
배경
출퇴근 중에 떠오르는 개발 아이디어를 즉시 구현까지 이어지게 하고 싶었다. Ghost Dev라는 프로젝트를 만들어서, 아이디어가 생기면 티켓을 생성하고 Claude API가 자동으로 기능을 구현해주는 흐름을 만들었다.
그런데 실행할 때마다 돈이 나간다. 토큰을 줄이는 게 최우선 과제가 됐다.
문제 분석: input 토큰이 왜 이렇게 많지?
Claude API의 토큰은 input과 output으로 나뉜다. 모니터링을 해보니 특히 input 토큰이 많이 차지하고 있었다.
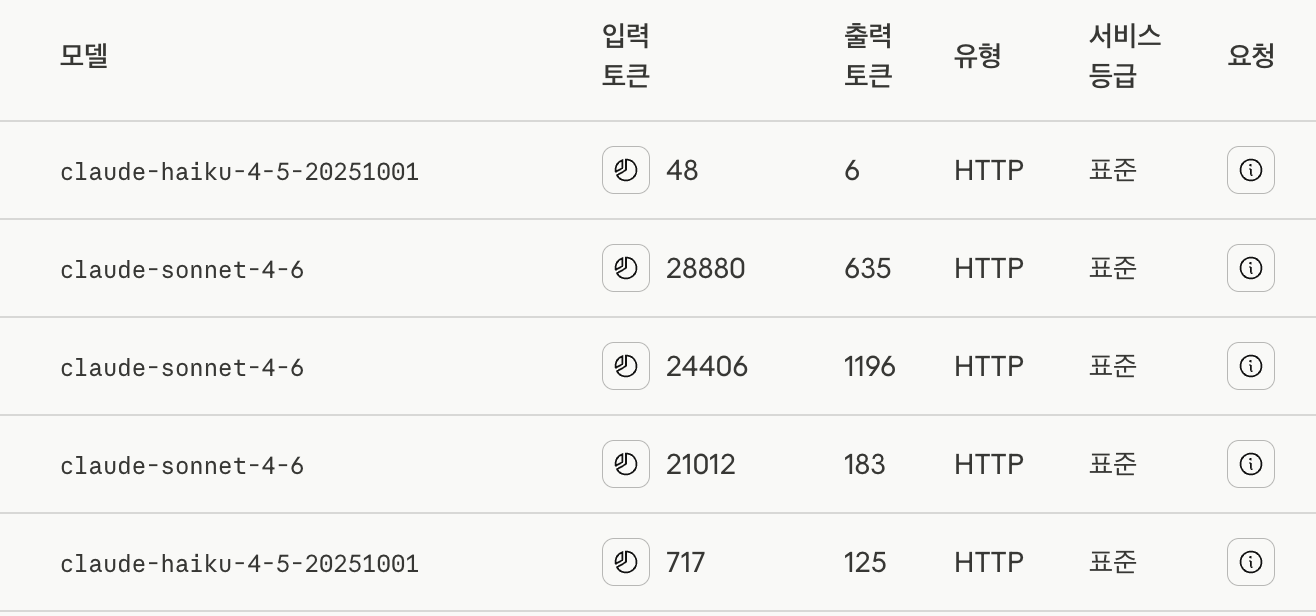
원인은 두 가지였다.
1. 누적되는 대화 히스토리
Vercel AI SDK에서 하나의 LLM 호출 사이클을 step이라고 한다.
LLM 호출 → 응답 생성 → 툴 호출 → 툴 결과 수신 → LLM 재호출AI는 이전 작업을 기억하지 못하기 때문에, 매 step마다 이전의 모든 메시지(tool call + tool result 포함)를 다음 input에 담아서 넘겨줘야 한다. step이 쌓일수록 input 토큰이 선형적으로 늘어나는 구조다.
2. 파일 읽기 결과의 누적
디렉토리 조회나 파일 읽기 결과가 길 경우, 이것도 전부 히스토리에 쌓인 채로 다음 step에 전달된다.
해결 방법 1: 병렬 파일 읽기
파일을 순차적으로 읽는 대신, 병렬로 읽어서 결과를 합치는 방식을 생각했다.
한계: A 파일을 읽어야 B 파일의 경로를 알 수 있는 경우엔 병렬화가 불가능하다. import 관계나 설정 파일 참조처럼 의존성이 있는 경우가 생각보다 많았다. 병렬화는 의존성이 없는 파일에만 적용할 수 있어서, 근본적인 해결책이 되지 못했다.
해결 방법 2: 이전 메시지 압축
step이 쌓이면 오래된 메시지를 압축해서 다음 step으로 넘기는 방식이다.
처음엔 압축하면 품질이 떨어지지 않을까? 걱정했는데, 여러 실험 결과 step이 10개를 넘어간 시점부터 압축을 적용하면 품질 영향이 최소화된다는 걸 확인했다.
