모두가 다 한 번쯤은 해봤다는 크롤링! 크롤링이 어떻게 작동하는지는 알고 있었지만 내가 자발적으로 크롤링을 해 본 적은 없었는데 이번에 도전해보기로 했다.
나는 도라에몽을 아주 좋아하기 때문에 구글에서 도라에몽 이미지를 크롤링해오려고 한다. 이용할 툴은 Selenium이다.
# 필요한 라이브러리 불러오기
from selenium import webdriver
from urllib.request import urlopen
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
import os내 노트북에는 셀레니움이 이미 설치되어 있다. 만약 설치되어 있지 않다면
!pip install selenium을 통해 설치해주면 되겠다.
# 1. 이미지 저장할 폴더 생성
if not os.path.isdir("도라에몽/"):
os.makedirs("도라에몽/")현재 폴더에 온갖 사진이 저장되는 것을 막기 위해 제일 먼저 새로운 폴더를 하나 생성해준다. 도라에몽 사진이기 때문에 폴더 이름도 도라에몽으로 해주었다.
# 2. 크롬 웹드라이버 연결
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
크롬 웹 드라이버 다운로드 링크:
https://chromedriver.chromium.org/downloads
다음으로는 드라이버다. 크롬을 이용할 것이기 때문에 크롬 웹드라이버를 코드를 작성하는 곳과 같은 디렉토리에 넣어주어서 경로를 써줄 필요를 덜었다. 드라이버를 설치할 때에는 반드시 내 크롬 버전과 같은 버전으로 설치해주도록 하자. 경로가 다른 곳이라면 webdriver.Chrome("드라이버 경로") 로 경로를 명시해주면 된다. 그리고 바로 구글 이미지 검색 페이지로 이동할 수 있도록 get() 안에 이미지 검색 링크를 넣어주었다.
# 3. 검색어 입력하기
search = "도라에몽"
elem = driver.find_element_by_name("q")
elem.send_keys(search)
elem.send_keys(Keys.RETURN)search라는 변수에 "도라에몽"을 넣어주면 나중에 search 변수 변경만으로 크롤링해올 이미지를 변경할 수 있게 된다.
find_element_by_name에 "q"를 넣어주는 것은 검색창을 찾는 것이다. 검색창을 찾고 search 키워드를 넣어준다는 의미가 되겠다. 그리고 Keys.RETURN을 통해 엔터를 쳐준다.
# 4. 스크롤 끝까지 내리기
SCROLL_PAUSE_TIME = 1
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height이 부분은 구글 이미지 검색이 스크롤을 내리면 계속 새로운 스크롤이 갱신된다는 특성을 이용해 작성되는 부분이다. 구글 이미지 검색을 해보면 scrollHeight이 끝나는 지점에 다다랐을 때 "결과 더보기" 버튼이 생성되는데 그 버튼을 찾으면 누르고, 아닐 경우 스크롤 내리기를 멈추게 된다.
# 5. 이미지 찾아서 원본 파일로 저장하기
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
count = 1
for image in images:
try:
image.click()
time.sleep(2)
imgUrl = driver.find_element_by_xpath("//*[@id='Sva75c']/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div/a/img").get_attribute('src')
urllib.request.urlretrieve(imgUrl, "도라에몽/" + search + "_" + str(count) + ".jpg")
print("Image saved: 도라에몽_{}.jpg".format(count))
count += 1
except:
pass
driver.close()먼저 이미지 썸네일을 찾아낸다. 그 썸네일을 일일이 클릭해 원본 이미지로 저장하는 코드가 되겠다. time.sleep(2)는 클릭하고 나서 이미지가 로딩되는 경우에 대비해 2초 정도 기다릴 수 있도록 해준다. 그리고 이미지를 클릭했을 때 xpath에 붙어있는 src(소스) 정보를 가져오도록 한다.
