한다.
5.2.2 Arithmetic Mutation
AFL 및 honggfuzz 는 선택한 바이트 sequence를 정수로 간주하고 해당 값에 대해 간단한 연산을 수행하는 또 다른 mutation 연산을 수행한다. 그런 다음 계산된 값을 사용하여 선택한 바이트 sequence를 바꾼다. 이 때 핵심은 mutation을 적게 하는것이다.
예를 들어, AFL은 seed에서 4바이트 값을 선택하고 이 값을 정수 "i"로 처리한다. 그런 다음 시드의 값을 "i ± r"로 바꾼다. 여기서 r은 무작위로 생성된 작은 정수이다. r의 범위는 fuzzer에 따라 다르며 종종 사용자가 정할 수 있다. AFL에서 기본 범위는 '0 ≤ r < 35'이다.
→4바이트면 2^32값인데 이 값을 +-34까지만 한다는 건 정말 조금 변이시키는 것
5.2.3 Block-based Mutation
블록은 시드의 바이트 sequence이며, 여러 블록 기반 mutation 방법이 있다.
(1) 무작위로 생성한 블록을 seed의 무작위 위치에 삽입
(2) seed로부터 무작위로 선택한 블록을 삭제
(3) 무작위로 선택한 블록을 임의의 값으로 대체
(4) 블록 시퀀스의 순서를 임의로 바꿔 넣음(permute)
(5) 랜덤 블록을 추가하여 seed 크기를 조정
(6) seed로부터 랜덤 블록을 가져와 다른 seed 의 랜덤 블록에 삽입/교체
5.2.4 Dictionary-based Mutation
일부 fuzzer는 미리 정의한 잠재적으로 의미가 있는 semantic 가중치(예: 0 또는 -1)를 가진 값 집합과 mutation을 위한 format string을 사용한다.
예를 들어, AFL, honggfuzz및 LibFuzzer 서는 정수를 변환할 때 0, -1 및 1과 같은 값을 사용한다. Radamsa 는 Unicode 문자열을 사용하고 GPF 는 %x 및 %s과 같은 형식 문자를 사용하여 문자열을 변환한다 .
-
Dictionary 기반 mutation 알고리즘 예제
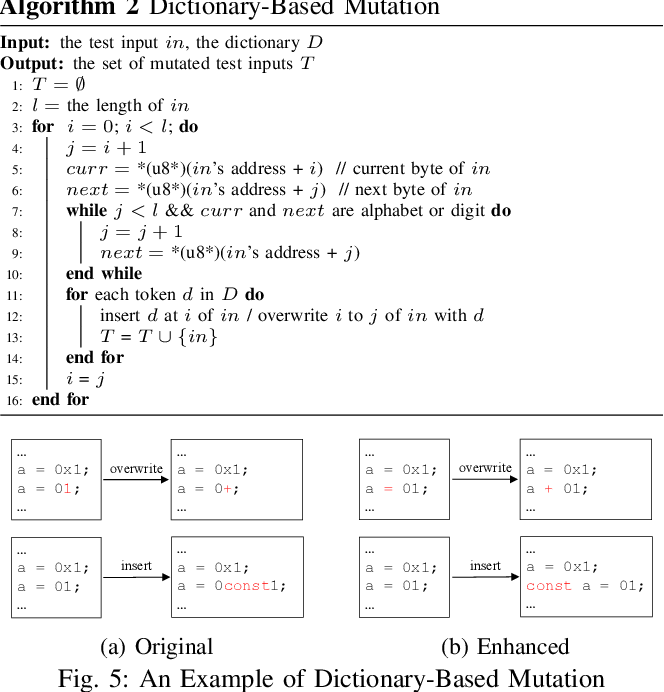
사전에 있는 각 토큰(1,0,-1)에 대해서 input값에 넣거나 사전에 있는 각 토큰으로 input값 부터 input+1값까지 덮어쓰며 그 결과값인 input 을 test case 집합에 포함시킨다.
5.3 White-box Fuzzers
White-box fuzzer는 model-based fuzzer와 model-less fuzzer 두가지 종류가 있다.
