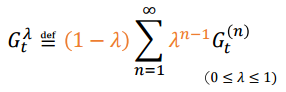Ch03. 모델없이 세상 알아가기
01. 도박의 도시 몬테카를로(MC) 그리고 MC 정책 추정
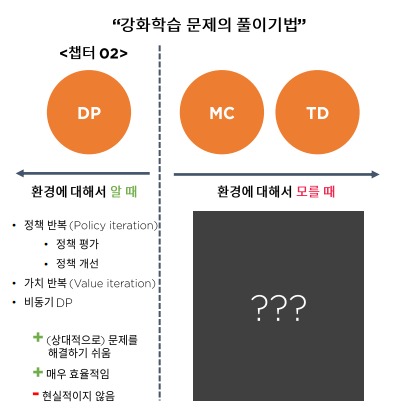
강화학습의 풀이기법
이전까지는 환경에 대해서 알 때를 가정하고 DP를 통해 강화학습 풀이법에 대해서 공부했고,
이번 부터는 환경에 대해서 모르는 조금 현실적인 문제의 풀이법에 대해서 공부
보상함수 와 상태 천이 확률 을 모르는 상황을 model을 모른다고 할 수 있다.
강화"학습"
이전까지는 DP를 통해 계산을 통해 강화학습을 풀었지 특별히 "학습"이라고 부를만한 이유는 없었음. 실제 현실에서 학습이라면 현재 지식이 없기 때문에, 환경과 상호작용을 통해 가치함수 및 정책 혹은 환경의 모델을 추산하는 것을 의미함.
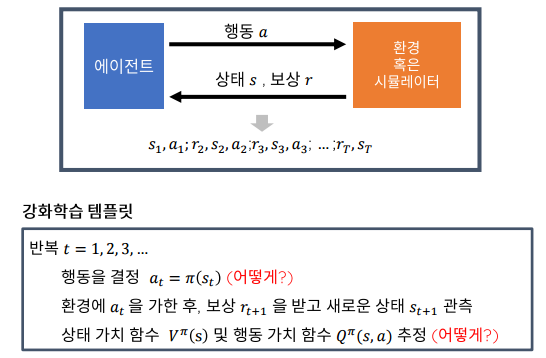
강화학습의 템플릿
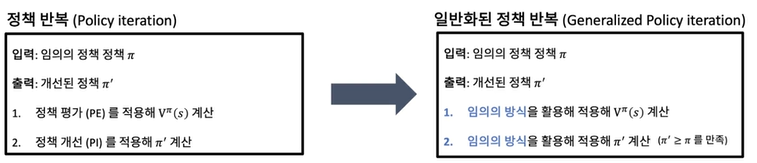
Generalized Policy Iteration
이전에 배운 정책 반복 알고리즘에서는 정책 평가, 정책 개선 알고리즘을 활용했다면 일반화된 정책 반복은, 임의의 방식을 활용, 적용해 와 을 계산한다.
- 어떻게 가치를 평가할 것인가?
- 어떻게 정책을 개선할 것인가?
Model-free 가치 추산 알고리즘의 분류
- 가치 평가 시 데이터에만 의존하는가, 혹은
- 자신이 현재까지 알고 있는 가치함수를 데이터와 함께 가치함수를 추산하는 데 사용하느냐에 따라서 나뉨

현재의 상태가 다음 상태에 영향을 주는 경우 Bootstrap ~ 신발 끈을 묶을 때 아래의 끈 묶음이 위에도 영향을 미침
몬테 카를로 (Monte Carlo)
몬테 카를로 기법: 계산하기 어려운 값을 수 많은 확률 시행을 거쳐 추산하는 기법
몬테카를로 기법을 활용한 가치 함수 추산
목적 : 주어진 정책 에 대해서, 를 추산
는 확률 변수로 "에피소드"가 끝나는 시점
몬테카를로 기법
를 여러 번 시뮬레이션해서 그 시뮬레이션 값의 평균을 계산하면 과 비슷해진다!
수학적 특성
- MC는 불편추정기법(편향X)이기 때문에 시뮬레이셔 횟수가 늘어나면 그 추정치가 참 값과 같아진다.
- MC 시뮬레이션의 횟수가 늘어나면 추정치의 분산이 줄어든다 (=시뮬레이션 횟수가 적으면 추정치의 불확실성이 증가)
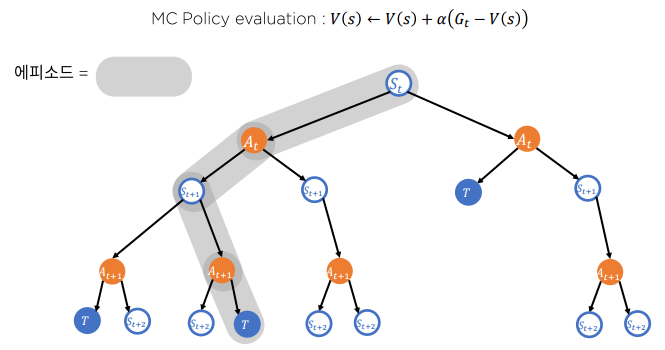
최초 방문 몬테 카를로 정책 추정(First-visit Monte Carlo policy evaluation)
3개의 상태 공간과 3개의 행동 공간 가정
에피소드 내 방문한 첫 번째 에 대해서만 리턴을 계산
오른쪽 아래 수식 notation 오타 (x) (o)

