01. 강화학습의 근간 - 동적계획법
"강화학습 문제"와 "강화학습 문제의 풀이기법"
"강화학습 문제" : MDP
- MDP를 풀었다! = (최적 정책 함수) 를 안다.
- 를 어떻게 찾지? BOE(벨만 최적 방정식)을 풀어보자
- Bellman 최적 방정식은 직접해가 없다!
"강화학습 문제의 풀이기법"
- 환경에 대해서 알 때!
- Dynamic Programming
- 환경에 대해서 모를 때!
- MC(몬테카를로)
- TD
동적 계획법(Dynamic programming:DP)
동적 계획법은 복잡한(큰) 문제를 작은 문제로 나눈 후 작은 문제의 해법을 조합해 큰 문제의 해답을 구하는 기법의 총칭
이름의 유래:1960년대 벨만은 원래 다단계 의사결정 프로세스라고 이름을 붙이고 연구하고 있었으나 당시 공군 소속의 회사는 수학을 연구하는 것을 탐탁치 않게 여겨 몰래 연구하곤 했음. 그래서 이름도 아래와 같은 DP로 정의
- Dynamic : 시간에 대해서 변화, 여러 단계로 나뉘어짐 등을 표현
- Programming : 1950년대 미 공군에서 사용하던 용어
동적 계획법으로 해결할 수 있는 문제는 다음과 같은 특징을 가진다.
1. 최적 하위구조(Optimal substructure)
- 큰 문제를 분할한 작은 문제의 최적 값이 큰 문제에서도 최적 값임
- Principle of optimality 라고도 불림
2. 중복 하위문제(Overlapping problems)
- 큰 문제의 해를 구하기 위해서, 작은 문제의 최적 해를 재사용
- 여러 번의 재사용을 하기 때문에 일반적으로 테이블에 저장해둠
MDP에서 정의한 Bellman 기대/최적 방정식은 두 가지 특성을 만족시킨다.
즉, 우리는 DP를 활용해 Bellman 기대/최적 방정식의 해를 효율적으로 계산할 수 있다.
정책 평가 (Policy evaluatioin: PE)
정책 평가(Policy evaluation)는 반복적인 과정을 통해 'Bellman 기대값 방정식'의 해를 구하는 방법 중 하나.
📌벨만 기대값 방정식은 직접해를 구할 수 있음. 벨만 기대값 방정식 해결을 위해 정공법인 직접해를 사용하지 않고, 새로운 방법으로 하는 이유는 직접해를 사용할 시 역행렬을 계산하는 연산이 가끔씩 불가능한 경우가 있기 때문. MDP의 상태와 행동 공간의 크기가 커졌을 때 역행렬을 계산하는 것 자체가 어려워져 직접적으로 해를 계산하기 어려운 경우가 생김
- 정책 평가 알고리즘
꼭 0이 아니라 어떤 값으로 시작해도 하나의 값으로 알고리즘 결과는 수렴함.
신기...

정책 개선(Policy Improvement: PI)
- 정책 개선 알고리즘

Q) 과연 이렇게 만들어진 가 보다 좋을까?
(즉, 만약 )
정책 개선 정리 (policy improvement theorem)
우리의 정책이 결정적이다 라는 가정 하에 다음이 성립 :


정책 반복(policy iteration)
- 정책 반복(Policy iteration)은 (1) 정책 평가와 (2) 정책 개선을 적용해 Bellman 방정식을 푸는 알고리즘
정책 반복 알고리즘

정책 반복 알고리즘을 활용한 최적 정책계산

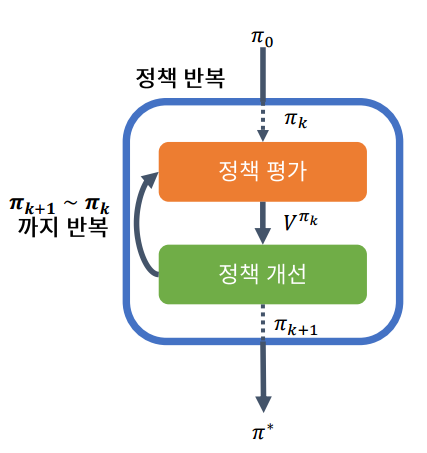
- 정책 개선이라는 알고리즘이 매 반복마다 최소 현재 정책보다 좋거나 같은 가치함수를 출력해준다는 사실 +
- MDP에 최적 정책이 존재한다는 사실
벡터의 크기를 재는 방법 Norm

