0. 3줄 요약
-
본 논문은 Vision-Language-Action(VLA) 모델의 모방 학습(Imitation Learning)이 지닌 한계를 극복하기 위해, 데이터 기반의 세계 모델(World Model)을 시뮬레이터로 활용하는 강화 미세조정(Reinforcement Fine-Tuning) 프레임워크인 VLA-RFT를 제안합니다.
-
확장된 확률적 미분 방정식(SDE) 정책이 도출한 행동을 세계 모델에 주입하여 미래의 시각적 궤적(Visual Trajectory)을 생성하고, 이를 전문가 데이터와 비교하여 산출된 검증된 보상(Verified Reward)을 GRPO 알고리즘으로 최적화하는 구조를 갖습니다.
-
단 400회의 최적화 단계만으로도 기존 지도 학습(SFT) 베이스라인 모델의 성능을 상회하며, 환경 외란(Perturbation)에 대한 실패 복구 능력 및 강건성을 대폭 향상시켜 실용적이고 확장 가능한 VLA 모델 후학습 패러다임을 확립했습니다.
1. 배경 및 문제 정의
최근 Vision-Language-Action (VLA) 모델은 방대한 시각-언어 사전 학습 모델을 기반으로 구현되어 로봇 제어 및 의사 결정 분야에서 괄목할 만한 성과를 보여주었습니다. 현존하는 대부분의 VLA 모델은 방대한 시연 데이터를 바탕으로 한 모방 학습(Imitation Learning)에 의존하여 학습됩니다.
그러나 모방 학습 방식은 치명적인 구조적 한계를 내포하고 있습니다. 바로 분포 이동(Distribution shift) 하에서 발생하는 누적 오차(Compounding errors) 문제입니다. 전문가 시연에서 조금만 벗어난 상태에 진입하더라도, 모델은 낯선 상태에서 복구하는 방법을 학습하지 못했기 때문에 오류가 눈덩이처럼 불어나며 최종적으로 작업 실패로 이어집니다.
이를 해결하기 위해 탐색(Exploration)을 장려하는 강화학습(RL)을 도입하려는 시도가 이어지고 있습니다. 하지만 기존의 RL 파이프라인은 1) 실제 로봇을 통한 현실 세계 학습 시 천문학적인 비용과 심각한 안전 문제를 야기하며, 2) 시뮬레이터 기반 학습은 막대한 상호작용 횟수를 요구함과 동시에 Sim-to-Real(시뮬레이션-현실 간 간극) 문제에 취약하고, 3) 오프라인 RL은 환경과의 상호작용 없이 정적인 데이터에만 의존하므로 자신의 행동 결과로부터 학습할 수 없다는 문제에 직면해 있습니다.
본 논문은 이러한 딜레마를 해결하기 위해, 비싼 비용과 위험성 없이 실제 환경과 유사한 피드백을 제공할 수 있는 데이터 기반 세계 모델(Data-driven World Model)을 가상의 시뮬레이터로 활용하여 안전하고 효율적으로 VLA를 최적화하는 방법론을 정의하고 구축하는 것을 핵심 과제로 삼고 있습니다.
