Abstract
많은 연구자들이 다양한 분야의 전문지식에 접근하기 어렵다는 한계를 극복하고자, 이 연구는 Virtual Lab이라는 AI–인간 협업형 연구 플랫폼을 제안했다.
이 시스템은 LLM 기반 Principal Investigator (PI) 에이전트가 LLM 과학자 팀을 구성하고 연구 미팅을 주도하며, 인간 연구자는 고수준 피드백만 제공한다.
이를 통해 기존 LLM이 특정 질문에 답하는 데 그치던 한계를 넘어서, 복합적인 과학 연구를 자율적으로 설계실행하는 에이전트 구조를 구현하였다.
Main
다학제 과학 연구는 다양한 분야의 전문가 협업을 필요로 하지만, 인력 구성과 조정이 어렵고, 특히 자원이 부족한 그룹은 복잡한 연구에 접근하기 어렵다.
최근에는 ChatGPT, Claude 등 대형 언어 모델(LLMs)이 등장하여 과학 질문 응답, 논문 요약, 코드 작성 등의 작업을 지원하지만, 이는 개별 질문 수준에 머물러 있으며, 복잡한 다단계 과학 탐구에는 한계가 있었다.
기존 시도들(ChemCrow, Coscientist, AI Scientist 등)은 대부분 단일 분야에 집중되거나 실험적 검증이 포함되지 않았다.
이 논문은 이러한 한계를 극복하고자 Virtual Lab을 도입하였다. Virtual Lab은 인간 연구자가 생물학자나 컴퓨터 과학자 역할을 지닌 AI 에이전트들을 가이드하며, 이 에이전트들은 LLM 기반 추론 능력을 바탕으로, 서로 및 인간과 상호작용하면서 연구 프로젝트의 다양한 단계를 다룬다.
이 아키텍처는 다양한 융합 과학 연구에 적용 가능한 구조로 제시된다.
논문은 Virtual Lab의 능력을 입증하기 위해, 최신 SARS-CoV-2 변이에 결합할 수 있는 새로운 나노바디를 설계하는 고난도 실제 과학 문제에 적용하였다.
이 문제는 생물학과 컴퓨터 과학의 여러 하위 분야에 걸친 복합적 추론과 상호 연결된 의사결정을 요구한다.
Virtual Lab은 일련의 미팅을 통해 다음과 같은 계산적 나노바디 설계 워크플로우를 개발했다
- ESM(단백질 언어 모델)
- AlphaFold-Multimer(단백질 접힘 예측 모델)
- Rosetta(계산 생물학 도구)를 조합해
기존 Wuhan 변이 RBD에 결합하는 나노바디를 돌연변이시켜 최신 변이에도 결합 가능한 형태로 변형하였다.Virtual Lab이 설계한 92개의 나노바디 중 90% 이상이 발현되었고 용해성이 있었으며, 그중 두 후보는 최신 JN.1 및 KP.3 변이에 대해 독특한 결합 특성을 보였다.
이는 Virtual Lab의 AI–인간 협업이 복잡한 융합형 과학 연구를 수행해 현실 세계에서 실험적으로 검증된 결과로 이어질 수 있음을 보여준다.
Virtual Lab architecture
Virtual Lab은 인간 연구자와 LLM 에이전트 팀 간 협업을 통해 정교하고 융합적인 연구를 수행하는 구조다.
인간 연구자는 LLM 에이전트들에게 고수준의 가이드라인을 제공하고,
에이전트들은 일반적인 연구 방향 결정과 구체적인 연구 문제 해결을 맡는다.
각 에이전트는 역할, 전문 분야, 목표, 역할이 정의된 prompt로 구현된다.
인간 연구자는 두 개의 일반적 역할의 에이전트인 PI(Principal Investigator) 와 Scientific Critic을 정의하며, 이후 PI 에이전트가 주제에 따라 필요한 과학 에이전트들(예: 면역학자)을 자동으로 생성한다.
연구 수행은 두 가지 형태의 미팅을 통해 진행된다:
- 팀 미팅: 모든 에이전트가 모여 광범위한 연구 질문을 다루며 토론하고 공동으로 해결책을 찾는다.
- 개별 미팅: 특정 과학 에이전트가 단독 또는 Scientific Critic과 함께 보다 구체적인 작업(예: ML 코드 작성 등)을 수행한다.
이 미팅들은 병렬로 여러 번 실행될 수 있고, 이후 집계 미팅(aggregation meeting)을 통해 답안을 통합한다. Virtual Lab은 이러한 미팅 시퀀스를 통해 복잡한 과학 프로젝트를 다룬다.
Virtual Lab for nanobody design
Virtual Lab은 아키텍처의 유연성 덕분에, 각 프로젝트의 목표와 제약에 맞게 에이전트 구성과 팀/개별 미팅 흐름을 조정함으로써 다양한 융합형 과학 프로젝트에 적용 가능하다.
본 논문에서는 생물학적 응용 사례로, GPT‑4o를 기반으로 구동되는 Virtual Lab을 활용하여 SARS‑CoV‑2의 최신 변이 중 하나인 KP.3 변이의 스파이크 단백질에 결합할 수 있는 항체 또는 나노바디를 설계하는 문제에 적용하였다.
