10.27 부트스트래핑, 베깅복습
Bootstrapping
-
통계학에서 bootstrapping은 "random sampling with replacement(복원추출)"
-
모분포의 모수에 대한 추정통계량인 표본X의 함수의 분포를 알고 싶다.그러나 X의 분포에 대해 진짜 아무것도 모를 때, 마치 우리가 모르는 X분포에서 생성된 것과 같은 sample X1, X2, X3을 추가로 생성할 수 있다면,,,?
-
이에 착안하여 이미 추출된 Sample에서 다시 반복 추출을 하고, 새로 추출된 resampled로 표준편차를 계산하는게 Bootstrapping!
잭나이프 방법
잭나이프 방법은 Quenoulle와 Tukey에 의해 1949-1956년에 걸쳐 개발된 테크닉이라고 할 수 있다.
잭나이프 방법이 ‘잭나이프’라는 이름을 갖게 된 것은 실제 잭나이프의 생김새처럼 데이터를 다루기 때문이다.

잭나이프 방법은 큰 분류로는 resampling에 기인한 방법인데, 잭나이프 방법은 주어진 데이터에서 하나 씩 빼가면서 새로운 데이터셋을 구성한다.
예를 들어 (a,b,c,d)라는 데이터셋이 주어져있다고 하면 잭나이프 방법으로는
(b,c,d), (a,c,d), (a,b,d), (a, b, c)
의 네 가지 새로운 데이터셋을 얻게 되는 것이다.
데이터를 하나 하나 빼보면서 새로운 데이터 셋을 얻는 이유는 이미 갖고 있는 데이터들을 이용해서 resampling을 함으로써 추정량의 오차 범위를 추정해볼 수 있기 때문이다.
다시 말하자면, 잭나이프 방법에서는 어떤 estimator의 출력 범위를 파악해보기 위해 부품을 하나 하나씩 빼보면서 작동하는 일을 한다.
그리고 이를 통해 기기의 전체적인 오차 범주를 파악해 볼 수 있게 되는 것이다.
부트스트래핑 방법
부트스트랩(bootstrap) 방법은 잭나이프 방법을 약간 변형한 것으로 1979년에 Bradley Efron이라는 사람이 고안해낸 방법이다.
부트스트랩이라는 말은 ‘자기 스스로 하는’, ‘독력(獨力)의’라는 뜻을 가진 단어이다.
다시 말해 주변의 도움 없이 스스로 해낸다는 의미인데, 컴퓨터의 부팅이 bootstrapping을 줄인 말이라는 것은 잘 알려져있는 사실이기도 하다.

부트스트랩은 잭나이프 방법과 유사하게 추정량(estimator)의 오차 범위를 파악하기 위해 사용되는 기법이라고 할 수 있다.
이를 위해 부트스트랩은 잭나이프 방법과 유사하게 resampling을 수행하는데, 잭나이프 방법과 다른 점은 중복을 허용한 resample을 수행한다는 점이다.
부트스트래핑의 필요성
추정통계량
추정통계량이란 표본들을 이용해 계산하는 함수라고 할 수 있다.
가령 평균을 구하는 함수, 분산을 구하는 함수는 모두 추정량이다.
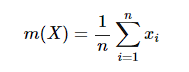
평균값은 다음과 같이 계산된다. n개의 샘플 x1,x2,⋯,xn을 입력받아 위와 같은 m(X) 함수의 정해진 계산을 수행한다. 이와 같은 맥락에서 임의의 추정량(estimator)을 정의할 수 있다.
표준오차
표준 오차란 표본 통계량의 표준 편차를 의미하는 말이다. 표본이 매번 추출될 때 마다 값이 바뀌는 특성때문에 표본 통계량은 매번 그 값에 변동이 있다. 표본이란 모집단에서 일부 추출한 subset이기 때문이다.
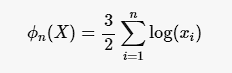
바로 위와같이 임의의 추정량ϕn을 정의했을 때, 이 표본들의 값의 표준편차가 어떻게 계산 되는지가 바로 이 추정통계량의 표준오차이다.
위에서 보았듯이 표본 평균의 표준 오차는 계산 방법이 이론적으로 잘 정립되어 있다. 그런데, 이론적으로 잘 확인되어 있지 않은 추정량이라도 표준 오차를 계산해줄 수 있는 방법이 없을까? 부트스트랩 방법은 이렇듯 추정량의 표준 오차를 계산해주는 방법이다.
부트스트래핑의 사용법
부트스트랩의 사용법을 설명하기 위해 생각해본 주어진 7개의 데이터 샘플
여기서 이렇게 주어진 7개의 데이터에 대해 반복 추출을 허용해가면서 랜덤하게 데이터를 resample한다고 해보자.