모든 방문 몬테 카를로 정책 추정
에피소드 내 방문한 모든 에 대해서 리턴을 계산

둘중에 맞는 것은? 수학적으로는 둘 다 유효한 알고리즘, 현실에서는 모든 방문 MC가 더 선호됨.
만약, 계속적으로 새로운 데이터가 생긴다면?
그림과 같이 에피소드 에서 끝나는 것이 아니라 계속 데이터가 생성된다면, 기존의 모든 리턴 값()들을 계속해서 메모리에 쌓아 두어야됨.
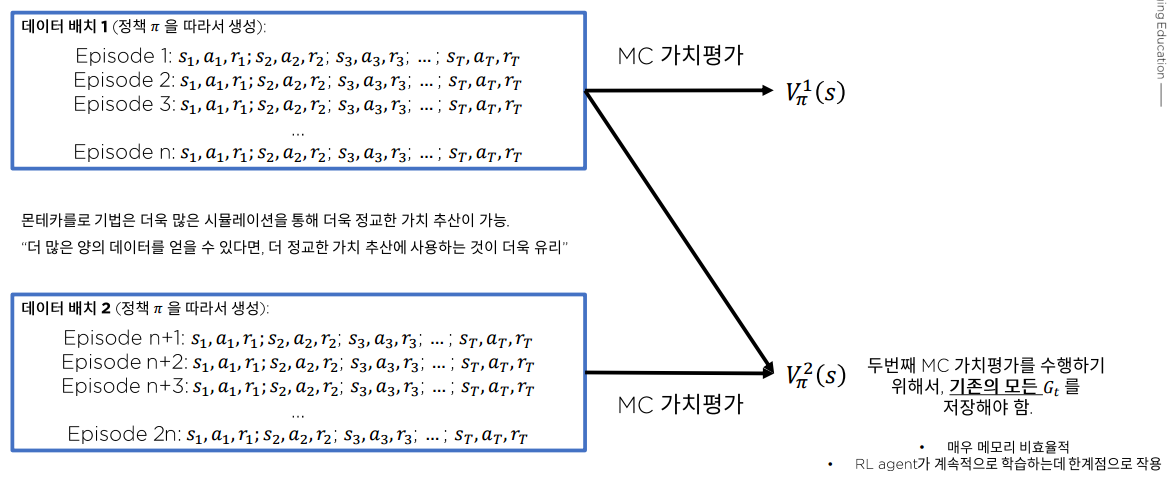
배치 산술평균을 온라인 평균기법으로 변환


Incremental MC policy evaluation

세번째 수식은 엄밀하기 보단 기능적인 면에서 잘 활용됨.
(1) A stochastic Approximation Method, Herbert Robbins, Sutton Monro
MC를 활용한 행동 가치함수 추산
상태 가치 함수 만으로는 (탐욕적) 정책 개선을 수행할 수 없다. 따라서, 행동 가치 함수 를 추산하는 것이 필요하다.
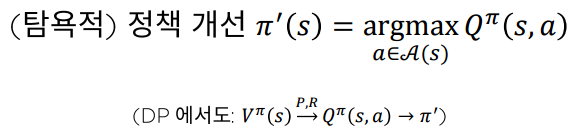

Monte Carlo Policy Evaluation
장점:
- 환경에 대한 선험적 지식이 필요 없음
- 직관적이고 구현하기 쉬움
- 항상 정확한 가치 함수 값을 계산함 (MC PE는 Value function의 unbiased estimator)
단점:
- (엄밀하게는) Episode가 끝나야만 적용 가능
- 무한한 길이의 episode에 대해서도, 리턴 계산에서 충분히 작은 미래의 보상들을 무시하면 사용 가능. 하지만 불편 추정치의 특성을 잃게 됨
- DP와는 다르게 각 상태와 행동의 관계에 대해서 전혀 활용하지 않음
- DP 가 각 상태/행동이 다음 상태에 영향을 미친다는 점을 활용해 계산량을 줄인 것 고려
- 정확한 값을 얻기 위해 많은 시뮬레이션을 필요로 함(일반적으로 수렴속도가 느림)
DP와 MC 기법의 장단점
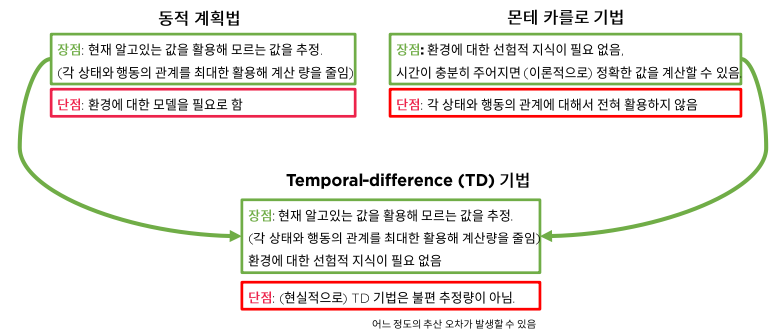
Temporal-Diffenrece 기법은 동적계획법과 같이 현재 알고 있는 값을 활용해 모르는 값을 추정하며, 각 상태와 행동의 관계를 최대한 활용하는 방식 + 몬테카를로 기법 처럼 환경에 대한 선험적 지식이 필요 없음
단점으로는 TD 기법은 불편 추정량이 아니므로 이상적인 계산을 통해서도 오차가 발생할 수 있음.
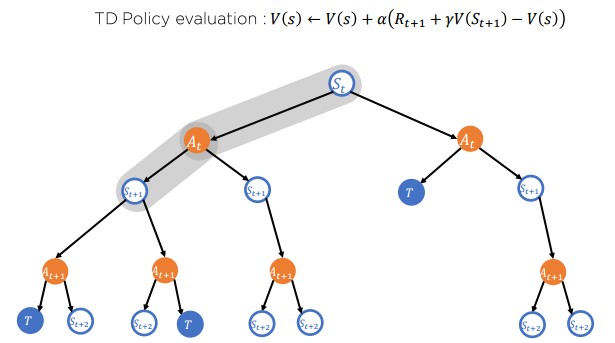
Temporal-diffence 기법