이 문제는 SARS-CoV-2가 기존 항체/나노바디 치료법에 빠르게 내성을 진화시키고 있기 때문에, 최신 변이에 대응 가능한 새로운 치료제를 신속히 개발하는 것이 매우 중요하고 어려운 문제다.
Virtual Lab은 KP.3 변이에 대응하는 항체/나노바디를 설계하는 계산적 워크플로우를 빠르게 구축하였고,
해당 워크플로우를 통해 생성된 설계 결과는 인간 생물학자들이 실험적으로 검증할 수 있도록 제공되었다.
이 설계 프로세스는 총 5단계(phases)로 구성된다.
1)팀 선택 (Team selection):
PI와의 개별 미팅을 통해 이 프로젝트에 참여할 과학 에이전트들을 정의함 (Fig. 2a).
2)프로젝트 명세 (Project specification):
팀 미팅을 통해 프로젝트 방향을 정하고, 주요 high-level 세부사항들을 결정함 (Fig. 2b).
3)도구 선택 (Tools selection):
나노바디 설계에 사용될 머신러닝 및 계산 도구들에 대한 브레인스토밍을 팀 미팅에서 진행함 (Fig. 2c).
4)도구 구현 (Tools implementation):
개별 미팅들을 통해 ESM, AlphaFold-Multimer, Rosetta로 구성된 워크플로우 세 가지 컴포넌트를 구현함 (Fig. 2d).
- 먼저, PI와의 개별 미팅을 통해 각 과학 에이전트가 어떤 컴포넌트를 맡을지 결정하고
- 각 컴포넌트에 대해 선정된 과학 에이전트 + Scientific Critic이 함께 코드 작성 미팅을 진행한 후,
- 동일한 과학 에이전트가 (Critic 없이) 오류 수정을 위한 개별 미팅을 한 번(ESM, AlphaFold-Multimer) 또는 두 번(Rosetta) 더 진행함.
5)워크플로우 설계 (Workflow design):
PI와의 개별 미팅을 통해 위의 도구들을 어떻게 적용할지에 대한 전체 워크플로우를 결정함 (Fig. 2e).
Computational nanobody design
Virtual Lab은 기존에 Wuhan 변이의 스파이크 단백질에 결합하는 나노바디들을
최신 KP.3 변이에 결합할 수 있도록 적응시키는 계산적 설계 워크플로우를 구축했다 (Fig. 3a).
이 워크플로우는 총 4개의 기존 나노바디(Ty1, H11-D4, Nb21, VHH-72)를 입력으로 사용하고,
다음의 3가지 도구를 활용했다.
- 단백질 언어 모델 ESM
- 단백질 접힘 예측 모델 AlphaFold-Multimer
- 단백질 모델링 소프트웨어 Rosetta
이 도구들을 이용해 반복적으로 점 돌연변이(point mutations)를 도입하여,
KP.3 변이의 스파이크 단백질의 RBD(receptor binding domain)에 대한 결합력을 개선하였다.
나노 바디 워크플로우
- 워크플로우 개요
- 기존의 Wuhan 변이 결합 나노바디 4종(Ty1, H11-D4, Nb21, VHH-72)을 시작점으로,
ESM, AlphaFold-Multimer, Rosetta 세 도구를 활용하여 KP.3 변이에 결합할 수 있는 나노바디를 생성함.
- 단계별 처리 과정
- ESM: 각 단일 점 돌연변이에 대해 log-likelihood ratio(LLR)를 계산함.
→ 높은 LLR은 더 안정적인 나노바디를 의미. - AlphaFold-Multimer: 상위 20개 후보를 KP.3 RBD와 결합한 구조 예측 수행
→ binding interface의 신뢰도를 AF ipLDDT로 측정. - Rosetta: 이 복합체를 구조적으로 최적화(relaxation)하고, binding energy(RS dG)를 계산함.
- 스코어 통합 및 반복 설계
세 지표를 조합한 가중합 공식으로 WS(weighted score) 생성.
- WS = 0.2×ESM LLR + 0.5×AF ipLDDT − 0.3×RS dG
→ WS로 상위 5개 후보 선택 → 이들을 다시 돌연변이시켜 다음 라운드에 투입
→ 이 과정을 4회 반복하여 최대 4개 돌연변이를 가진 나노바디 생성
- 최종 선택 및 보정
- 각 출발 나노바디마다 최종 23개씩 총 92개 돌연변이 나노바디 선택
- 보정된 점수 WSWT 사용: 이전 라운드 입력 대신 wild-type과 비교한 새로운 ESM LLRWT 기반
- 이 92개 모두 ESM LLR > 0 (wild-type보다 선호됨)
- 성능 지표 및 결과
- 85%가 AF ipLDDT가 향상
- 65%가 RS dG 감소 (결합력 증가)
- 25%는 RS dG ≤ –50 → 강한 결합력의 후보로 간주됨
최종 23개 후보는 다양한 돌연변이 수와 점수 조합을 갖춰 구조적 다양성 확보
중요 내용 :
- AI가 multi-metric 기반으로 실험 결과를 반복 최적화했다
- LLM이 평가 공식을 직접 설계하고 loop 구조를 제어했다
- 결과가 실제 실험으로 이어져 성공률이 정량적으로 검증됐다
Nanobody experimental validation
실험적 검증 결과 (Experimental Validation)
1. 발현 (Expression)
- Virtual Lab이 설계한 92개 나노바디를 E. coli에서 과발현하고 periplasm에서 단백질 분리.