압축에는 Sonnet 대신 Haiku 모델을 사용해서 메시지를 요약하도록 했다. 이렇게 하면 요약 자체에 드는 비용도 낮출 수 있다.
또 다른 문제: 실패하면 처음부터 다시?
위 방법으로 실험하던 중 새로운 문제를 발견했다. 특정 상황에서 티켓 실행이 중간에 실패하는 경우가 있었는데, 재실행하면 처음부터 다시 시작되는 것이었다.
예를 들어 100만 토큰을 쓴 뒤 실패했다면, 재실행 시 다시 100만 토큰을 소비하게 된다. 토큰은 곧 돈이다.
해결 방법 3: Checkpoint + 임시 브랜치
두 가지를 조합해서 해결했다.
Checkpoint 저장
각 step이 끝날 때마다 현재 메시지 상태를 DB에 저장한다. 재실행 시 처음부터 시작하지 않고, 마지막 checkpoint부터 이어서 진행할 수 있다.
임시 브랜치 활용
파일을 수정하다가 에러가 발생할 수도 있다. 수정된 파일 상태도 보존해야 재개가 가능하기 때문에, ticketId 기반의 임시 브랜치를 만들어서 변경 사항을 커밋해둔다. 재실행 시 해당 브랜치가 존재하면 그 브랜치로 이동해 작업을 이어간다.