2. 제안 방법 (Method)
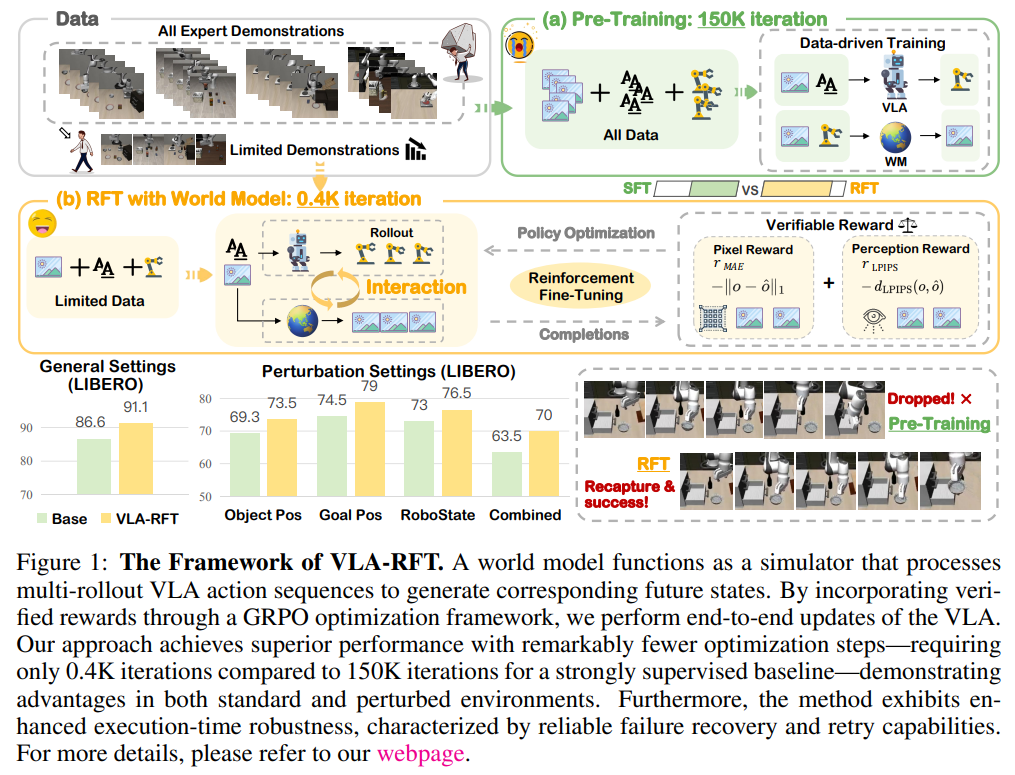
VLA-RFT의 핵심 아이디어는 로봇의 상호작용 데이터로 사전 학습된 세계 모델을 통제 가능한 시뮬레이터로 전환하는 것입니다. 정책 모델이 행동을 제안하면, 세계 모델은 해당 행동이 초래할 미래의 시각적 관측값을 예측합니다. 생성된 합성 궤적을 전문가의 목표 궤적과 비교함으로써 궤적 수준의 조밀하고 직관적인 보상을 정책에 전달합니다.
데이터 표현 및 전처리 방식
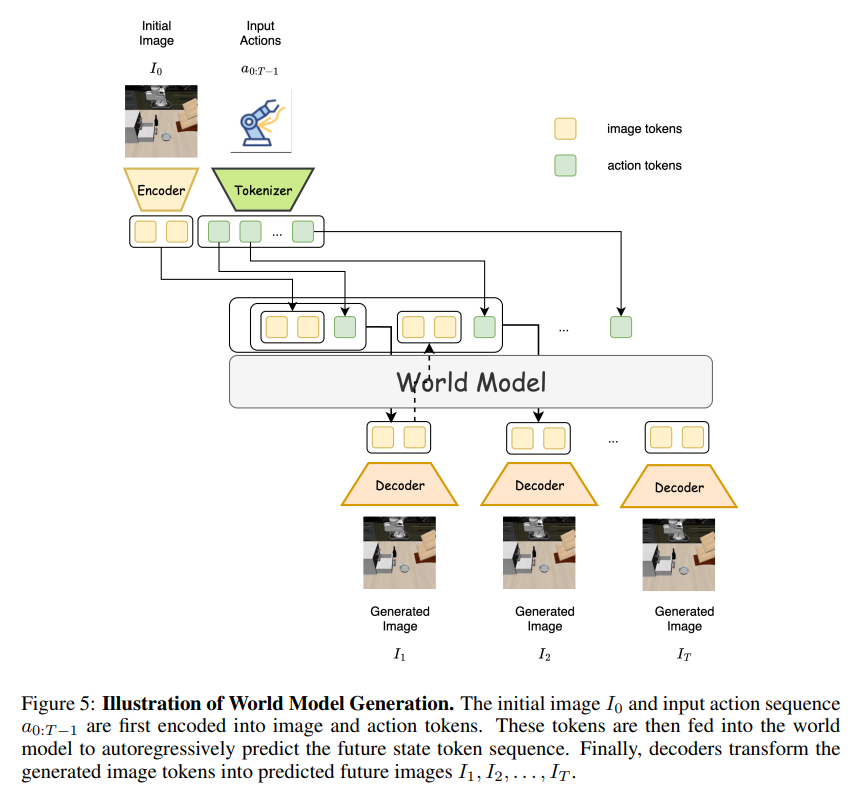
본 모델은 다중 모달리티 데이터를 입력으로 받습니다. 초기 관측 이미지 와 자연어 명령어 는 사전 학습된 Vision-Language Model (VLM) 인코더인 을 통과하여 잠재 표현(Latent representation) 로 변환됩니다. 로봇의 고유 상태(Proprioceptive state)인 와 결합된 이 잠재 표현은 Flow-matching 기반의 행동 헤드 에 주입되어 연속적인 차원의 행동 청크(Action chunk) 예측으로 이어집니다. 세계 모델의 경우 시각 정보는 이미지 토큰으로, 연속적인 행동은 이산화된 행동 토큰으로 변환되어 트랜스포머 아키텍처 내에서 자기회귀적(Autoregressive)으로 처리됩니다.