- *38% (35/92)는 >25mg/L,
6.5% (6/92)**는 <5mg/L → 설계된 돌연변이들이 발현 안정성에 잘 견딤.
2. 결합력 평가 (Binding Test)
- 96개 나노바디(92 mutant + 4 wild-type)를
5종의 SARS-CoV-2 RBD(예: KP.3, JN.1, KP.2.3, BA.2, Wuhan)에 대해 ELISA로 측정. - H11-D4/Nb21 계열: 96%가 Wuhan RBD 결합력 유지.
- Ty1 계열: 결합력 유지 실패율 높음 → 첫 번째 돌연변이 위치(pos. 32)가 원인일 가능성.
- VHH-72 계열: 절반 이상이 Wuhan 결합 유지.
- 특이한 고성능 돌연변이들 발견
- Nb21 돌연변이 I77V-L59E-Q87A-R37Q:
- JN.1 RBD에 결합
- MERS-CoV, BSA에는 비특이적 결합 없음
- KP.3 RBD에도 평균보다 높은 결합 강도 (ELISA intensity: 3.5 vs. 0.1)
- Ty1 돌연변이 V32F-G59D-N54S-F32S:
- Wuhan RBD에 결합력 ↑
- JN.1 RBD에도 moderate 결합력 확보 (wild-type은 결합 전무)
- Nb21 돌연변이 I77V-L59E-Q87A-R37Q:
4. 왜 효과 있었는가? (Scoring 분석 기반)
- ESM LLR: 항원 무관하게 진화적으로 안정적인 서열을 선호하여, Wuhan 결합력 유지에 기여
- AlphaFold-Multimer & Rosetta:
→ KP.3 RBD (및 유사한 JN.1 RBD, 99.1% 동일)에 결합력 증가 효과 유도
중요 내용 :
- LLM이 설계한 나노바디가 실제 실험에서 높은 발현성과 결합력을 보여줌으로써, Virtual Lab이 현실에서 유효한 생물학적 설계를 수행할 수 있음을 입증했다.
- ESM, AlphaFold-Multimer, Rosetta는 모두 Virtual Lab에서 사용된 도구지만, 각각 평가하는 방식과 초점이 다르기 때문에, 안정성·결합력 등 목적에 따라 역할이 분리된 tool-specific agent 설계가 가능함을 시사한다.
- 실패 케이스까지 분석 가능한 구조적 추적성을 갖추어, 단순한 AI 응답이 아닌 과학적 설계로서의 신뢰성을 확보했다.
Analyses of Virtual Lab interactions
- 작업 시간 및 효율
- 개별 미팅 또는 병렬 미팅당 약 5~10분, 전체 미팅 시간 1~2시간, GPT-4o 비용으로 약 $10–20.
- 전체 프로세스(프롬프트 튜닝 + 코드 리뷰 포함)는 몇 일(few days) 내에 완료.
→ 동일 작업을 사람이 직접 수행하면 수 주 이상 걸릴 작업임.
- 후속 작업 소요 시간
- 계산적 나노바디 설계 실행 (ESM + AlphaFold + Rosetta): 약 1주
- 나노바디 생합성: 약 6주
- 결합력 실험(ELISA): 약 2주
- 에이전트 개성(Identity)의 중요성
- 각 LLM 에이전트는 자신의 과학적 배경에 기반한 관점으로 기여해 다학제 토론을 형성.
- 반대로, 과학적 배경이 없는 일반 LLM agent 팀은 역할 충돌, 논쟁 증가, suboptimal 답변 생성. (Ablation 실험 결과)
- 인간 vs LLM 기여
- 인간 연구자의 입력 텍스트: 1,596단어 (전체 텍스트의 1.3%)
- LLM 에이전트 출력 텍스트: 122,462단어 (98.7%)
- ESM/AFM/Rosetta 코드 모두 에이전트가 from scratch로 작성,
인간은 보조 스크립트(데이터 정리, 스케줄링 등)만 작성 + 스크립트 실행 담당
- 회의 유형별 발화량 분포
- PI(Principal Investigator)는 회의를 시작하고 응답을 종합해 다음 라운드를 유도하며 마지막 요약도 작성하기 때문에 팀 미팅에서 가장 많은 발화량을 보임.
- Scientific Critic는 각 agent의 한계를 지적하는 역할이라 scientist agents보다 더 많은 텍스트를 작성함.
- 각 scientist agent는 자신의 관점만 제시하므로 비교적 짧게 작성함.
- 구조적 설계의 효과
- 병렬 미팅 구조(parallel meetings)와 Scientific Critic의 포함 여부가 응답의 일관성(consistency)과 품질 향상에 긍정적 영향을 미침 (보조 실험에서 확인됨)
중요 내용 :
- 효율성과 비용 면에서 이미 인간보다 빠르고 싸다.
→ 전체 실험 설계 논의가 1~2시간, 몇 일 내 완성, 비용도 $10–20 수준
→ Claude MCP 시스템도 실제 적용 시 빠른 회전율과 저비용 처리 가능성 있다는 실증 - 에이전트 역할 분리는 답변 품질 향상에 결정적이다.