예를 들어, 전통적인 dynamic symbolic execution은 mutation-based fuzzers 에서 처럼 model이 필요하지 않지만 , 일부 symbolic executors 는 입력 문법과 같은 입력 model을 활용하여 symbolic executor를 guide한다.
비록 “Automated whitebox fuzz testing” 등의 많은 whie-box fuzzer들이 test case를 생성하기 위해 dynamic symbolic execution을 사용하지만 모든 white box fuzzer가 dynamic symbolic executors는 아니다.
일부 fuzzer 는 white-box 프로그램을 분석하여 PUT에 넣을 수 있는 입력값에 대한 정보를 찾아 black- or grey-box fuzzing과 함께 사용한다.
-
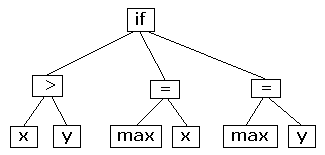
Dynamic symbolic executors 예시
동적 기호 실행 예시 아래 코드를 동적 기호로 표현하면 다음그림과 같다.
x = int(argv[0]) // ➊ y = int(argv[1]) z = x + y // ➋ if(x >= 5) // ➌ foo(x, y, z) y=y+z if(y < x) baz(x, y, z) else qux(x, y, z) else // ➍ bar(x, y, z)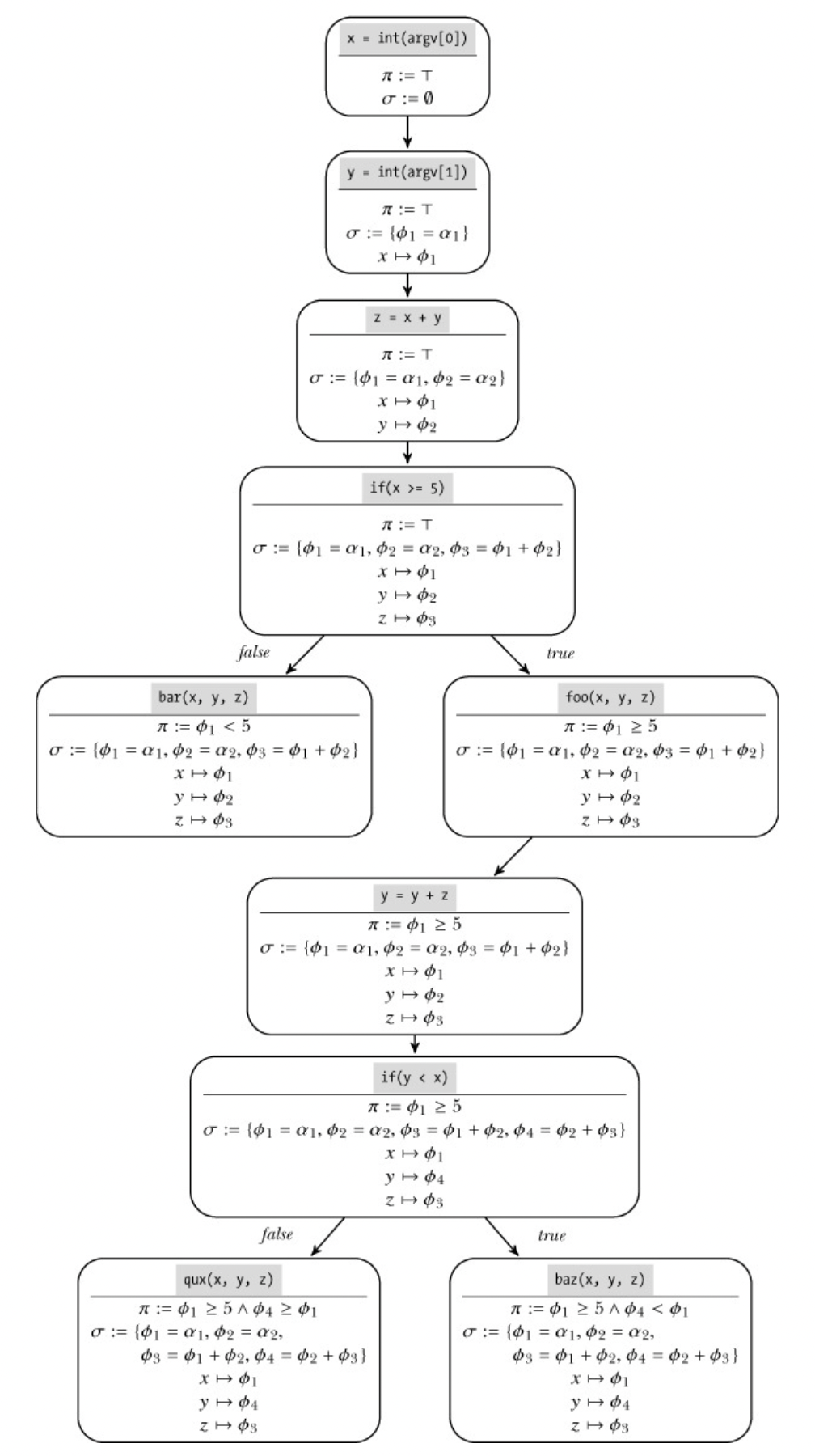
그림에서 경로 제약 조건 π가 동어의 반복인 ⊤으로 초기화되어 있다. 이는 조건 분기와 제약 조건이 없기 때문이다. 기호 표현식 목록 σ도 공집합으로 초기화되어 있다.
그리고 사용자로부터 x와 y 값을 입력받는다➊. 그러면 symbex 엔진이 x 값과 y 값에 대해 ϕ1=α1과ϕ2=α2라는 기호 표현식을 생성한다. 이는 구체적인 값으로 표현될 수 있는 제한 없는 기호 값(unconstrained symbolic value)으로 나타낸 것이며 각각 x, y에 연계된다.