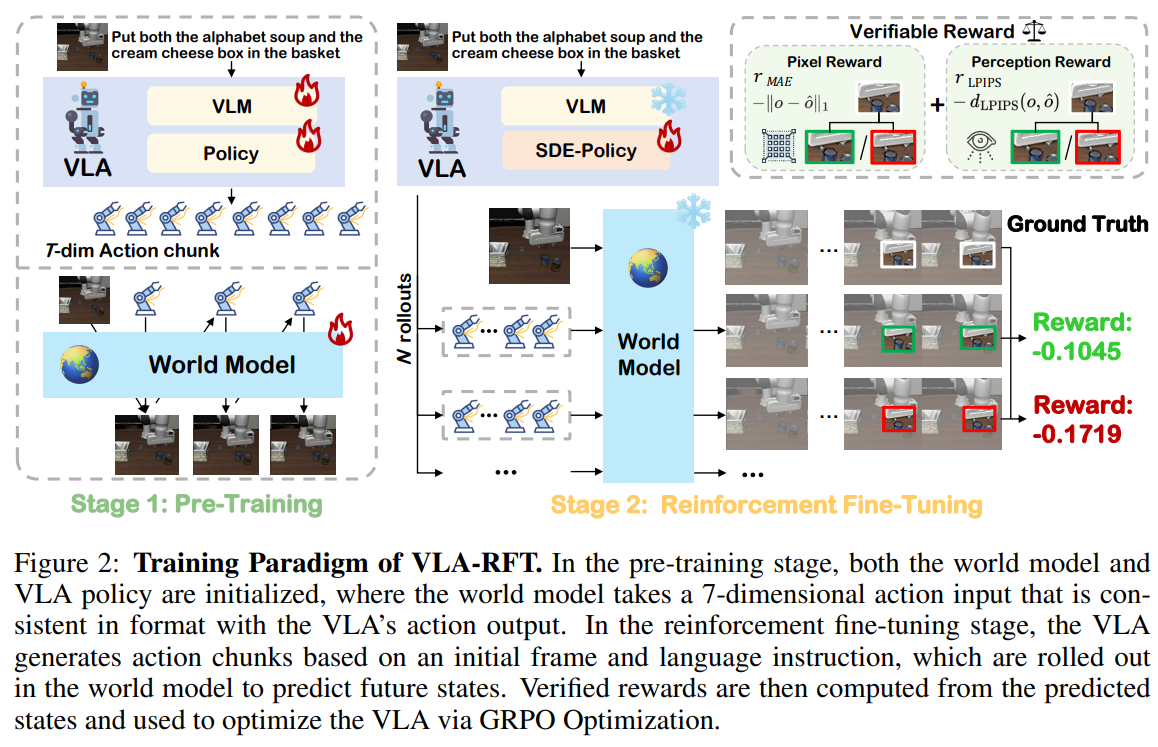
아키텍처 및 1단계: 사전 학습 (Pre-training)
안정적인 강화 미세조정을 위해, 네트워크는 최적화 이전 단계에서 오프라인 데이터를 통한 사전 학습을 거칩니다.
-
세계 모델 학습: VQGAN과 유사한 인코더와 12레이어 트랜스포머 백본으로 구성된 세계 모델은 이전 프레임과 행동이 주어졌을 때 다음 프레임을 예측하도록 훈련됩니다. 파라미터 는 최대 우도 추정(MLE)을 통해 최적화됩니다.