→ 각각 다른 scientific identity를 가진 agent가 전문성과 관점을 갖고 토론할 때 결과가 좋았고,
→ generic agent는 suboptimal 결과를 냈다 - 코드는 에이전트가 쓰고, 사람은 운영만 한다.
→ 모든 핵심 스크립트(ML 파이프라인 포함)는 LLM이 작성
→ 인간은 인프라 환경에 맞게 실행·보조만 했음
→ → 자동 실험 설계 + 코드 생성 → 운영 실행 구조가 실제로 작동한다는 확증 - 발화량과 역할은 밀접하게 연결되어 있다.
→ 팀 회의에서 누가 많이 말해야 하는지 사전 정의가 되어 있어야 흐름이 잡힘. - 에이전트 간 책임 분산이 설계 품질에 직결된다.
→ 의견 제시(agent)와 비판 역할(critic)을 분리함으로써 답변 정제와 검증 가능성이 높아짐. - 병렬 구조는 품질 향상을 유도할 수 있다.
→ agent별로 병렬 실행 → 취합 → 정제 구조 도입하면, 훨씬 더 고품질 대화 생성 가능
Discussion
Virtual Lab은 정교하고 융합적인 과학 연구 프로젝트 목표를 달성했다. 인간 연구자와 LLM 에이전트 팀은 일련의 미팅을 통해 면역학, 단백질 접힘, 머신러닝 등 여러 분야의 지식을 통합하여, 최신 변이에 대응하는 복잡한 나노바디 설계 파이프라인을 빠르게 구축했다. 그 결과, 기존 나노바디 4종에서 출발해 92개의 후보를 개발했고, 이 중 일부는 실험적으로 성능이 검증되었다.
에이전트의 과학적 결정이 기존 문헌과 유사하더라도, Virtual Lab은 주어진 과학적 질문에 신속히 적응하여 인간 연구자가 전문가 패널 없이도 복잡하고 학제간 연구를 수행할 수 있도록 지원한다는 점에서 의의가 크다.
기존 연구에서는 AI를 단순 도구로 사용해 인간이 모든 고수준 연구 결정을 내렸지만, Virtual Lab에서는 인간과 LLM 에이전트가 함께 연구 프로젝트를 설계하고 실행한다. 이 시스템의 강점은 multi-agent 아키텍처로, 서로 다른 배경을 가진 에이전트들이 다양한 관점에서 과학적 질문을 논의하여 포괄적인 답을 도출한다.
이 과정에서 PI 에이전트는 토론을 주도하고 핵심 결정을 내리며 내용을 요약한다. Scientific Critic 에이전트는 다른 에이전트들의 답변 품질을 끌어올리고, 인간 연구자는 에이전트가 놓친 맥락을 보완하며 고수준 가이드라인을 제공한다. 팀 미팅과 개별 미팅은 각각 고수준 연구 방향 논의와 구체적 솔루션 구현에 적합하며, 이를 통해 LLM의 추론 능력을 끌어내는 chain-of-thought 유사 효과를 다양한 관점과 human-in-the-loop 요소와 결합해 구현한다.
- 현재 LLM의 내재적 한계
- 훈련 데이터가 특정 시점까지로 제한되어 있어 최신 과학 문헌이나 코드(예: AlphaFold 3)가 반영되지 않을 수 있다.
- 이는 관련 정보와 문서를 에이전트에 제공하거나 RAG(Retrieval-Augmented Generation), 파인튜닝을 통해 보완 가능하다.
- Virtual Lab 구조는 특정 연구 분야에 국한되지 않으며, 다양한 주제와 에이전트 구성, 심지어 다른 LLM으로도 구현 가능하다.
- 프롬프트 엔지니어링 필요성
- 적절한 가이드 없이 LLM 에이전트는 모호한 답변을 할 수 있다.
- 원하는 결과를 얻기 위해 회의 아젠다를 여러 번 반복 조정해야 할 수도 있다.
- LLM 성능이 향상되면 프롬프트 엔지니어링의 비중은 줄어들 수 있다.
- 정확성 문제(환각)
- LLM은 잘못된 사실이나 인용을 만들어낼 수 있다.
- Critic 에이전트의 사실 검증, 과학 논문 원문 등 외부 자원 제공으로 일부 완화 가능하다.
- 핵심 사실과 결정을 검증하는 데는 여전히 인간 연구자의 역할이 필수다.