Bellman expectation backup 오퍼레이터

바나흐 고정점 정리

정책 평가 알고리즘과 바나흐 고정점 정리

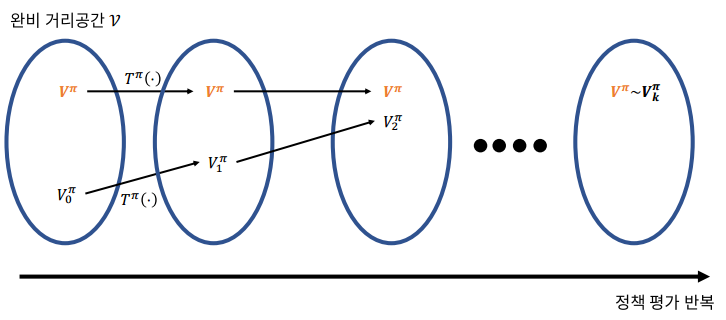
- 임의의 가 우리가 알고 싶어하는 와 같아 짐을 알 수 있다.
정책 평가와 정책 개선 개념 정리
-
정책 평가는 현재 정책이 얼마나 좋은지를 알기 위해 현재 정책을 따를 시 받는 가치 함수를 계산하는 것
-
가치함수를 구하기 위해서 벨만 기대값 방정식의 해를 구함
-
벨만 기대값 방정식의 해를 통해 가치 함수()를 계산
-
현재 정책과 위에서 계산한 가치함수를 활용해
개선된 정책()을 구하는 것을
정책 개선이라고 함. -
정책 평가과 정책 개선을 합쳐 정책 반복이라고 함!
-
정책 반복(정책 평가 + 정책 개선)을 통해 최선의 정책을 구하면 우리는 MDP를 풀었다고 할 수 있음.
def policy_iteration(self, policy=None):
if policy is None:
pi_old = self.policy
else:
pi_old = policy
steps = 0
converged = False
while True:
v_old = self.policy_evaluation(pi_old)
pi_improved = self.policy_improvement(pi_old, v_old)
steps += 1
# check convergence
policy_gap = np.linalg.norm(pi_improved - pi_old)
if policy_gap <= self.error_tol:
if not converged: # record the first moment of within error tolerance
info['converge'] = steps
break
else:
pi_old = pi_improved
return info02. 더 효율적인 DP - 비동기적 동적계획법
굳이 정책 평가가 수렴할 때 까지 반복해야 할까?
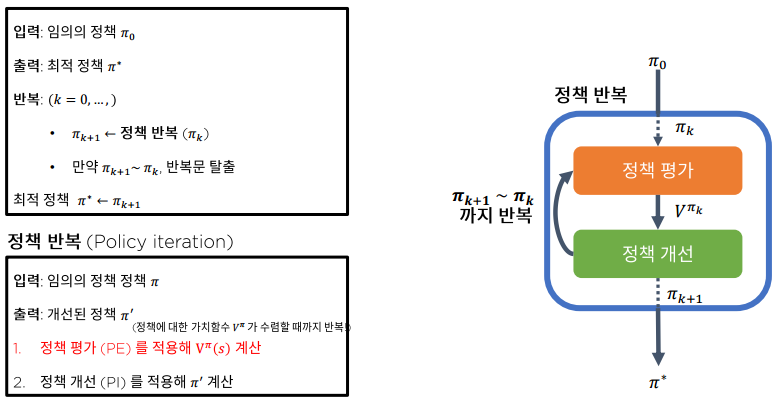
정책 반복 알고리즘 내부에 정책 평가 알고리즘 존재, 정책 평가 알고리즘 내부 while문 존재, 정책 반복 알고리즘 전체에 while문 존재하여 두 개의 while문 수행이 필요함.
한 개의 while 문으로 바꿀 수 없을까? 가능함!
Value iteration!
가치 반복 (Value Iteration: VI)
가치 반복 알고리즘 - 외적으로 policy를 두고 있지 않음.
모델을 알고 있고, 최적 가치를 알고 있으면 모델을 통해서 를 계산할 수 있고 , 에 대해서 greedy policy improvement를 적용하면 최적 정책함수를 계산할 수 있기 때문에 가치 반복 알고리즘을 통해서도 정책을 확인할 수 있음.