이후 z = x + y 연산이 수행되면➋, symbex 엔진은 z값을 ϕ3=ϕ1+ϕ2로 표기한다.
symbex 엔진이 if(x >= 5)가 참인 경우를 먼저 진행한다고 해보자➌. 이를 위해 π에 ϕ1≥5을 추가해야 하고, 그 결과 foo 함수를 호출하게 된다. 이제 foo 함수를 호출하는 조건을 찾았으므로 기호 표현식과 branch constraint를 만족하는 구체적인 x와 y 값을 찾아야 한다.
현재 x와 y값은 각각 기호 표현식으로 ϕ1=α1 및 ϕ2=α2로 연계되어 있고, branch constraint는α1≥5 하나만 존재한다. 이때 가능한 foo 함수를 호출할 수 있는 해답(solution) 중 α1=5 ∧ α2=0가 있다. 이때 경로 제약 조건상α2 값과 관련된 기호 표현식이 없었으므로 α2는 어떤 값이든 상관 없다.
이렇게 찾아낸 solution을 모델(model)이라고 한다. 제약 조건 풀이기(constraint solver)를 사용하면 제약 조건 및 기호 표현식을 만족하는 기호 값을 찾아 모델을 계산할 수 있다.
5.3.1 Dynamic Symbolic Execution
high level에서 고전적 symbolic execution 은 가능한 모든 값을 나타내는 symbolic 값을 입력으로 하는 프로그램을 실행한다. PUT를 실행할 때 입력값에 대한 결과가 어땠는지 평가하기 보다는 기호 표현식 (symbolic expressions.)을 구축하는 것이 목적이다. ⇒ 코드가 공개 안되어있을때
조건부 분기 명령에 도달할 때마다 개념적으로 두 개의 symbolic interpreter(해석기)를 포크(forks)한다. 모든 경로에 대해, symbolic interpreter(해석기)는 실행 중에 접하는 모든 분기 명령어에 대한 경로 공식(또는 경로 술어, path predicate)을 만든다. 만약 원하는 경로(분기)를 실행하는 구체적인 입력값이 있다면 경로 공식은 만족스럽게 형성된다..
⇒ 분기에 대해 어떤 입력이 들어오면 어떤 분기로 가는지 파악하면 굿.