벨만 에러에서는 벨만 에러가 높은 순서대로 를 업데이트하는 알고리즘 (Prioritized sweeping) 을 통해 수렴을 조금 더 빠르게 할 수 있었는데 TD 에러도 마찬가지 기법으로 빠르게 를 업데이트 하는 알고리즘이 존재함.
MC vs. TD
MC는 기본적으로 에피소드가 끝나야지 적용할 수 있으나 TD는 에피소드의 종결여부와 상관없이 학습을 진행할 수 있음. 리턴의 추산이 MC와 달리 현재 상태의 보상과 다음 상태 가치 함수의 추산치만 있으면 되기 때문임.

- 편향/분산 관계
- MC 기법은 편향이 없기 때문에, 수 많은 시행을 거치면 참 를 찾을 수 있다.
하지만 TD에 비해 추정치가 높은 분산을 가지기 때문에 좋은 추정을 얻기 위해서는 많은 시행이 필요 - TD 기법은 알고리즘이 편향을 내재함. 따라서 시행횟수와 무관하게 의 추정에 오류가 있다. 반면에 MC에 비해 추정치의 분산이 낮기 때문에, 빠른 속도로 충분히 괜찮은 추정치를 얻을 수 있다.
- MC 기법은 편향이 없기 때문에, 수 많은 시행을 거치면 참 를 찾을 수 있다.
- Markovian 특성 활용 여부
- MC 기법은 주어진 문제가 정확하게 Markovian이 아니어도 정확한 추산치를 계산할 수 있다. 하지만 효율성이 떨어진다.
- TD 기법은 주어진 문제가 정확하게 Markovian이 아니면 정확한 추산치를 계산할 수 없다. 하지만 빠르게 추산할 수 있다.
Full-width back up vs. Sample-back up
Q1) 과연 진짜로 큰 문제(엄청 큰 상태 행동공간 을 가져 메모리에 V, Q를 저장할 수 없는 경우)를 주어진 시간 내에 DP로 풀 수 있을까?
A1) ??
Q2) 현실에서 (환경에 대한 모델이 주어지지 않은 경우)로 표현되는 문제의 정보를 언제나 알 수 있을까?
A2) MC, TD로 알 수 있음.
"큰 문제"에서 Full-width backup
DP는 기본적으로 모든 가능한 상태에 대해서 동기적으로 업데이트 => 계산량이 많아져 비동기 버전으로 업데이트
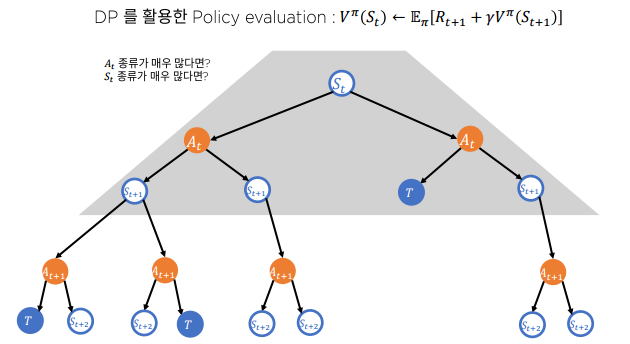
MC 기법을 활용한 Sample backup
TD 기법을 활용한 Sample backup
여러 스텝의 보상을 활용한 TD: n-step TD

여러 스텝의 리턴을 어떻게 평균을 낼까?
- 도대체 몇 스텝의 리턴을 사용해야 하는 것인가?
- 서로 다른 추정치를 모두 사용하여 하나의 추정치를 만들 수 없을까?

여러 개의 추정치를 하나의 추정치로 표현하기


여러 개의 추정치를 하나의 추정치로 표현하기 - TD()
- 기하적으로 감소하는 scaling + 평균!