Figure
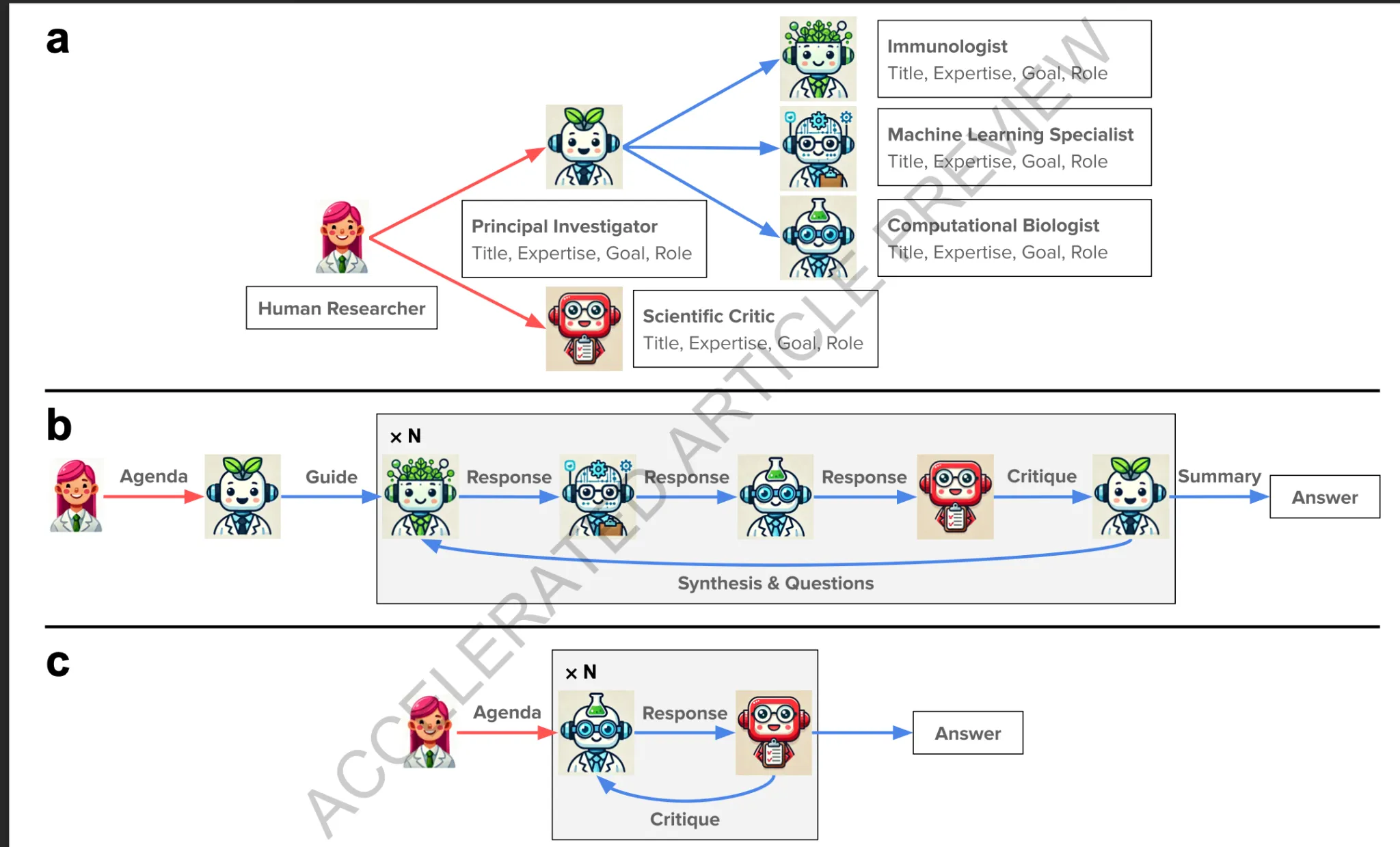
a. 에이전트 설계 워크플로우
- Human Researcher: 프로젝트를 제안하고 아젠다를 설정하며, 핵심 가이드를 제공.
- Principal Investigator (PI):
- title, expertise, goal, role 네 가지 속성으로 정의됨
- Human이 정의한 정보를 바탕으로 여러 Scientist Agents를 자동 생성
- Scientific Critic (SC): 다른 에이전트들의 응답을 검토하고 비판, 품질 향상에 기여
- Scientist Agents: 특정 분야(예: Immunologist, ML Specialist, Computational Biologist)에 특화
b. 팀 미팅(Team Meeting)
- Human이 회의 아젠다 작성 → PI에게 전달
- PI가 초기 가이드 제공 (주요 질문, 논의 방향)
- N라운드 진행
- Scientist Agents: 각자 응답
- SC: 응답 비판 및 개선 제안
- PI: 논의 내용을 종합하고 후속 질문
- 라운드 종료 후 PI가 전체 요약 및 최종 답변 작성
c. 개별 미팅(Individual Meeting)
- Human이 개별 아젠다 작성 → 특정 Scientist Agent에게 전달
- 해당 Agent가 응답 작성
- SC가 비판 및 피드백 제공
- Agent가 피드백 반영해 수정
- N라운드 후 최종 개선된 답변 도출
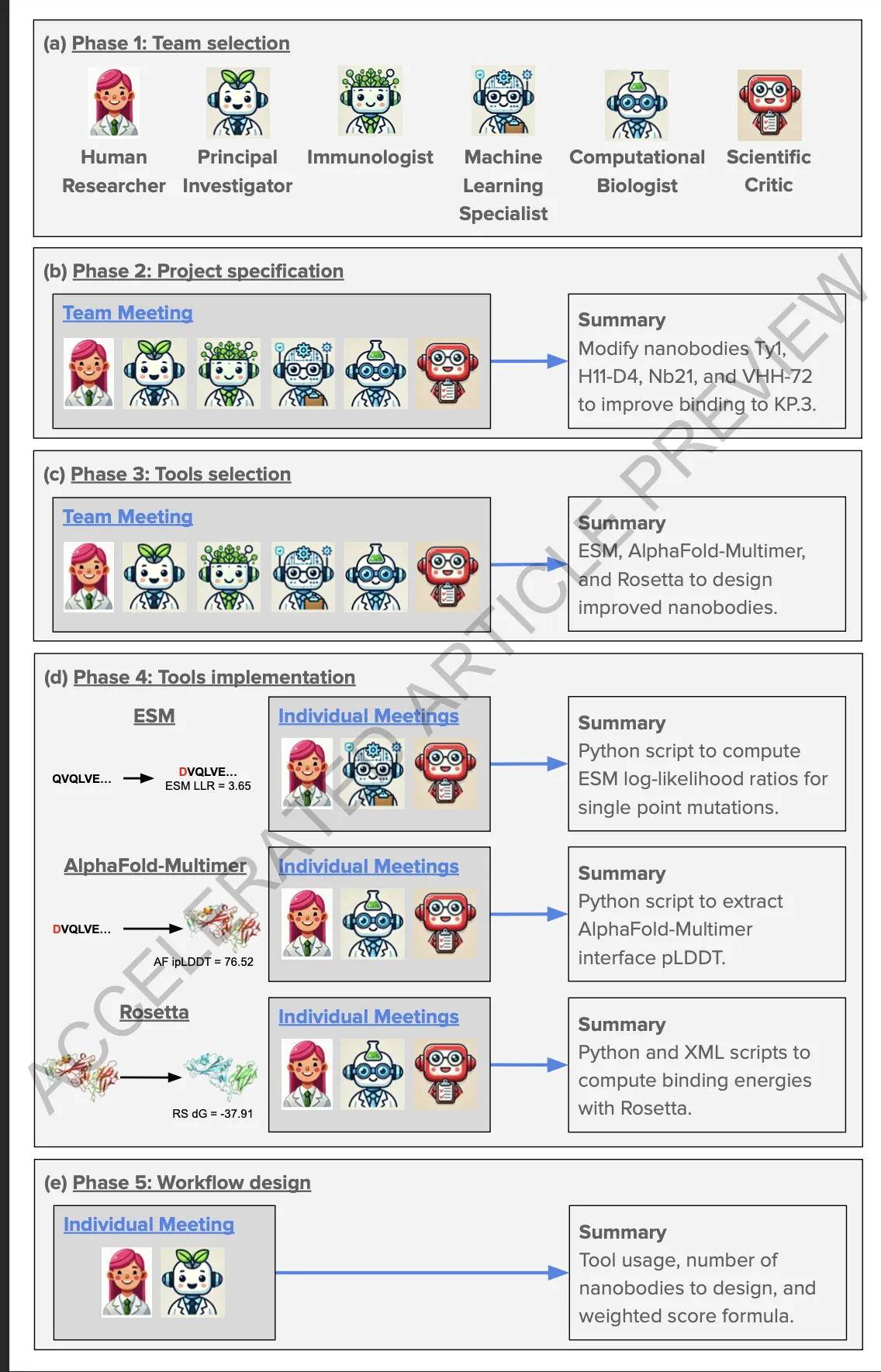
Phase 1: Team selection
- Human Researcher가 PI(Principal Investigator)와 SC(Scientific Critic)를 정의하고, PI가 프로젝트에 맞는 전문 에이전트들을 생성
- 예시: Immunologist, Machine Learning Specialist, Computational Biologist
Phase 2: Project specification (팀 미팅)
- 모든 에이전트가 모여 프로젝트 방향 논의