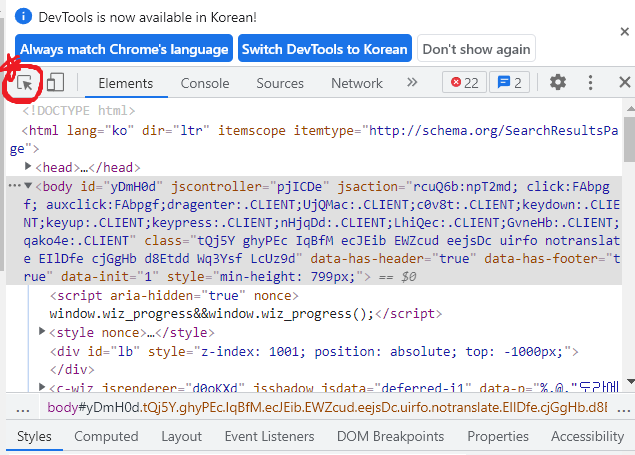
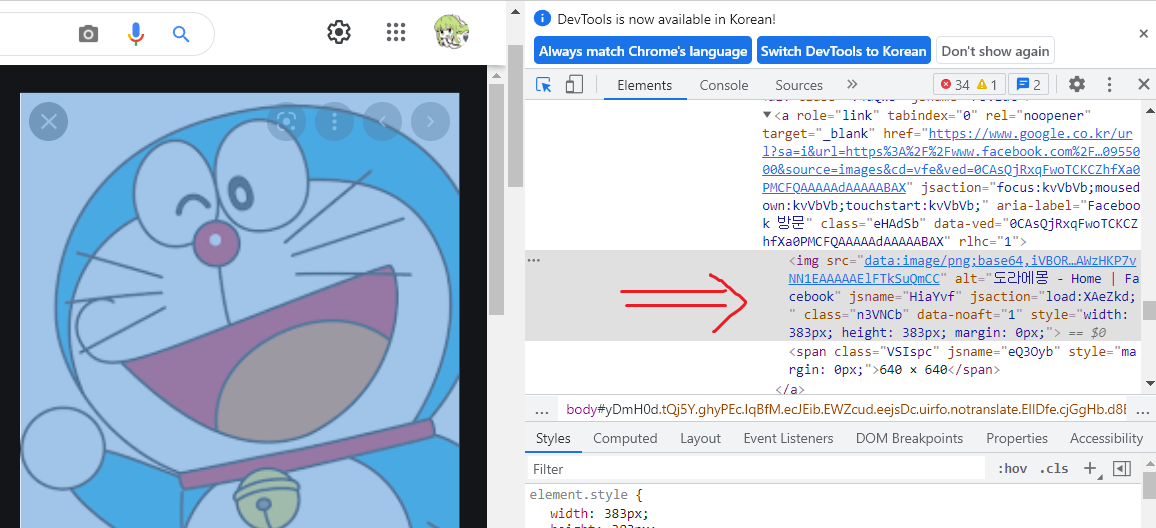
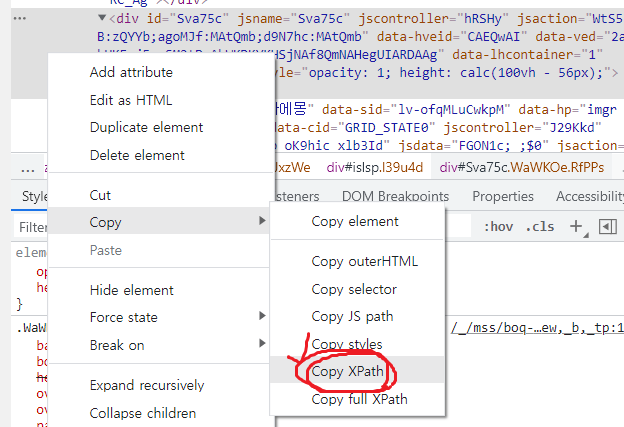
xpath는 F12를 눌러 개발자 도구를 켠 다음 빨간 동그라미를 친 버튼을 누르고 이미지를 클릭하면 해당 이미지의 코드로 이동하게 된다. 그 코드에 대고 마우스 오른쪽 버튼을 눌러 copy -> xpath를 눌러주면 쉽게 복사할 수 있다. 복사된 xpath를 find_element_by_xpath() 안에 넣어주면 된다.
- xpath 복사하기
그렇게 가져온 정보를 가지고 이미지로 저장하면 되는데 저장하는 이름을 urlretrieve에 값을 넣어 조정해준다. 나의 경우 "도라에몽_n.jpg" 형식으로 저장될 수 있게 설정해주었다. 로드되는 이미지를 모두 저장하면 드라이버를 종료한다. 그러면 끝!
