디시젼 트리
과대적합
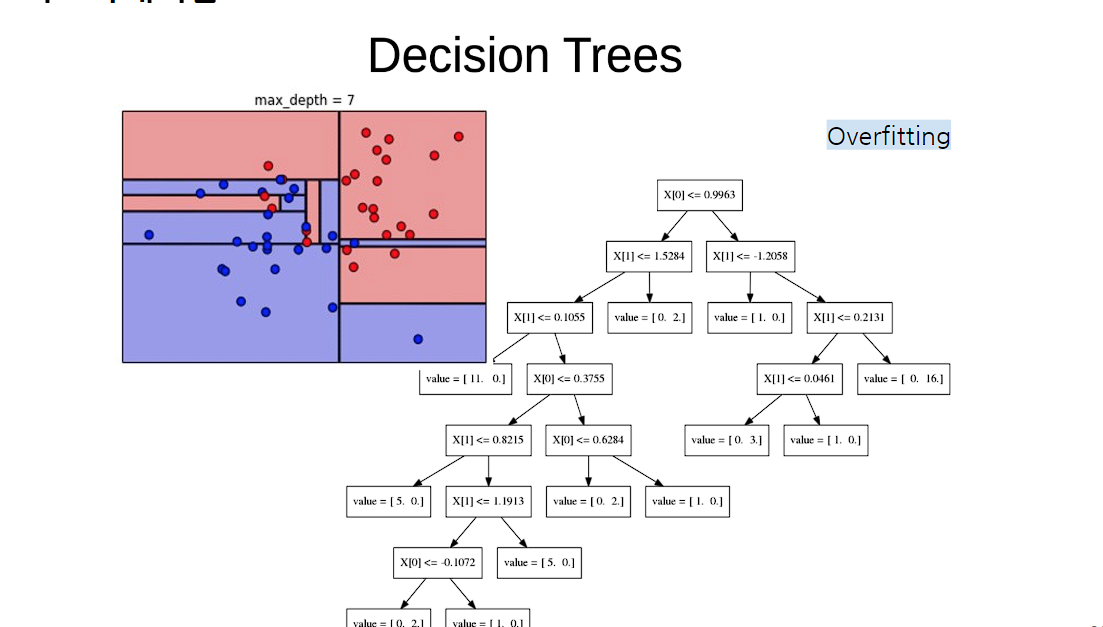
학습하지 않아도 되는 부분까지 학습해서 쓸게없는 부분까지 학습하게 되는게 과적합
gini계수
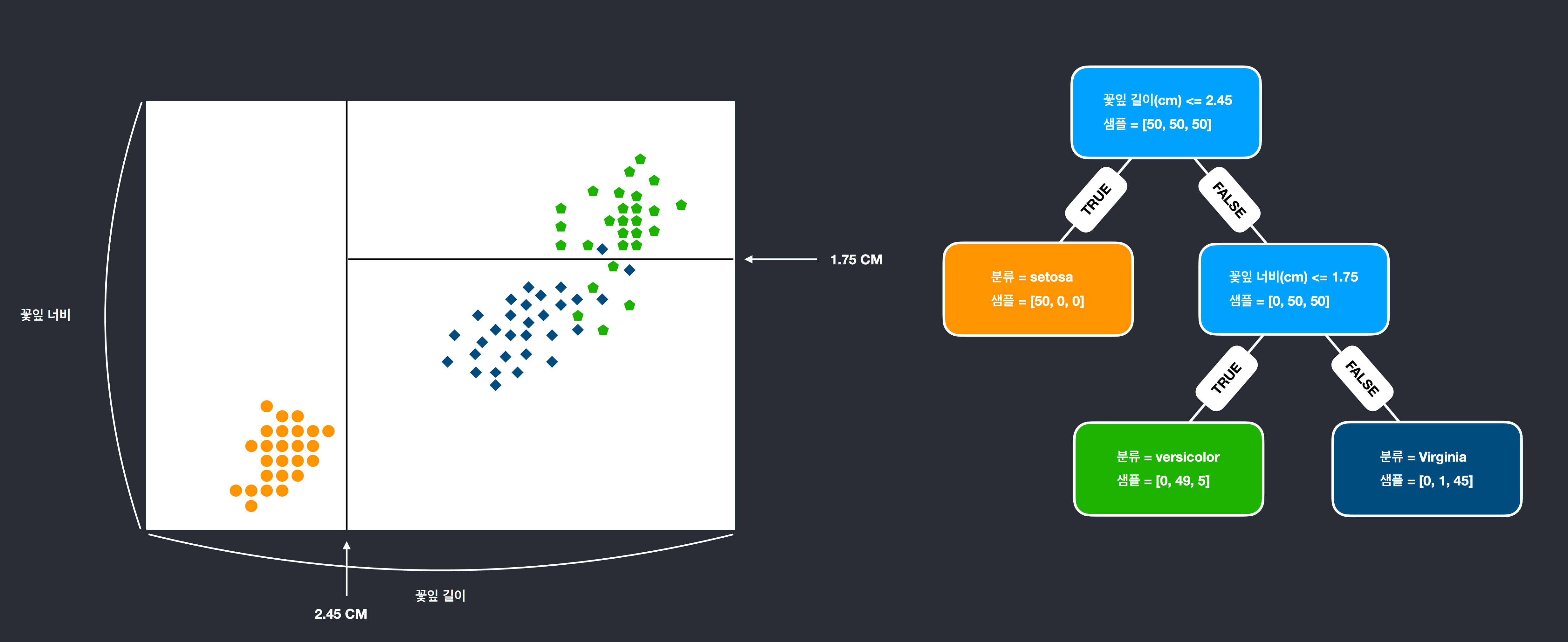
샘플데이터가 분류된다 했을때