-
VLA 정책 학습: 초기 행동의 안정성을 확보하기 위해 VLM 인코더와 Flow-matching 헤드는 전문가 시연 데이터를 바탕으로 연속적인 행동을 예측하도록 표준 MSE 손실(Flow-matching target)을 통해 지도 학습됩니다.

아키텍처 및 2단계: 강화 미세조정 (Inference & Training Pipeline)
본 논문의 기술적 차별성은 결정론적인 상미분 방정식(ODE)을 기반으로 하는 Flow-matching 정책을 확률론적 미분 방정식(SDE)으로 확장하여 탐색(Exploration)을 가능하게 한 점과, 세계 모델과 GRPO를 결합한 파이프라인에 있습니다.
-
SDE-Policy 기반 탐색 및 추론: 강화학습을 위해서는 정책이 다양한 행동을 탐색하고 로그 우도(Log-likelihood)를 계산할 수 있어야 합니다. 이를 위해 VLA-RFT는 행동 헤드와 동일한 구조의 'Sigma Net(파라미터 )'을 도입하여 노이즈 분산 벡터 를 출력합니다. 추론 시 Forward Euler 방법을 통해 단계로 적분하며, 각 적분 단계 에서 행동 청크는 다음과 같은 가우시안 분포에서 샘플링됩니다.
이를 통해 전체 롤아웃에 대한 평균 로그 확률을 계산하고, 구정책(Old policy) 대비 비율(Policy ratio) 을 산출합니다.
-
세계 모델 상호작용 및 검증된 보상(Verified Reward) 산출: SDE-Policy가 제안한 행동 청크가 세계 모델에 입력되면, 세계 모델은 합성 시각적 궤적 을 생성합니다. 이 합성 궤적을 오프라인 데이터셋의 Ground-Truth 이미지 와 비교하여, 픽셀 레벨(L1) 차이와 지각적 유사도(LPIPS)의 음수 가중합으로 명확한 보상 을 도출합니다.
-
GRPO를 이용한 정책 업데이트: 도출된 보상 을 동일 그룹(동일 시작 상태) 내 롤아웃들의 평균 보상()과 빼서 Advantage를 구합니다. 이후 행동 공간의 과도한 변화를 막기 위한 클리핑(Clipping) 항, 모델 안정성을 위한 보조 MSE 손실, 탐색을 유도하는 정책 엔트로피 를 결합하여 GRPO 목적 함수로 와 를 최종 업데이트합니다.
3. 실험 결과 (Experiments)
실험은 조작 및 환경의 일반화를 평가하는 LIBERO 벤치마크 데이터셋에서 진행되었습니다. 기반이 되는 비교 대상(Baseline)은 강력한 지도 학습(SFT) 미세조정 방식이 적용된 VLA-Adapter의 경량 버전입니다. 세계 모델은 138M 파라미터의 LLaMA 아키텍처를 차용하여 효율성을 극대화했습니다.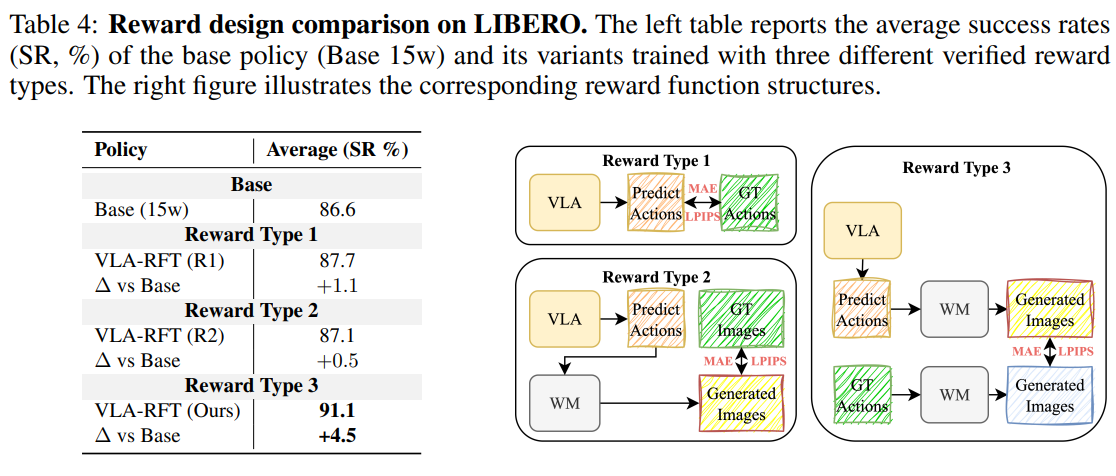
핵심 성능 (Standard Settings)
베이스라인 모델이 150,000스텝의 광범위한 지도 학습을 거쳐 평균 86.6%의 성공률(SR)을 기록한 반면, VLA-RFT는 사전 학습 모델에 단 400회(0.4K)의 RFT 반복만 추가했음에도 성공률을 91.1%로 끌어올렸습니다. 이는 대규모 상호작용을 요구하는 기존 시뮬레이터 기반 RL이나 방대한 연산을 요구하는 지도 학습에 비해 압도적인 샘플 효율성과 성능 개선을 의미합니다.