특히 SMT solver에 경로 공식에 대한 솔루션을 쿼리하여 구체적인 입력값을 생성할 수 있다.
dynamic symbolic execution은 symbolic execution과 구체적인 실행이 동시에 작동하는 전통적인 symbolic execution의 변형이다. 따라서 우리는 종종 symbolic execution을 concolic(concrete + symbolic) test라고 한다. 핵심은 구체적인 실행 상태가 symbolic 제약의 복잡성을 줄이는 데 도움이 될 수 있다는 것이다.
⇒ 어느 조건 달성해야지만 특정 커버리지 실행
⇒ 따라서 직접 실행(구체적)해보면서 symbolic 제약이 너무 복잡해지는 것을 방지?
dynamic symbolic execution의 단점을 보완하기 위한 노력
dynamic symbolic execution은 PUT의 모든 명령을 instrumenting하고 분석하기 때문에 grey-box 또는 black-box 접근법에 비해 느리다. 그래서 속도의 단점을 보완하기위해 사용자가 코드에서 취약점이 안나올 것 같은 부분을 지정하도록 하거나 concolic 테스트와 grey-box fuzzing을 번갈아 가며 사용하는 방법을 사용한다. “Driller : Augmenting fuzzing through selective symbolic execution”과 “The past, present, and future of cyberdyne”은 DARPA Cyber Grand Challenge에서 이 기술이 얼마나 유용한지 보여주었다.
“QSYM:A practical concolic execution engine tailored for hybrid fuzzing” 은 빠른 concolic 실행 엔진을 구현하여 grey-box fuzzing과 white-box fuzzing 간의 통합을 향상시키고자 했다.
“Send hardest problems my way: Probabilistic path prioritization for hybrid fuzzing”은 먼저 grey-box fuzzing을 사용하여 각 경로를 실행할 확률을 추정한 다음 white-box fuzzing이 grey-box fuzzing으로 하기에는 어렵다고 생각되는 경로에 초점을 맞춤으로써 grey-box fuzzing과 white-box fuzzing 전환 과정을 최적화했다.
5.3.2 Guided Fuzzing
일부 fuzzer는 fuzzing의 효과를 높이기 위해 정적 또는 동적 프로그램 분석 기술을 활용한다. 이러한 기법은 일반적으로
(i) PUT에 대한 유용한 정보를 얻기 위한 비용이 많이 드는 프로그램 분석
(ii) (i)의 분석을 기반으로 test case 생성
의 두 가지 단계의 fuzzing을 진행한다.
예를 들어 “TaintScope : A checksum-aware directed fuzzing tool for automatic software vulnerability detection”은 fine-grained taint analysis를 사용하여 중요한 system call 또는 API call로 진행되는 입력 바이트인 "Hot Byte"를 찾는다.
그런 다음 taint analysis을 통해 입력 바이트와 후보 loop문 사이의 관계를 찾는다. 마지막으로, Dowser는 dynamic symbolic execution 을 실행하면서 중요한 바이트만 symbol 로 만들어 성능을 향상시킨다.
→ (fine-grained는 세세하게 오염시키는 방식, taint anlaysis 방식은 프로그램의 메모리에 taint라는 특정 값을 삽입한 후 이 값을 추적하여 그 값이 어떤 영향을 미치는지 관찰하는 것 .예를들어 객체 X를 오염시켰는데 이로 인해 객체 Y가 파생되면 객체 X가 객체Y를 오염시켰다고 말함)
“VUzzer:Application-aware evolutionary fuzzing”및”GRT: Program-analysis-guided random testing”은 정적 및 동적 분석 기술을 모두 활용하여 PUT에서 제어 및 데이터 흐름 기능을 추출하고 이를 사용하여 입력값을 만든다.
“Angora : Efficient fuzzing by principled search”와 “RedQueen:Fuzzing with input-to-state correspondence”은 비용이 많이 드는 instrumentation로 각 seed별로 먼저 실행하고 이 정보를 사용하여 가벼운 instrumentation로 실행되는 입력을 생성함으로써 분석에 드는 비용을 줄인다.