- 결론: Ty1, H11-D4, Nb21, VHH-72 나노바디를 수정해 KP.3 변이 결합력 개선 목표 설정
Phase 3: Tools selection (팀 미팅)
- 설계에 사용할 주요 계산 도구 선정
- 결론: ESM, AlphaFold-Multimer, Rosetta 활용
Phase 4: Tools implementation (개별 미팅)
각 도구별로 전문 에이전트 + SC가 코드 작성 및 개선
- ESM → Python 스크립트로 단일 점 돌연변이 LLR 계산
- AlphaFold-Multimer → Python 스크립트로 pLDDT(결합면 신뢰도) 추출
- Rosetta → Python/XML 스크립트로 결합 에너지 계산
Phase 5: Workflow design (개별 미팅)
- PI와 Human이 전체 워크플로우 설계
- 도구 사용 순서, 생성할 나노바디 개수, 가중치 점수 계산 공식 확정
Method
1. 에이전트 구성
- 모든 LLM 에이전트는 Title, Expertise, Goal, Role 네 가지 속성으로 정의됨.
- PI(Principal Investigator): AI for Science 전문성, 연구 방향 결정·가이드.
- Scientific Critic: 모든 에이전트 답변의 오류·누락 지적, 비판적 피드백 제공.
- Scientist Agents: PI가 프로젝트 설명을 바탕으로 자동 생성(예: Immunologist, Machine Learning Specialist, Computational Biologist).
2. 미팅 구조
팀 미팅 (Team Meeting)
- 모든 에이전트 참여: PI, Scientist Agents, Critic.
- Human이 아젠다·질문·규칙 설정 → PI가 시작 발언 및 질문 → 각 Scientist 응답 → Critic 비판 → PI 종합·후속 질문 → 라운드 반복.
- N라운드 후 PI가 요약·최종 답변 작성.
개별 미팅 (Individual Meeting)
- 특정 에이전트만 참여, 필요시 Critic 포함.
