10.25
사이킷런 라이브러리
https://scikit-learn.org/stable/index.html
Simple and efficient tools for predictive data analysis
Accessible to everybody, and reusable in various contexts
Built on NumPy, SciPy, and matplotlib
Open source, commercially usable - BSD license
-데이터 분석을 통한 예측
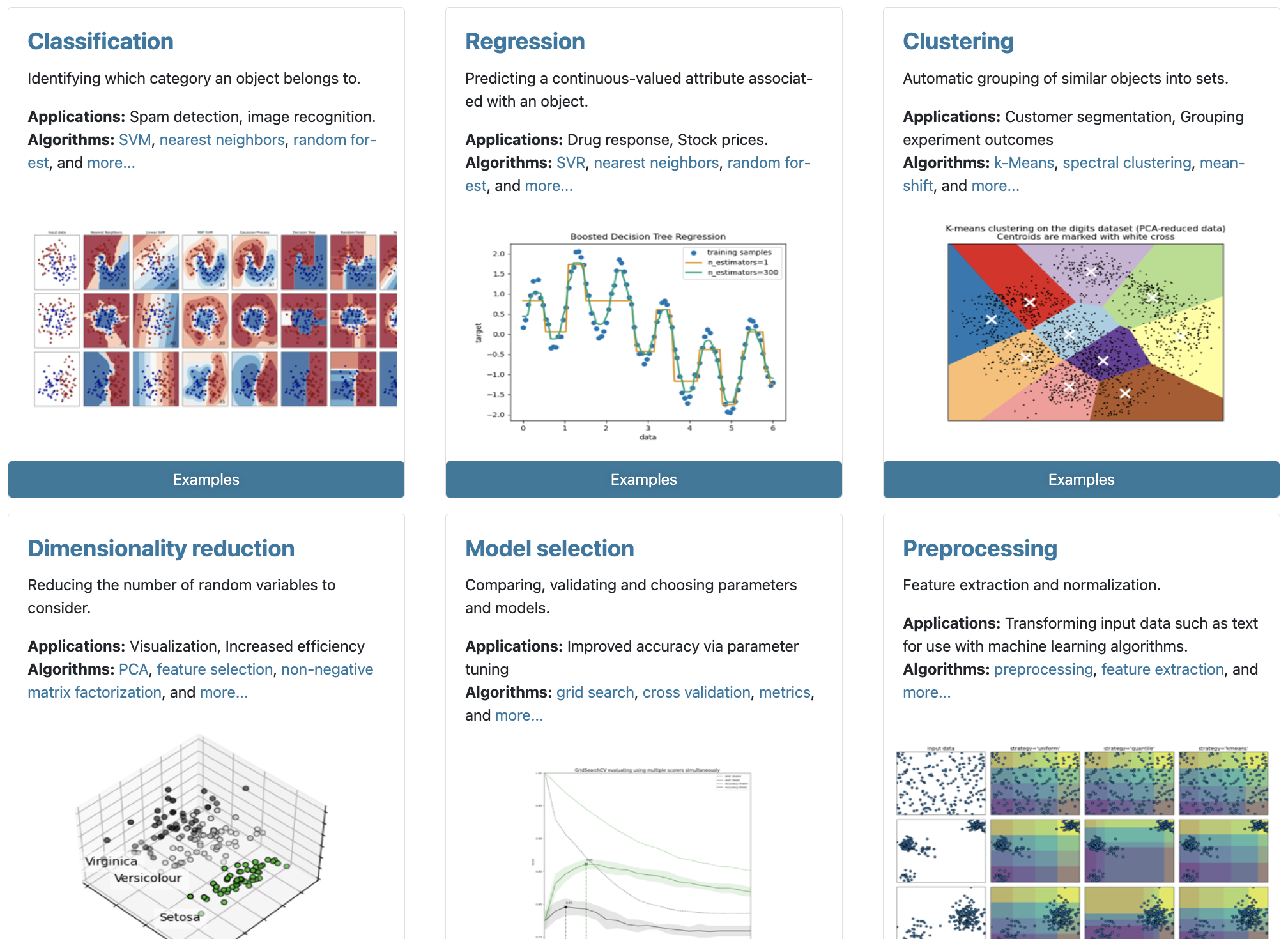
분류
-class를 나누는것
-범주형 데이터를 범주별로 분류
-지도
예시
-제품의 성능판단 시, 합격 불합격 분류
-(알약)약품 분류
-스팸 메일 분류기
-이미지 인식 후 분류
-고객이 자주하는 질문 분류!