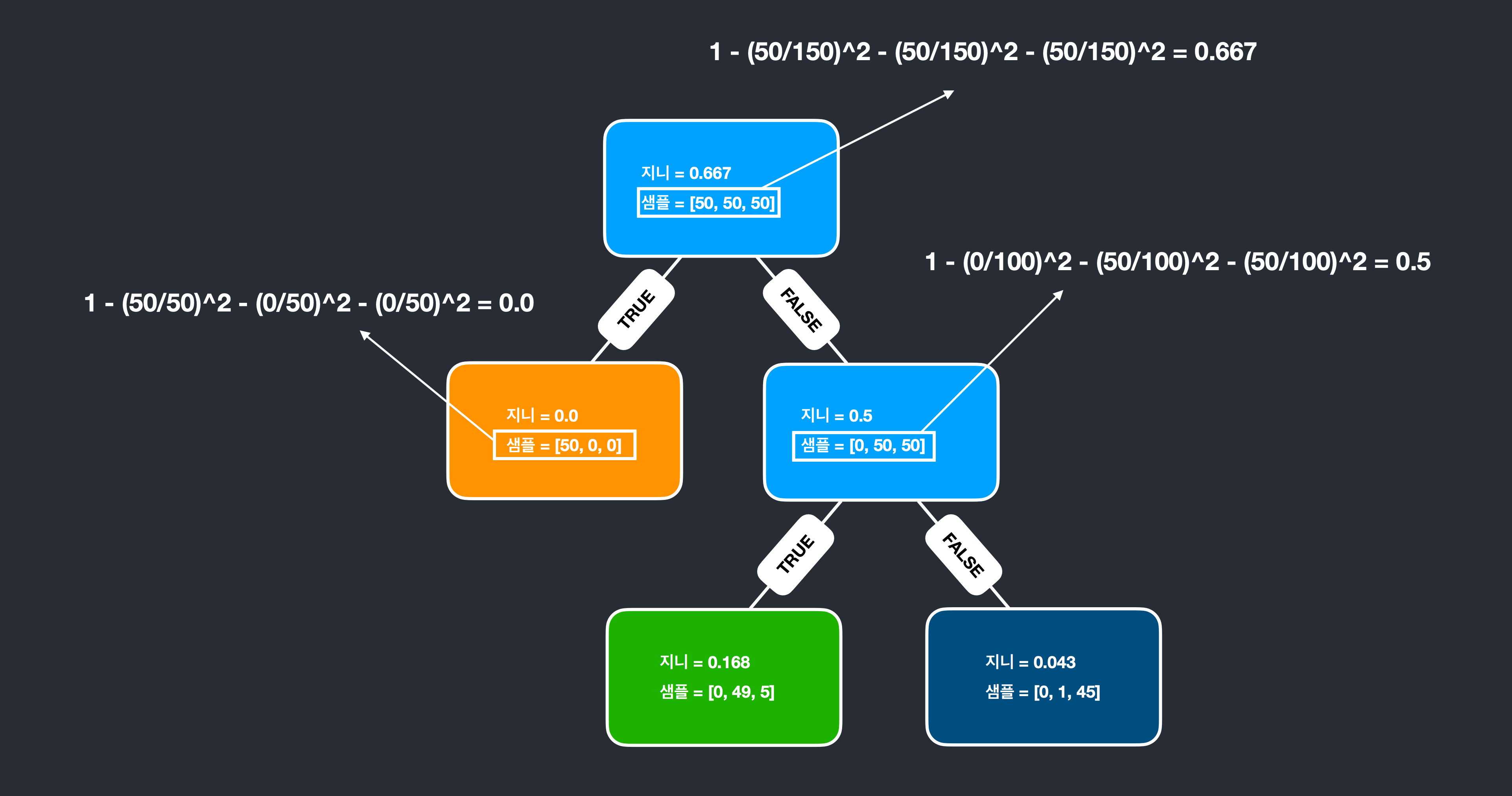
각각 지니계수가 이런 식으로 계산
즉 지니계수는 통계적 분산 정도를 정량화해서 표현한 값, 0과 1사이의 값을 가지게 되는 수치이고
지니계수가 높을 수록 잘 분류되지 못한 것으로 생각해볼 수 있습니다.