- N=0이면 답변만, N≥1이면 응답 → Critic 피드백 → 개선 반복 → 최종 답변.
병렬 미팅 (Parallel Meetings)
- 동일 미팅을 여러 번(온도 0.8) 병렬 실행 → Merge 미팅(온도 0.2)으로 통합 → 품질·창의성 균형.
3. 나노바디 설계 적용 절차 (5단계)
- 팀 선택
- PI 개별 미팅(병렬 5회+Merge)으로 Scientist Agents 3명 생성: Immunologist, ML Specialist, Computational Biologist.
- 프로젝트 구체화 (Team Meeting)
- 의사결정:
- Antibody vs Nanobody → Nanobody
- De novo vs 기존 수정 → 기존 나노바디 수정
- 후보: Ty1, H11-D4, Nb21, VHH-72.
- 의사결정:
- 도구 선택 (Team Meeting)
- 선정: ESM, AlphaFold-Multimer, Rosetta.
- 도구 구현 (Individual Meetings)
- ESM (ML Specialist): Python 스크립트로 단일 점 돌연변이 LLR 계산.
- AFM (Computational Biologist): Python 스크립트로 복합체 구조에서 pLDDT 추출.
- Rosetta (Computational Biologist): XML+Python으로 결합 에너지 계산.
- 워크플로우 설계 (PI Meeting)
- 순서: ESM → AFM → Rosetta.
- 가중합 점수 공식(WS): WS = 0.2×ESM LLR + 0.5×AF ipLDDT − 0.3×RS dG.
- 상위 5개 시퀀스를 다음 라운드에 투입, 총 4라운드 반복.
- 라운드 간 비교 위해 LLRWT 사용, 최종 23개 변이 + WT 선택.
4. 계산 워크플로우 예시
- Round 0: WT 분석(LLR=0) → AFM 구조 예측 → pLDDT 계산 → Rosetta 결합 에너지 → WS 산출.
- Round 1~4: ESM으로 모든 점 돌연변이 LLR 계산 → Top 20 → AFM+Rosetta 실행 → WS 순위 상위 5개 차기 라운드 투입.
5. 실험 검증
- DNA 합성·클로닝 → E. coli 발현 → 정제·SDS-PAGE로 발현량 확인.
- ELISA로 각 변이 나노바디의 여러 RBD 변이에 대한 결합력 측정.
- Nb21 변이(I77V-L59E-Q87A-R37Q)와 Ty1 변이(V32F-G59D-N54S-F32S)가 새로운 JN.1 RBD 결합력 확보.
- 전체 92개 변이 중 다수에서 발현 안정성·결합력 개선 확인.
6. 데이터·코드
- Zenodo에 계산·실험 데이터 공개.
- GitHub에 Virtual Lab 코드, 에이전트 대화, 점수 공개.
Extended
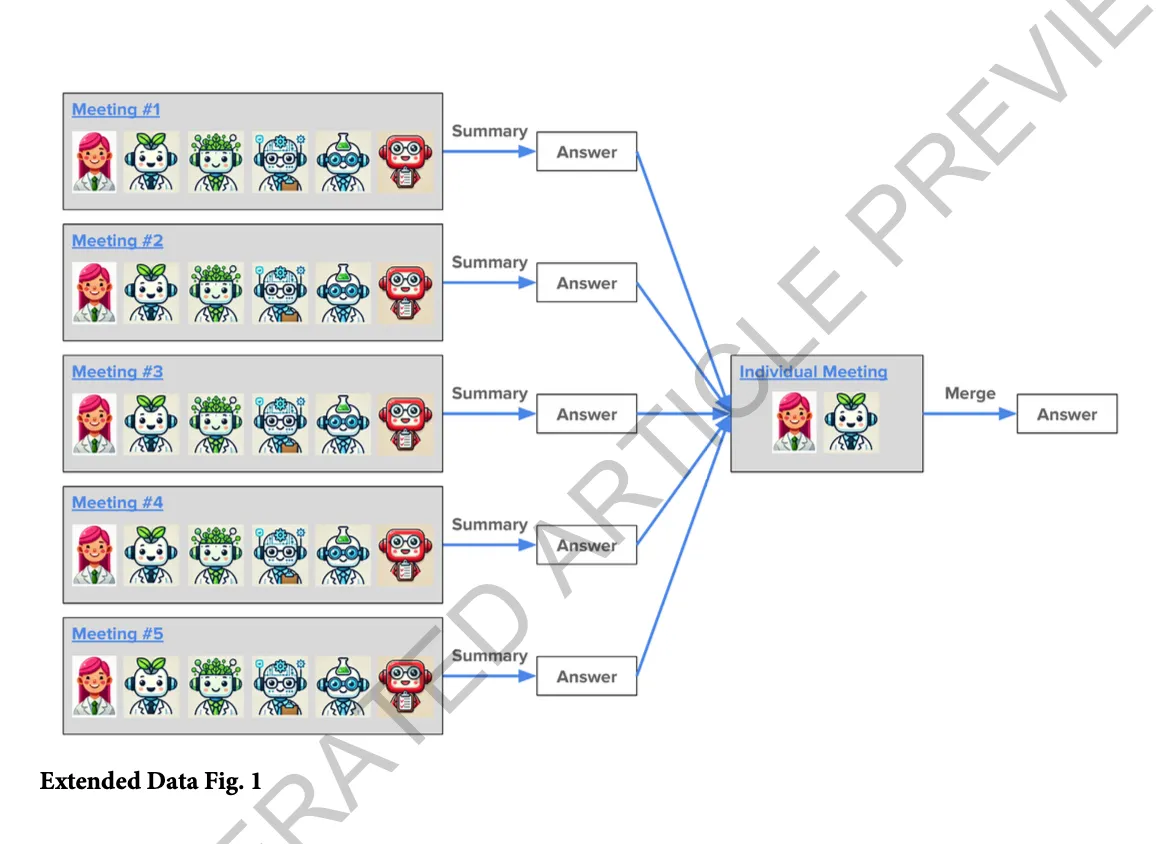
1. Extended Data Fig. 1 — 병렬 미팅(Parallel Meeting) 구조
- 왼쪽: 같은 아젠다를 가지고 5번의 병렬 팀 미팅(Meeting #1~#5)을 독립적으로 실행.