코드를 한 번에 보게 되면 다음과 같다.
from selenium import webdriver
from urllib.request import urlopen
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
import os
if not os.path.isdir("도라에몽/"):
os.makedirs("도라에몽/")
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
search = "도라에몽"
elem = driver.find_element_by_name("q")
elem.send_keys(search)
elem.send_keys(Keys.RETURN)
SCROLL_PAUSE_TIME = 1
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
count = 1
for image in images:
try:
image.click()
time.sleep(2)
imgUrl = driver.find_element_by_xpath("//*[@id='Sva75c']/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div/a/img").get_attribute('src')
urllib.request.urlretrieve(imgUrl, "도라에몽/" + search + "_" + str(count) + ".jpg")
print("Image saved: 도라에몽_{}.jpg".format(count))
count += 1
except:
pass
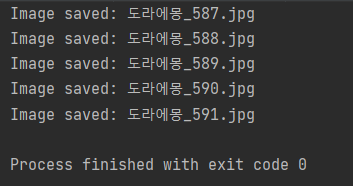
driver.close()작업이 끝나면 exit code 0과 함께 잘 저장된 파일들을 확인할 수 있다.
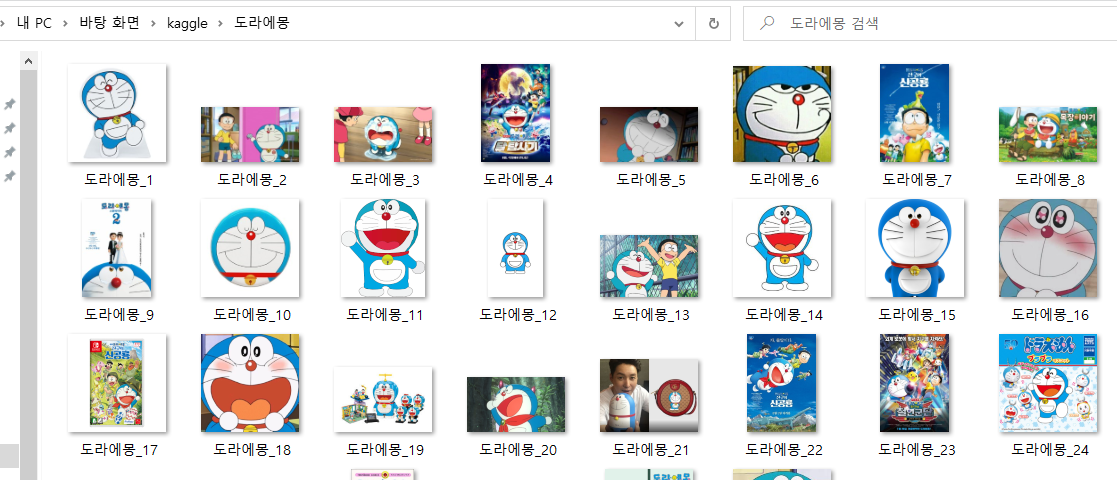
코드를 작성하면서 find_element와 find_elements 때문에 시간을 조금 날렸는데 사진 하나를 클릭할 때는 꼭 element를 써주고 여러 개를 클릭해야 할 때는 elements를 써줘야 한다. 안 그러면 작업이 안 된다!!ㅠㅠㅠㅠ단수 복수 꼭 유의해서 코드를 작성해보기 바란다.
여담이지만 크롤링은 아주 건방진 기법인 것 같다. 어렵지 않으면서도 파이썬 외에 css나 html 지식을 요구한다는 것이 아주...발칙해.......
아무튼! 오늘은 이렇게 이미지 크롤링 방법을 익혀볼 수 있었다. 크롤링은 파이썬 코드 작성보다는 여러 웹사이트들의 css와 html이 어떠한 형식으로 작성되어 있고 src가 어디에 붙어있는지 찾아내는 것이 더 중요한 작업이기 때문에 여러 번 해보는 것이 중요한 공부인 것 같다. 우리 모두 화이팅이다 화이팅~~

좋은 글 감사합니다. 혹시 원본파일명을 살려서 저장하고 싶으면 어떻게 코드를 작성하면 될까요?