회귀 분석 (Regression Analysis)이란?
수치형데이터를 예측하기 위한 대표적인 지도 학습(Supervised Learning) 방법론
- 통계학의 꽃이라고도 불리는 회귀 분석은 데이터로부터 변수들 간의 함수 관계를 찾아내는 방법이다
- 과거 수치형 데이터로 부터 함수 관계를 찾아내고, 미래 수치형 데이터를 예측하는 문제에 주로 사용된다
- '되돌아 가다'라는 의미인 '회귀'가 사용된 이유는, 처음 회귀 분석을 고안한 영국 과학자 갈톤(Galton)의 "자식의 키와 부모의 키 관계" 연구에서
결국 "부모의 키와 상관 없이 자식들은 보통 키로 회귀(돌아간다)" 라고 사용한 것에서 유래되었다 - 과거 데이터 패턴을 학습하는 방법이기 때문에, 변동성이 심한 문제에서는 모델 성능이 떨어질 수 있다
선형 회귀(Linear Regresstion)
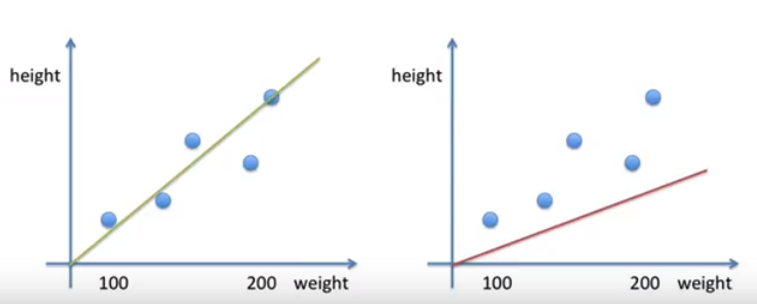
- 선형 회귀란 변수들 사이의 선형적인(직선적인) 함수 관계를 모델링 하는 방법
- 데이터를 바탕으로 변수 관계를 설명하는 일차 방정식 함수를 만듦
- Y = wX + b (
w : 기울기(가중치),b : y 절편(편향=bias))회귀 계수 혹은 가중치를 알면 X가 주어졌을 때 Y를 알 수 있다.
가중치(w)를 구하는 방법?
데이터가 충분히 있다면 가중치를추정할 수 있다.
이부분은 그래프를 수도 없이 그려서 에러를최소화하는 직선을 구하는 것을 최우선으로 한다.
Tips 데이터셋 활용한 회귀분석 1
라이브러리 불러오기
# 라이브러리 불러오기
import matplotlib.pylab as plt
import seaborn as sns
import numpy as np
import pandas as pd
# 선형회귀 훈련(적합)
from sklearn.linear_model import LinearRegression # 설계도데이터셋 불러오기
tips_df = sns.load_dataset('tips')
tips_df.head()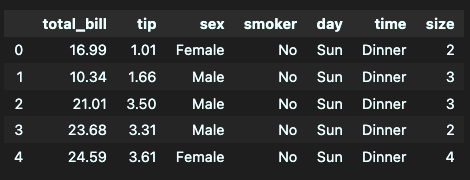
💁🏼♂️ "식당에서 파트타임으로 일하고 있는 머신이는 이번에는 tip 데이터를 가지고 적용해보기로 했습니다.
돈을 많이 벌고 싶었던 머신이는 전체 금액(X)를 알면 받을 수 있는 팁(Y)에 대한 회귀분석을 진행해볼 예정입니다."
- 컬럼 설명
- total_bill : 전체 지불 금액
- tip : 팁 금액
- sex : 성별
- smoker : 흡연 유무
- day : 요일
- time : 식사 시간(점심, 저녁)
- size : 식사 인원
X : total_bill,y = tip
선형회귀 훈련하기
model_lr2 = LinearRegression()
X = tips_df[['total_bill']] ## [[]]괄호 두번 꼭꼭!
y = tips_df[['tip']]
model_lr2.fit(X,y)
이렇게 나오면 훈련 성공(?)
산점도 그리기
sns.scatterplot(data = tips_df, x = 'total_bill', y = 'tip')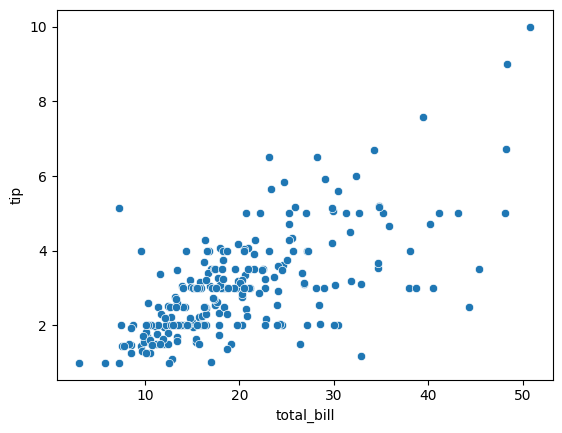
가중치, 편향 변수 만들기
# y(tip) = w1*x(total_bill) + w0
w1_tip = model_lr2.coef_[0][0]
w0_tip = model_lr2.intercept_[0]print('y = {}x + {}'.format(w1_tip.round(2), w0_tip.round(2)))
전체 결제금액이 1$ 오를 때, 팁은 0.11$ 오른다.
--> 결제금액이 100$ 오를 때, 팁은 11$ 오른다.
