Generalized Policy Iteration
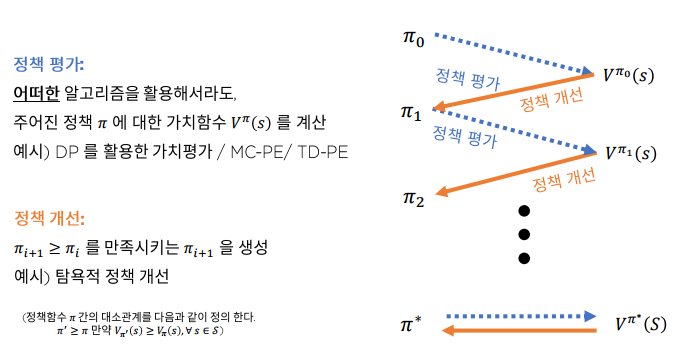
MC policy evaluation + 탐욕적 개선
- 정책 평가 : MC policy evaluation 을 활용해 추산
- 정책 개선 : 탐욕적 정책 개선
탐욕적 정책 개선의 한계
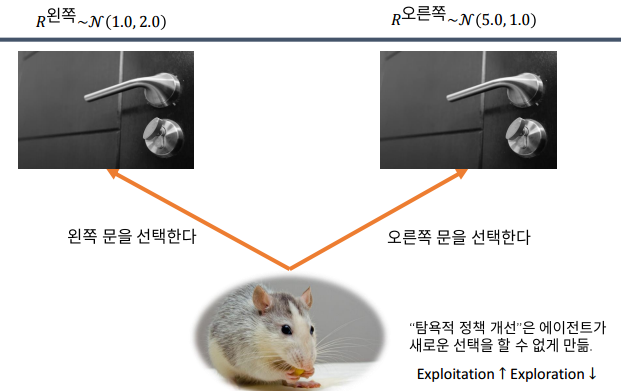
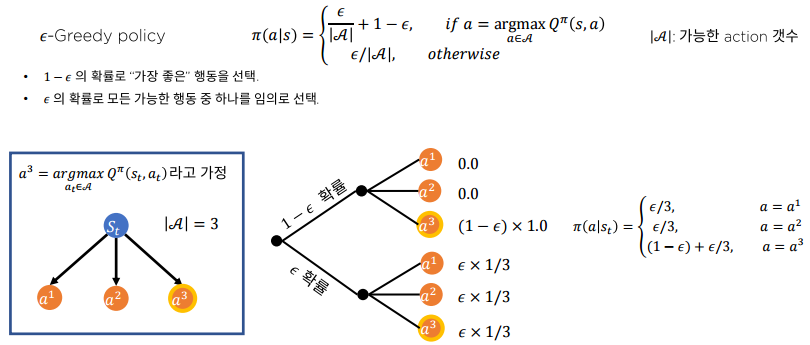
-Greedy policy
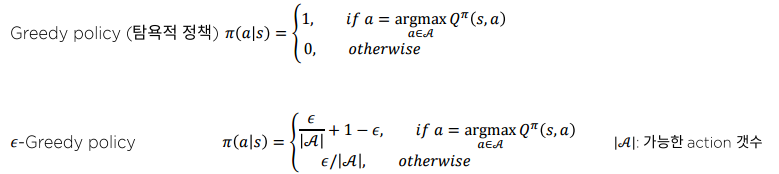
- 1 - 의 확률로 "가장 좋은" 행동을 선택
- 의 확률로 모든 가능한 행동 중 하나를 임의로 선택
-Greedy 정책개선이 정말 "정책개선"인가요?

그림에서 부등식의 성립한다고 가정하면 정책 개선이 이뤄진다고 할 수 있다.
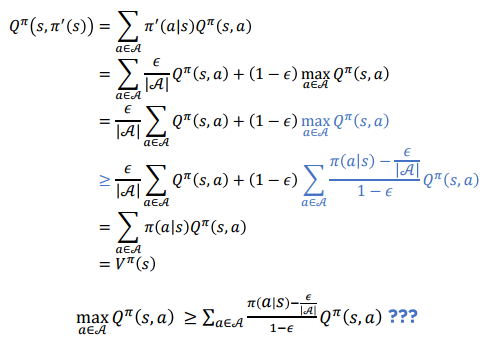
이고, 인 임의의 를 가지고 있다고 했을 때
등호는 일 때 성립.
위 식을 활용해 수식을 푼다면
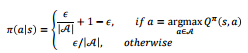
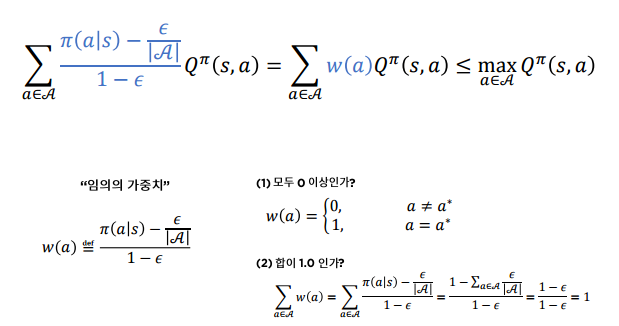
그렇다면 MC policy evaluation 을 활용해 를 추산하고 + -탐욕적 개선을 이용하면 최적 정책을 구할 수 있을까?
GLIE 조건
-탐욕적 정책의 단점
- 의 확률로 임의의 행동을 해야 한다!
그러면 학습 초기에는 상대적으로 높게 하고 학습이 진행됨에 따라서 으로 하면 어떨까?
- 학습이 진행되면 Greedy 정책으로 수렴한다.
- 가능하나 GLIE 조건이 필요함
- GLIE(Greedy in the Limit of Infinite Exploration)
- 모든 이 되도록 를 학습진행에 따라 스케쥴링한다.
- Ex) 는 에피소드 인덱스 (DQN 훈련 시 초기에는 이 1에 가까운 정책을 가지고 데이터를 샘플링 했다가 점진적으로 을 줄여 Greedy 하게 학습)
- GLIE(Greedy in the Limit of Infinite Exploration)
GLIE Monte-Carlo 제어

강화학습은 하이퍼 파라미터와의 싸움
혹은 같이 하이퍼파라미터에 의한 성능 편차가 큼.

You matter, never give up