def value_iteration(self, v_init=None, compute_pi=False):
if v_init is not None:
v_old = v_init
else:
v_old = np.zeros(self.ns)
while True:
# Bellman optimality backup
v_improved = (self.R.T + self.P.dot(v_old)).max(axis=0) # [num. actions x num states]
info['v'].append(v_improved)
if compute_pi:
# compute policy from v
# 1) Compute v -> q
q_pi = (self.R.T + self.P.dot(v_improved)) # [num. actions num states]
# 2) Construct greedy policy
pi = np.zeros_like(self.policy)
pi[np.arange(q_pi.shape[1]), q_pi.argmax(axis=0)] = 1
info['pi'].append(pi)
steps += 1
# check congergence
value_gap = np.linalg.norm(v_improved - v_old)
if value_gap <= self.error_tol:
if not converged:
info['converge'] = steps
break
else:
v_old = v_improved
return info벨만 최적 오퍼레이터 (Bellman Optimality backup) 은 수축 사상이므로 "바나흐 고정점 정리"에 의해 VI는 유일한 해 로 수렴한다.
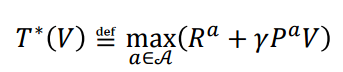
동기적 DP 알고리즘
- 정책 평가 알고리즘 : 새로운 정책 평가를 위해서 기존의 정책 값을 알고 있어야 하고, 새로운 정책 값을 메모리에 저장해야 됨.
- 가치 반복 알고리즘 : 기존 스탭의 를 알고 있어야 되고 이를 이용해 를 만들 수 있음.
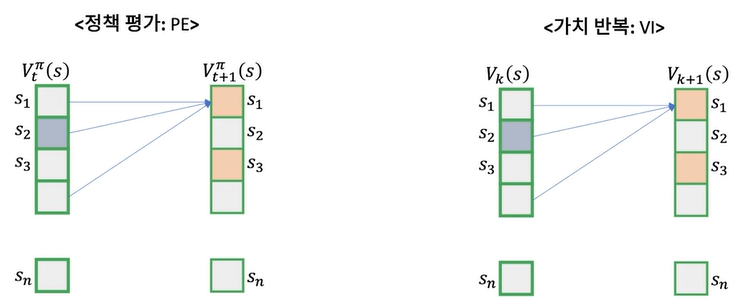
- 문제점
- 메모리에 항상 전체 상태 개수의 2배인 테이블을 저장해야됨.
- 차후에 학습기반으로 DP를 풀려고 할 때 서로 다른 두 개의 함수를 학습해야 하므로 학습에 관련된 모든 것들을 2배로 관리해야 됨
학습 속도가 느려짐 (Ex. 바둑의 경우 )
비동기적 DP 알고리즘이 필요함.
비동기적 DP 알고리즘 (Asynchronous DP)
여러가지 비동기적 DP 알고리즘이 존재하지만, 세 가지 알고리즘을 설명
비동기적 DP 알고리즘을 사용할 때 일반적으로 각 에 대해 임의의 순차적으로 진행함.
- In-place DP
- Prioritized sweeping
- Real-time DP
세 알고리즘은 PE/VI의 수렴성을 해치지 않는 것으로 증명됨.
세 가지 알고리즘은 <심층 강화학습 알고리즘>의 빠른 수렴을 유도하기 위해서도 사용됨
In-place DP
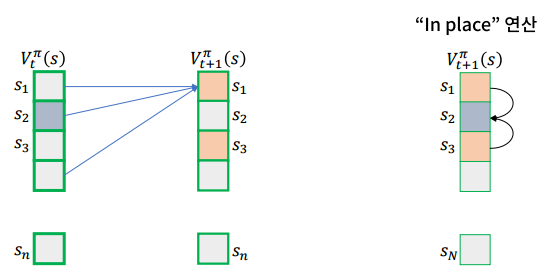
그림과 같이 현재 알고 있는 가장 새로운 값 을 활용해 들을 업데이트 한다.
- 최대 전체 상태 공간만 있으면 됨.(메모리 절감)
- 일반적으로 수렴 속도가 더 빠름
- 구현하기 쉬움
Prioritized sweeping
- Bellman error의 크기가 가장 큰 부터 업데이트 한다.
- Bellman error() =
- PE/VI의 수렴속도가 빨라짐
Real-time DP
- 강화학습의 에이전트가 현재 겪은 상황만 업데이트 하자!
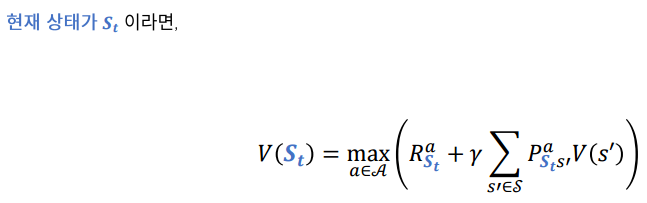
DP 정리하기