정리
| 문제 | 해결책 |
|---|---|
| step마다 히스토리 누적 | Haiku로 오래된 메시지 압축 |
| 파일 읽기 비용 | 의존성 없는 파일은 병렬 읽기 |
| 실패 시 처음부터 재시작 | DB checkpoint + 임시 브랜치 저장 |
정확히 같은 조건의 비교는 아니지만, 비슷한 난이도의 작업에서 이 정도 차이가 난다면 충분히 의미 있는 결과라고 본다.
before / after
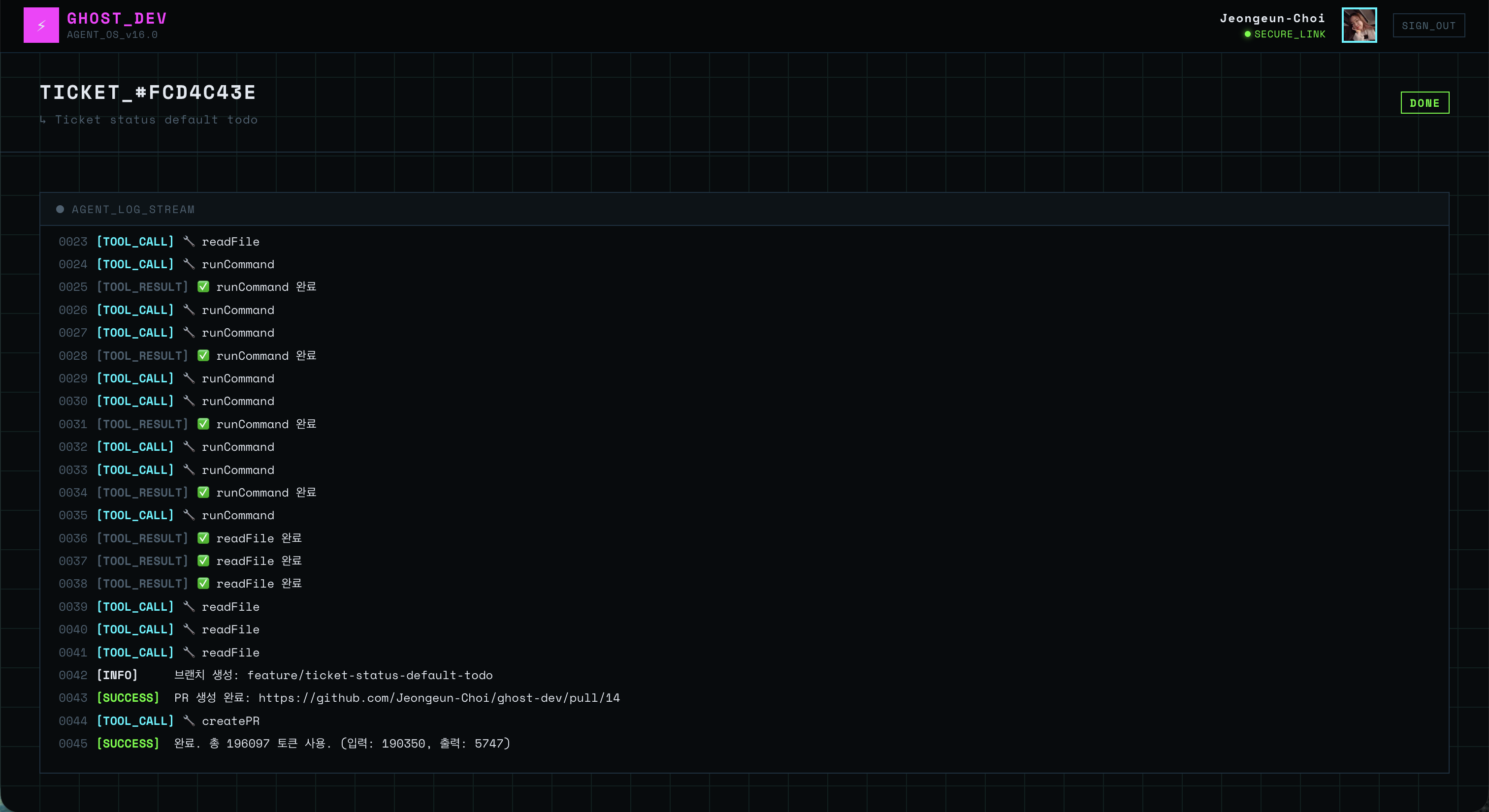 ↑ input 토큰 19만개
↑ input 토큰 19만개
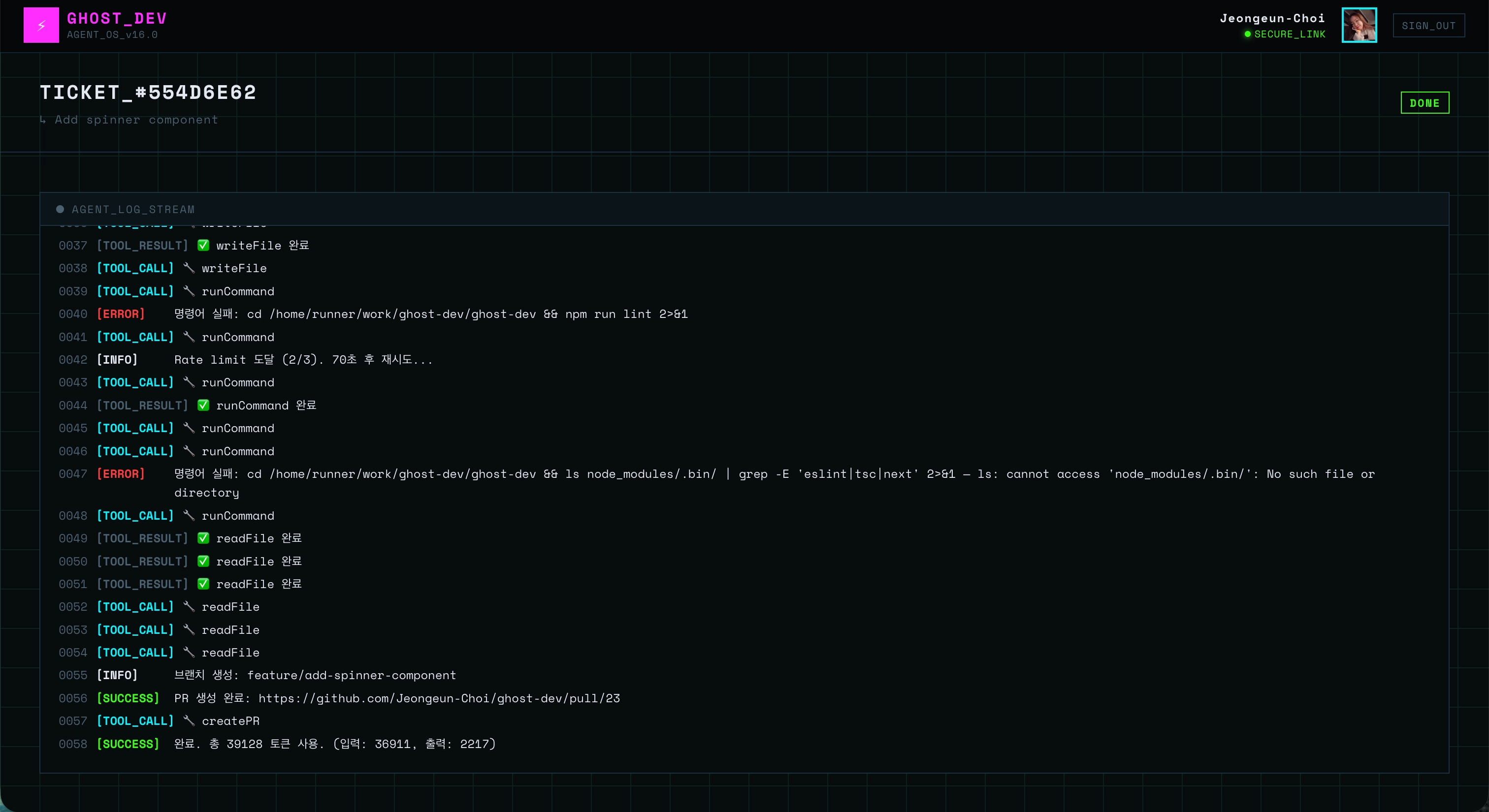 ↑ input 토큰 3만개
↑ input 토큰 3만개
결국 토큰 최적화는 단순히 "덜 보내기"가 아니라, 언제 압축하고 언제 재개할지를 설계하는 문제였다.
