channel&self-attention
- 자연어 처리에서 처음 등장
channel은 weight를 각각 지정
self-attention은 각 channel의 관계 간의 weight을 파악 (단어 간의 weight를 구한 matrix와 관계)
-
attention is all you need 참고
-
self-attention
query(질문) > key > value -
scaled dot-product attention
-
각 단어의 v1, v2, v3, v4를 vector로 나타낸 후 각각이 query, key, value에 영향, query에 대한 operation을 통해 key, key로 value를 찾는다
-
단어를 vector로 변환한 후 상관관계를 수치상으로 표현 : The sum of the reweighted values
-
query와 key의 similarity를 통해 나온 value로 attention이 생성
-
softmax의 dot-product를 통해 query와 key의 similarity를 찾은 후 value와 연산
블로그 참고 -
computer vision의 pixel을 하나의 vector로 이해해서 계산
-
self-attention의 계산량 heavy
Transformer (self-attention 이후)
- pytorch로 구현되어있는 것 참고
- 최대 256개 중 일부만 사용, operation 방법 참고.
- self attention architecture참고
- encoding 시 vector로 변환해서 add : position encoding
- 5page Position-wise Feed-Forward Networks는 linear function.
- padding을 통해 부족한 data 채움
참고 자료 - shifted right : 가장 왼쪽에 빈칸을 만든다 왜?
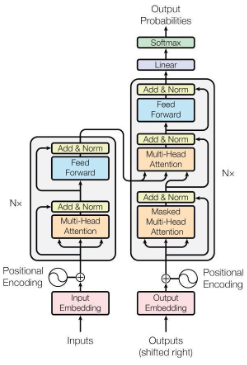
맨 처음 Outputs에 빈칸을 대입해서 첫번째 단어를 도출, 여지까지의 결과를 모두 이용해서 다음 맥락을 도출하는 데에 사용. (RNN은 sequence, 순서대로 출력, 순서가 중요한 요인이 됨)
Vision Transformer(Classification)
- pixel (non-local nueral network)을 이용, pixel 간의 관계를 구함
- img patch간의 관계는 transformer architecture를 이용해서 구한다 : 단 다량의 data가 있을 때만 가능
- pytorch 구현 이전에 transformer직접 구현해보면서 각각의 parameter의 의미 파악이 중요
- pytorch torch.nn Transforemr pytorch transformer