MDP 푼다 : 최적 가치 함수 및 최적 정책을 찾는 것
DP 기법을 활용
1. 정책 반복 알고리즘 활용
- 정책 평가 + 정책 개선을 반복적으로 활용
- 가치 반복 알고리즘
- 위의 정책 평가 while문과 외부 정책 개선 while문을 합쳐서 더 빠른 가치 반복 알고리즘으로 활용
- 비동기적 DP(비동기적 가치 반복)
- 가치 반복 알고리즘의 메모리 효율적인 구조로 비동기적 가치 반복 알고리즘을 활용
비동기적 DP 실습
class AsyncDP:
def __init__(self, gamma=1.0, error_tol=1e-5):
self.gamma = gamma
self.error_tol = error.tol
...Full sweeping
이전의 정책평가 (policy evaluation), 가치반복 (value iteration)은 모두 매 반복마다 모든 및 에 대해서 업데이트를 했음.
이처럼 모든 및 에 대해서 업데이트 해주는 방식을 Full sweeping 이라고 부름.
In-place value iteration
In-place value iteration은 하나의 value function array만을 가지고 가치 반복 알고리즘을 수행함. 하나의 value function 만을 가지고도 true/optimal value function을 추산하는 In-place method는 최적 가치함수에 수렴한다는 것이 알려져 있음.
✍엄밀히 말해서는 수렴하기 위해 '적절한 조건'이 필요함.