Angora는 taint analysis 을 사용하여 각 경로 제약 조건을 해당 바이트와 연관시킴으로써 "hot bytes" 아이디어를 발전시켰다. 그런 다음 경사하강법 알고리즘(gradient descent algorithm, 변화율 감소, 절댓값이 작아지도록 계속해서 탐색하는 알고리즘)을 응용한 검색을 하는 방식으로 이러한 제약 조건을 해결하는 방향으로 mutation를 유도한다.
반면, RedQueen은 모든 비교를 instrumenting하고 피연산자와 주어진 입력값 사이의 대응성을 찾아 PUT에서 입력이 어떻게 사용되는지 탐지하려고 한다. 일치하는 항목이 발견되면 제약 조건을 해결하는 데 사용한다.
5.3.3 PUT Mutation
파싱 전 checksum을 계산할 때 많은 test case가 통과를 못하기 때문에 fuzzing에서는 checksum 검증을 우회하는 것이 중요하다.
그래서 “TaintScope:A checksum-aware directed fuzzing tool for autoatic software vulnerability detection” 는 taint analysis으로 checksum 테스트 명령을 식별하고 PUT를 패치하여 checksum 검증을 우회하는 checksum 인식 fuzzing 기법을 제안했다. 프로그램 crash를 발견하면, 원본 PUT를 crash시키는 test case 를 생성하기 위해 input에 대한 정확한 checksum을 생성한다.
“Input generation via decomposition and re-stitching: Finding bugs in malware”는 cehcksum이 있는 상태에서 test case를 생성할 수 있는 stitched dynamic symbolic execution이라고 하는 기술을 제안했다.
T-Fuzz:Fuzzing by program transformation” 는 grey-box fuzzing을 통해 모든 종류의 조건부 branch들을 효율적으로 관통(침투)하도록 이 아이디어를 확장한다.
먼저 프로그램 로직을 수정하지 않고 변환할 수 있는 분기인 NCC(Non-Critical Checks) 세트를 만든다. fuzzing 캠페인이 새 경로 탐색을 중지하면 NCC를 선택하여 변환한 다음 수정된 PUT에서 fuzzing 캠페인을 다시 시작한다. 마지막으로, 변환된 프로그램을 fuzz하는 crash가 발견되면, T-Fuzz는 symbolic execution을 사용하여 원본 PUT에서 재구성한다.
-
T-Fuzz의 CrashAnalyzer Readme
-
변형된 프로그램을 퍼저로 찾은 인풋값을 넣어서 실행시킴
-
이 변형된 프로그램에서 입력값을 recover(찾아내고) input 크래시 시킴.
-
결과값이 저장됨(recover_0) 이걸 이용해서 원본 프로그램을 크래시 할것임.
-
생성된 입력값을 통해서(recover_0) 잘 찾았는지 검증함.
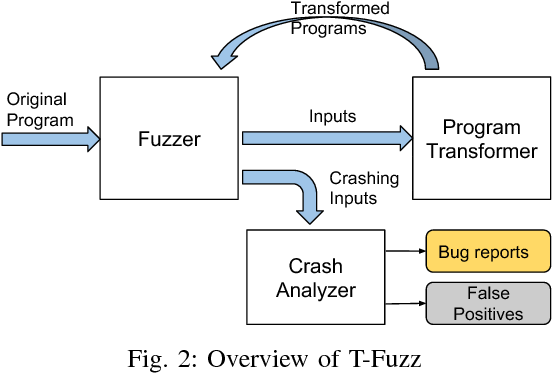
https://zzm7000.github.io/teaching/2021springcse703/papers/08418632.pdf
-
T-Fuzz가 존재하는 coveraged guided 퍼저를 이용해서 입력값을 생성하고 이 생성된 입력값이 어떤 경로를 통해 실행이 되는지(상태) 계속해서 분석, stuck(추가 적인 정보 갱신이 안될때 까지)
-
fuzzer가 stuck(추가적인 정보 갱신이 안되면)T-Fuzzer는 프로그램 변형기를 이용해 변형된 프로그램을 만듬. NCC후보를 찾고 특정 NCC 후보를 제거해 프로그램을 변환함.
-