가령, 아래 그림같은 결과를 얻을 수 있을 것이다
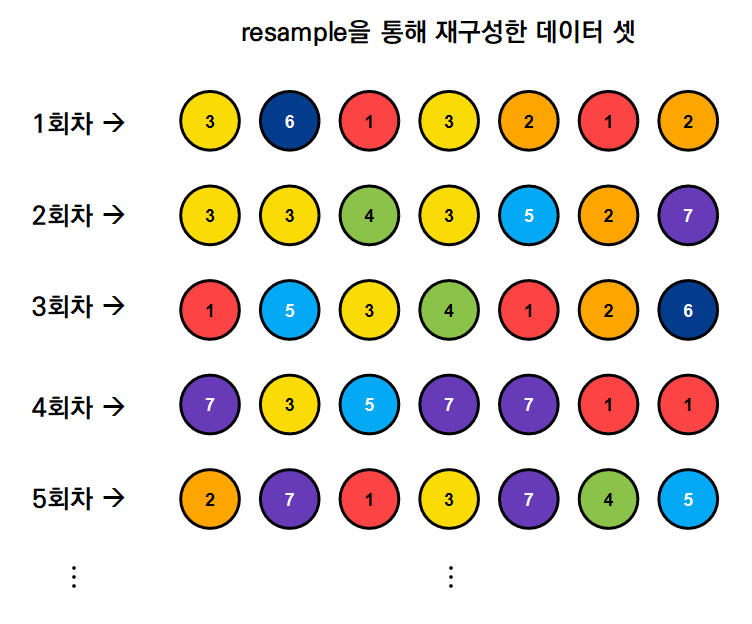
5회차까지만 resample하였지만, 1000회차, 혹은 5000회차까지 resample을 수행해보면 1000개 혹은 5000개의 데이터셋을 얻을 수 있게 된다.
이렇게 얻은 무수히 많은 데이터셋에 대해서 각각의 회차별로 estimator 값을 구하고 histogram을 구하면 estimator의 오차범위를 추정할 수 있게 되는 것이다.
부트스트랩핑의 사용 예시와 의의
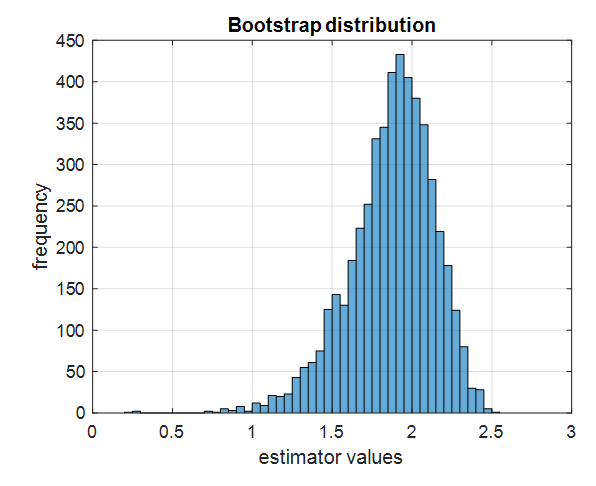
5000개의 부트스트랩 데이터셋에 estimator를 적용시켜 얻은 값들에 대한 histogram 예시
여기서 5000개 estimator 값들을 줄세워 상위 2.5% 값과 상위 97.5%의 값을 찾고 표시한 예시
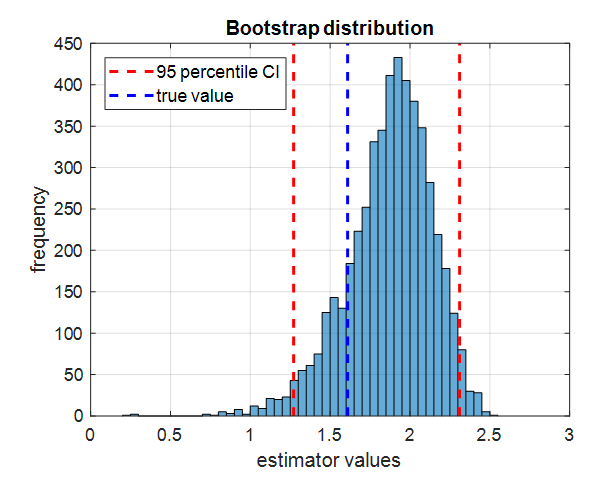
여기서 5000개 estimator 값들을 줄세워 상위 2.5% 값과 상위 97.5%의 값을 찾고 표시한 예시
상위 2.5 percentile과 상위 97.5 percentile 값은 95% confidence interval이 된다.
이 방법은 percentile Confidence Interval이라고 불리는 방법인데, 이 방법이 가장 직관적으로 이해하기 쉽다.
true value가 이 95% confidence interval 안에 속할 수 있게 된다
부트스트랩은 결국 우리가 샘플링을 여러번 하지 못하는 현실에서 여러번 추출할 수 있었을 샘플의 estimator 값 분포가 어땠을지를 논리적으로 추정할 수 있게 해준다는데 의의가 있다. 평균같이 표준 오차가 잘 알려진 estimator들은 이런 부트스트랩 같은 방법을 쓸 이유가 없지만 표준 오차를 계산하는 방법이 잘 알려져 있지 않은 식의 estimator들은 부트스트랩 방법을 통해 손쉽게 오차 범위를 생각해볼 수 있게 해주는 것이다.