-접수된 민원 처리 부서 분류
-mri 등의 검사 결과로 질병 진단
-이상 유저 분류(핵,트롤)
회귀
-수치형 데이터를 선형, 비선형 예측
-하나의 가설에 미치는 다양한 수치형 변수들과의 인과성 분석
예시
-주가 예측, 주택 가격 예측, 제품 수율 예측, 곡물 수확량 예측
-영화관객수예측
회귀 알고리즘 중에 분류에 사용할 수 있는 알고리즘
군집화
-유사도가 높은 범주끼리 모아주는 것
-비지도
차원축소
-고차원 데이터를 차원을 축소해서 한눈에 볼수있게 해줍니다
-파라미터 개수 감소-> 속도개선
모델선택
-학습이 잘 된 최적의 모델을 고를때
전처리
-정규화, 표준화
복습)pandas에서 --normalize 활용
-value_counts(normalize=True)
-crosstab
-0~1 사이로 데이터 값을 정리
-해당 항목의 수 / 전체 빈도수로 합이 1
머신러닝과 딥러닝의 차이 : 머신러닝이 딥러닝을 포괄하는 개념인데, 딥러닝은 신경망학습에 초점을 둔 머신러닝 기법
정답 == label == target
Nan 혹은 Null 이면 정답이 없는 것
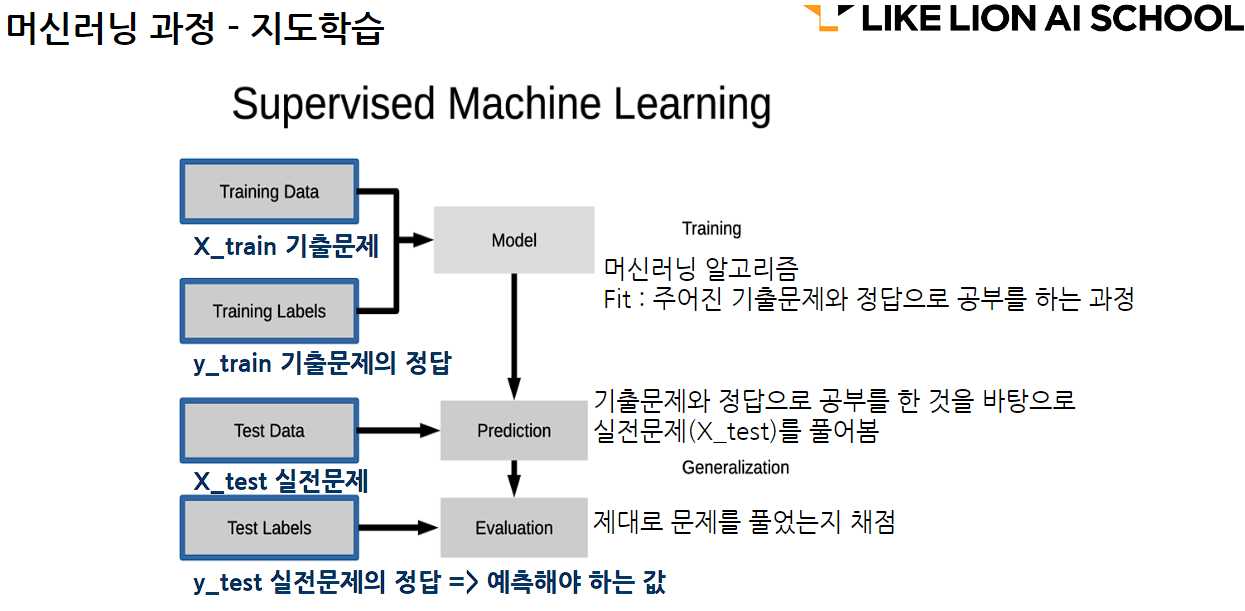
fit 학습
predict 예측
evaluate 모델평가
fit => predict => evaluate