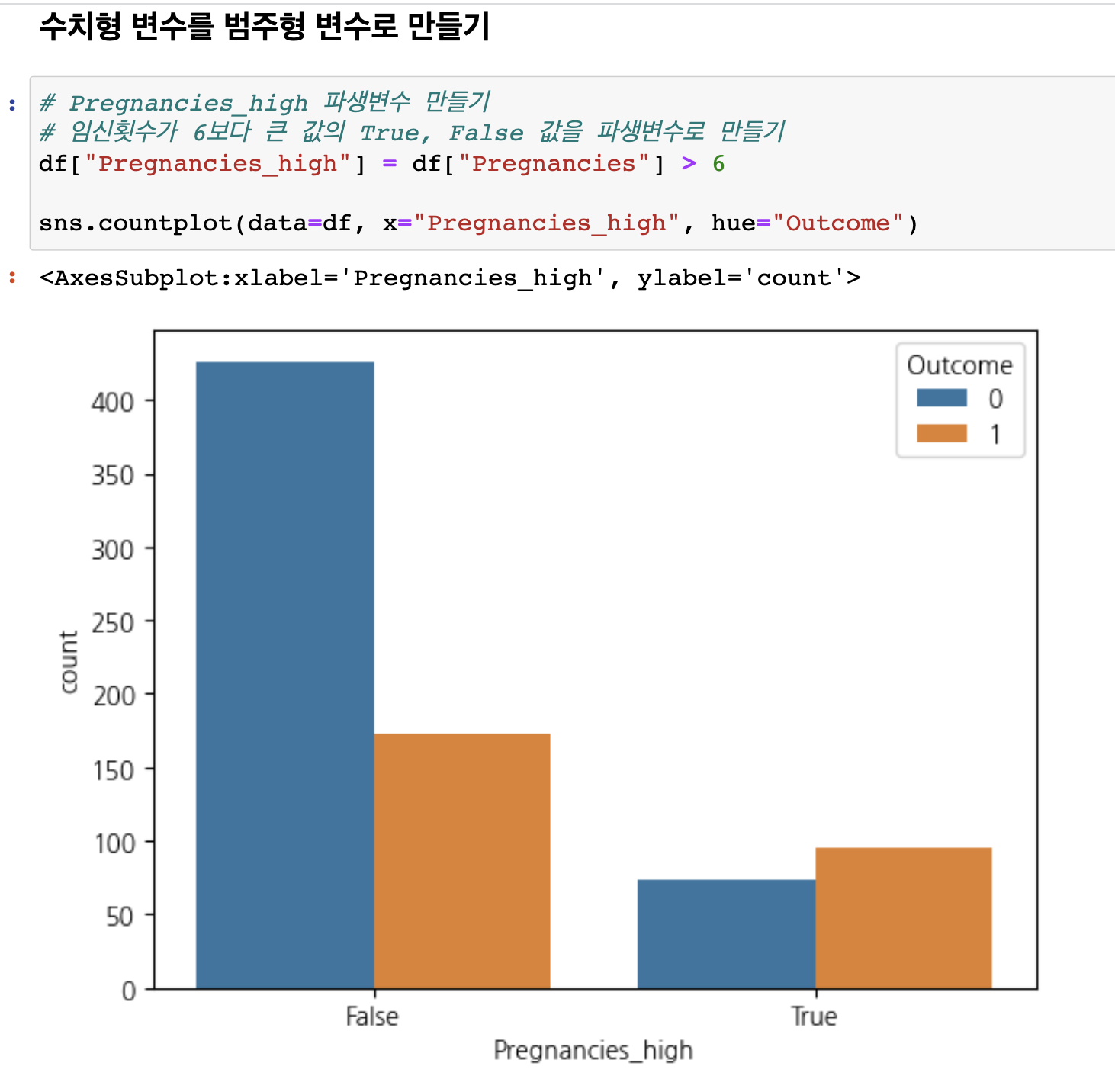
수치형 변수를 그대로 안 쓰고 범주형 변수로 만들어 주었을까요?
머신러닝 알고리즘에 힌트를 줄수도 있고 오버피팅을 방지할 수도 있습니다.

팀장이재모