강건성 확보 및 어블레이션 (Perturbation Settings)
이 방법론이 가장 두각을 나타낸 부분은 분포 이동 상황에서의 성능(Robustness)입니다. 로봇의 초기 높이나 물체의 위치를 의도적으로 변형시킨 외란(Perturbation) 환경에서, 베이스라인 정책은 성능이 극심하게 하락했습니다(예: 복합 주요 외란에서 34.0%). 반면, VLA-RFT는 향상된 행동 탐색 범위(Action distribution coverage) 덕분에 예기치 못한 환경 변화 속에서도 오류를 자체 복구(Failure recovery)하며 높은 작업 안정성을 유지했습니다(+3.0% ~ +6.7%의 성능 방어율).
또한, 보상 체계에 대한 어블레이션 결과, 단순히 정책과 데이터셋의 행동 값(Action)의 거리 차이만을 보상으로 삼았을 때는 성능 향상이 미미했습니다(+1.1%). 그러나 세계 모델이 생성한 동일한 가상 공간 내에서 궤적 전체의 픽셀/지각적 유사도를 평가한 VLA-RFT 보상 방식(+4.5%)이 가장 높은 일반화 성능을 견인했음이 증명되었습니다.
4. 한계점 및 시사점
한계 및 엔지니어링적 과제
본 논문은 명확한 한계점 역시 공유하고 있습니다.
- 전문가 의존성: 현재 보상 함수는 세계 모델이 예측한 궤적이 기존 전문가 시연 데이터(Ground-Truth)와 얼마나 유사한지에 전적으로 의존합니다. 따라서 정책이 전문가 데이터를 능가하는 새로운 최적의 제어 전략을 스스로 발굴하는 데에는 제약이 따릅니다.
- 세계 모델 용량 병목: 세계 모델 자체의 표현 용량(Representational capacity) 한계가 최종 성능에 직접적인 영향을 미칩니다. 장기적인 일관성을 유지하고 더 복잡한 물리 동역학을 모델링하기 위해 대규모 데이터와 파라미터를 활용한 스케일 업이 필요합니다.
- 계획(Planning) 구조의 부재: 세계 모델을 미래 상태의 보상 검증 수단으로만 한정하였으며, 추론 단계에서 경로를 탐색하는 장기 계획(Long-horizon reasoning/planning) 모듈로 직접 통합하지는 못했습니다.
시사점
그럼에도 불구하고 VLA-RFT는 실제 로봇에서의 무모한 탐색 연산이나, 물리적 오류가 만연한 시뮬레이션 환경에 얽매이지 않고도 안전하고 실용적으로 VLA 모델을 고도화할 수 있음을 입증했습니다. 특히 세계 모델을 '데이터 기반 평가자(Simulator)'로 도입함으로써 단 400회의 미세조정만으로 SFT의 누적 오차 한계를 타파하고 강건성을 확보한 점은, 향후 스케일러블(Scalable)한 로봇 기반 멀티모달 파운데이션 모델의 후학습 방향성에 지대한 학술적 이정표를 제시합니다.