Value iteration은 와 을 유지하고, 를 계산하기 위해 을 참조한다.
In-place value iteration은 만을 유지하고, 을 계산할 때 를 참조한다.
def in_place_vi(self, v_init=None):
"""
:param v_init: (np.array) initial value 'guesstimation' (optional)
:return:
"""
if v_init is not None:
value = v_init
else:
value = np.zeros(self.ns)
info = dict()
info['v'] = list()
info['pi'] = list()
info['converge'] = None
info['gap'] = list()
steps = 0
# loop over value iteration:
# perform the loop until the value estimates are converge
while True:
# loop over states:
# we perform 'sweeping' over states in "any arbitrary" order.
# without-loss-of-generality, we can perform as the order of states.
# in this example, we consider the "full sweeping" of values.
# perform in-place VI
delta_v = 0
info['v'].append(value)
pi = self.construct_policy_from_v(value)
info['pi'].append(pi)
for s in range(self.ns):
# Bellman expectation backup of current state in in-place fashion
# get Q values of given state 's'
# output of 'self.compute_q_from_v(value)' is a tensor
# with the shape of [num. actions X num. states].
qs = self.compute_q_from_v(value)[:, s]
v = qs.max(axis=0) # get max value along the actions
# accumulate the deviation from the current state s
# the deviation = |v_new - v|
delta_v += np.linalg.norm(value[s] - v)
value[s] = v
info['gap'].append(delta_v)
if delta_v < self.error_tol:
info['converge'] = steps
break
else:
steps += 1
return infoPrioritized sweeping value iteration
Prioritized sweeping = 우선순위를 준 (Prioritized) + 가치 함수 값 업데이트 하기(value iteration)
In-place value iteration에서는 임의의 순서 (위에선 환경의 인덱스 순서)로 가치 함수를 업데이트하였음.
임의의 순서에 대해서 알고리즘이 수렴하니, 혹시 좀 더 좋은 가치 함수 업데이트 순서가 없을까?
Prioritized sweeping은 "Bellman error의 크기에 비례하는 순서대로 상태 가치함수를 업데이트하자" Bellman error는 아래와 같음
def prioritized_sweeping_vi(self, v_init=None):
"""
:param v_init: (np.array) initial value 'guesstimation' (optional)
:return:
"""
if v_init is not None:
value = v_init
else:
value = np.zeros(self.ns)
info = dict()
info['v'] = list()
info['pi'] = list()
info['converge'] = None
info['gap'] = list()
steps = 0
while True:
# compute the Bellman errors
# bellman_errors shape : [num.states]
bellman_errors = value - (self.R.T + self.P.dot(value)).max(axis=0)
state_indices = range(self.ns)
# put the (bellman error, state index) into the priority queue
priority_queue = PriorityQueue()
for bellman_error, s_idx in zip(bellman_errors, state_indices):
priority_queue.put((-bellman_error, s_idx))
#이후 get 메서드를 통해 우선순위값이 낮은 순서부터 리턴하므로 에러가 높은 순서부터 뽑기 위해서 -(마이너스)를 붙임
info['v'].append(value)
pi = self.construct_policy_from_v(value)
info['pi'].append(pi)
delta_v = 0
while not priority_queue.empty():
be, s = priority_queue.get()
qs = self.compute_q_from_v(value)[:, s]
v = qs.max(axis=0) # get max value along the actions
delta_v += np.linalg.norm(value[s] - v)
value[s] = v
info['gap'].append(delta_v)
if delta_v < self.error_tol:
info['converge'] = steps
break
else:
steps += 1
return infoPartial Sweeping Value Iteration
Full sweeping은 상당히 비현실적
RL알고리즘들은 DP의 Policy evaluation, Policy iteration, Value iteration 들을 환경과의 상호작용을 통해 얻은 sameple로 근사적으로 수행합니다. 따라서 RL 알고리즘의 관점에서 Full sweeping 은 매우 비현실적인 상황이 됨.
- RL 알고리즘이 Full sweeping을 하려면 매번 엄청난 수의 샘플이 필요하며, 추가적으로 매 가치평가마다 모든 및 를 방문한다는 가정도 필요함
- 그렇다면, 매 가치반복의 알고리즘의 스텝마다 모든 를 업데이트 하지 않아도 비동기적 가치반복 알고리즘은 수렴할까?
- "특정 조건" 이 맞춰지면, 모든 를 업데이트 하지 않아도 비동기적 가치반복 알고리즘은 수렴! "특정 조건" 은 간략하게 말하면, "모든 가치반복 업데이트동안에, 모든 가 업데이트 된다" 입니다.
Partial sweeping 에서는 모든 가치반복 업데이트 중에서, 모든 를 업데이트 하는 조건을 만족시킨다
"새로운 메서드
in_place_vi_partial_update()는update_prob,vi_iters를 인자로 받습니다.
update_prob는 한 가치반복 업데이트 동안에 얼마의 확률로 state를 업데이트할지를 결정하는 인자입니다. 예를 들어update_prob=1.0이 되면, 모든 를 업데이트하게 됩니다. 혹은update_prob=0.1을 주게되면 전체 중 대략적으로 10% 에 해당하는 들만 업데이트하게 됩니다.
vi_iters는 몇 번의 가치반복 업데이트를 수행할지에 대한 인자입니다. 기존의 VI들은 수렴할때까지 반복했지만, 이번 경우는 외부적으로 반복 횟수를 설정할 수 있게 함.
def in_place_vi_partial_update(self,
v_init=None,
update_prob=0.5,
vi_iters: int = 100):
"""
:param v_init: (np.array) initial value 'guesstimation' (optional)
:return:
"""
if v_init is not None:
value = v_init
else:
value = np.zeros(self.ns)
info = dict()
info['v'] = list()
info['pi'] = list()
info['gap'] = list()
# loop over value iteration:
# perform the loop until the value estimates are converge
for steps in range(vi_iters):
# loop over states:
# we perform 'sweeping' over states in "any arbitrary" order.
# without-loss-of-generality, we can perform as the order of states.
# in this example, we consider the "full sweeping" of values.
# perform in-place VI
delta_v = 0
for s in range(self.ns):
perform_update = np.random.binomial(size=1, n=1, p=update_prob)
if not perform_update:
continue
# Bellman expectation backup of current state in in-place fashion
# get Q values of given state 's'
qs = self.compute_q_from_v(value)[:, s]
v = qs.max(axis=0) # get max value along the actions
# accumulate the deviation from the current state s
# the deviation = |v_new - v|
delta_v += np.linalg.norm(value[s] - v)
value[s] = v
info['gap'].append(delta_v)
info['v'].append(value.copy())
pi = self.construct_policy_from_v(value)
info['pi'].append(pi)
return info