- 각 미팅에는 Human, PI, Scientist Agents, Critic이 참여.
- 각 미팅이 끝나면 Summary 작성 → Answer 도출.
- 오른쪽:
- 모든 미팅의 Summary와 Answer를 Individual Meeting(Human + PI)으로 모아 Merge.
- 최종 Answer는 병렬 결과 중 가장 좋은 부분을 종합.
- 의의:
- LLM 응답의 랜덤성(temperature)을 활용해 다양한 답변을 생성하고,
- 병합 과정에서 품질과 일관성을 확보.
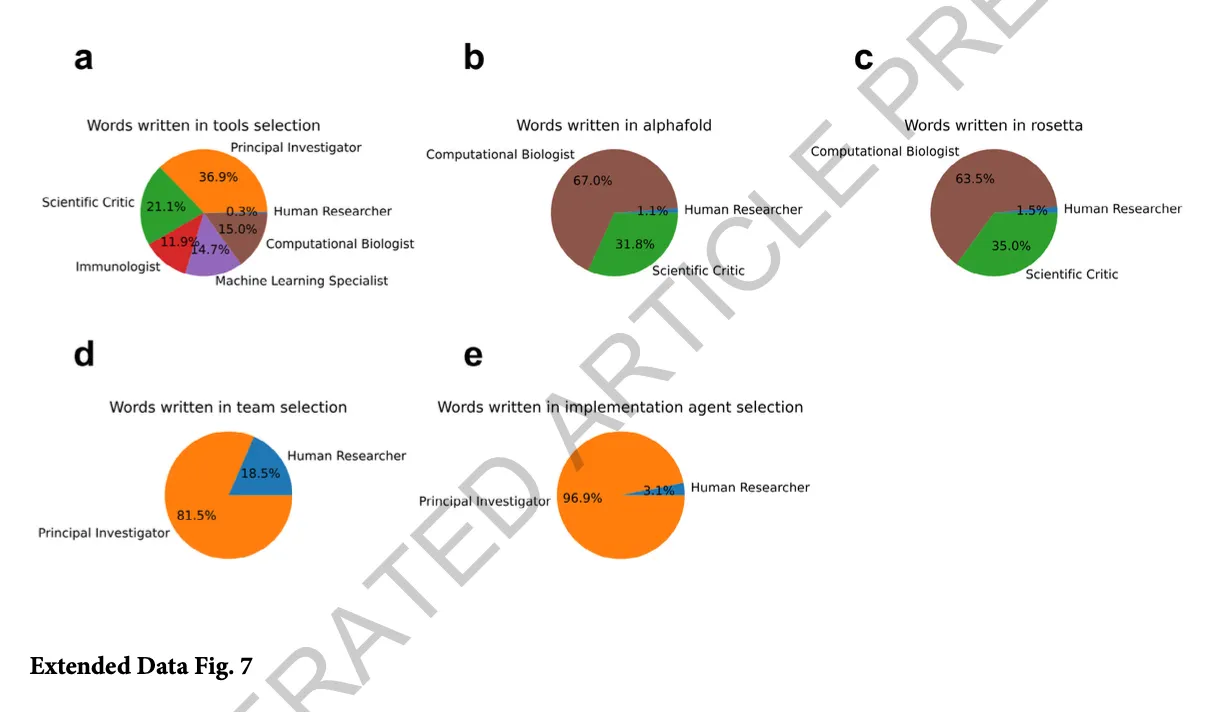
2. Extended Data Fig. 7 — 에이전트별 발화량 비율
이 그래프들은 특정 단계별로 누가 말을 많이 했는지(=토큰 수 비율)를 보여줌.
- a. Tools selection 단계
- PI: 36.9%
- Critic: 21.1%
- ML Specialist: 14.7%
- Computational Biologist: 15.0%
- Human: 0.3% → Human 발언 최소, AI가 주도
- b. AlphaFold 단계
- Computational Biologist: 67.0%
- Critic: 31.8%
- Human: 1.1%
- c. Rosetta 단계
- Computational Biologist: 63.5%
- Critic: 35.0%
- Human: 1.5%
- d. Team selection 단계
- PI: 81.5%
- Human: 18.5%
- e. Implementation agent selection 단계
- PI: 96.9%
- Human: 3.1%