예측값 추출 및 데이터프레임 저장
# 예측값
y_true_tip = tips_df['tip']
y_pred_tip = model_lr2.predict(tips_df[['total_bill']])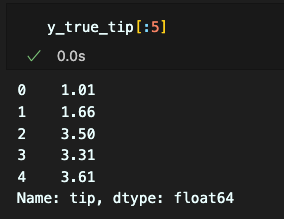
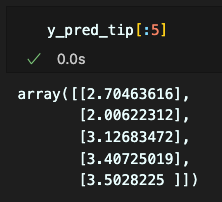
(잠깐.. 이 pred_tip은 어디서 나온거지)
# 데이터프레임에 pred 컬럼으로 새로 추가
tips_df['pred'] = y_pred_tip
tips_df.head()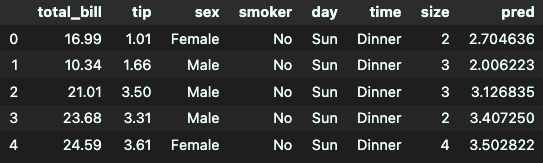
회귀분석의 평가지표
MSE(mean_squared_error 평균제곱오차)
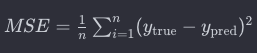
실제 값과 예측 값 간의 차이를 제곱하고, 그 평균을 계산하여 모델의 성능을 나타내는 지표
값이 작을수록 모델의 예측이 실제 값과 가깝다고 볼 수 있음
mean_squared_error(y_true_tip, y_pred_tip)
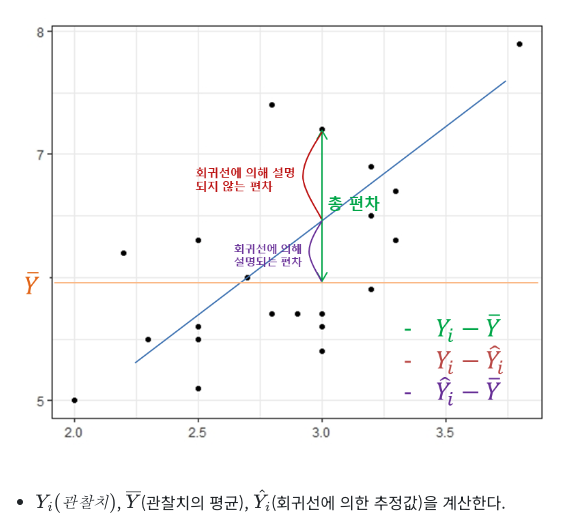
R Square
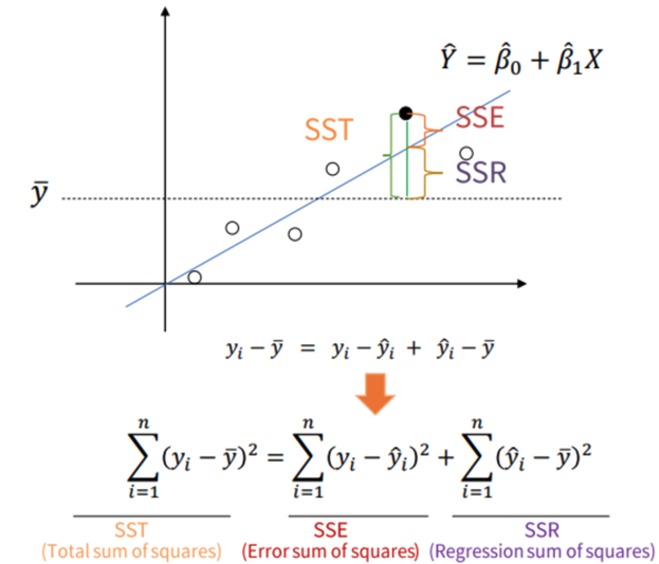
- 기초 용어
- : 특정 데이터의 실제 값
- : 평균 값
- : 예측, 추정한 값
- R Square의 정의
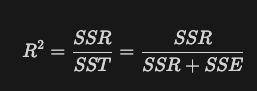
r2_score(y_true_tip, y_pred_tip)
# 사회문화, 경제에 따라 r score 는 기준이 다름
해당 값에 대한 설명력 = 45%
선형회귀 그려보기
sns.scatterplot(data = tips_df, x = 'total_bill', y = 'tip')
sns.lineplot(data= tips_df, x= 'total_bill', y='pred', color='red')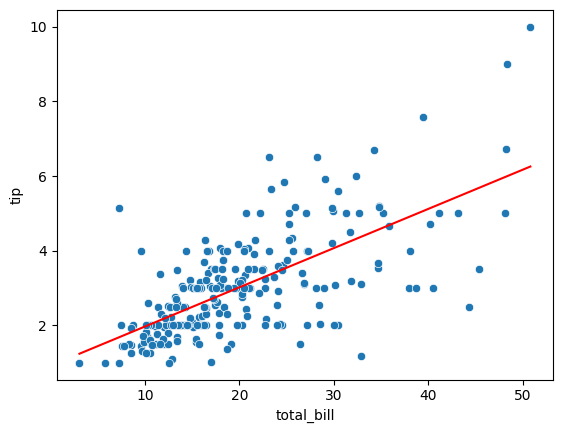
결과
- 데이터가 선을 기준으로 좌우 크게 퍼져있음
- 왼쪽에 밀집되어있는 데이터로 인해 예상 기울기보다 낮아져 있음
- R score가 낮음
'total_bill'이 아닌 다른 변수와의 비교분석 추가로 필요** **- x 변수를 여러개(젠더, 요일)로 시도해 볼 가치가 있음 = 다항다중선형회귀

데이터 애널리스트가 되고 싶은