Chapter 2. 데이터 다루기
02-1 훈련 세트와 테스트 세트
더 좋은 모델을 만들기 위해서는 데이터가 중요하다.
데이터의 비율, 특성 등 다양한 요소로 인해 모델 성능에 미치는 영향은 다양하다.
그래서, 머신러닝의 정확한 평가를 위해 데이터를 훈련 세트와 테스트 세트로 나누는 방법을 알아보고자 한다.
지도 학습과 비지도 학습
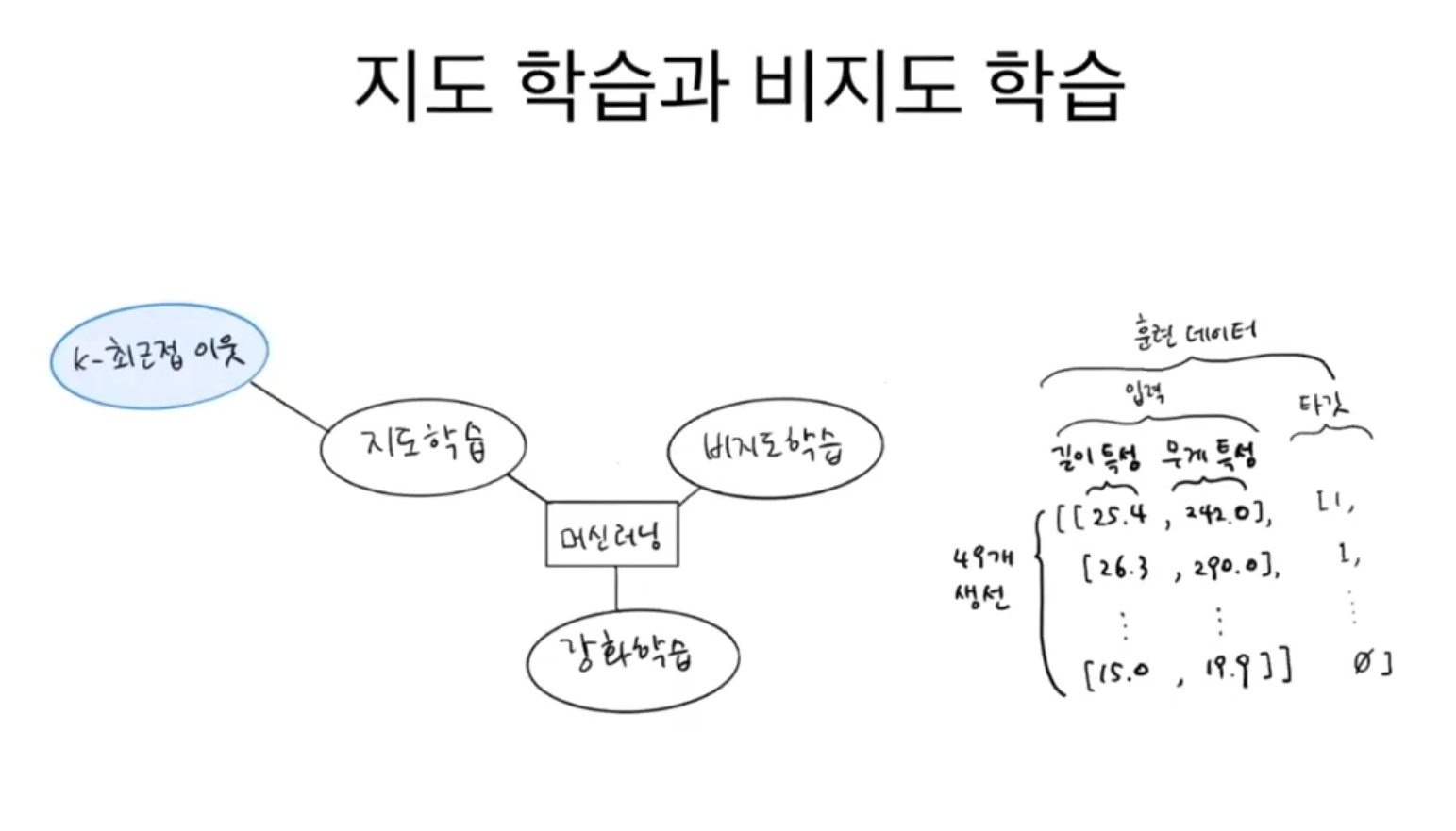
머신러닝 알고리즘은 크게 지도 학습(supervised learning)과 비지도학습(unsupervised learning)으로 나눌 수 있다.
✅ 용어 설명
- 지도 학습(supervised learning) : 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용한다. 1장에서부터 사용한 K-최근접 이웃이 지도 학습 알고리즘이다.
- 비지도학습(unsupervised learning) : 타깃 데이터가 없다. 따라서 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특징을 찾는데 주로 활용한다.
- 강화학습(reinforcement learning) : 타깃이 아니라 알고리즘이 행동한 결과로 얻은 보상을 사용해 학습한다.
정리하자면, 지도 학습은 정답(타깃)이 있으니 알고리즘이 정답을 맞히는 것을 학습한다.
그래서 지도 학습은 입력(데이터)과 타깃(정답)으로 이뤄진 훈련 데이터가 필요하다.
다만, 비지도 학습 알고리즘은 타깃 없이 입력데이터만 사용한다.
훈련 세트와 테스트 세트
머신러닝의 정확한 평가를 위해서는 테스트 세트와 훈련 세트가 따로 준비되어야 한다.
✅ 용어 설명
- 훈련 세트 : 모델을 훈련할 때 사용하는 데이터이다. 보통 훈련 세트가 클수록 좋다. 따라서 테스트 세트를 제외한 모든 데이터를 사용한다.
- 테스트 세트 : 전체 데이터에서 20~30%를 테스트 세트로 사용하는 경우가 많다. 전체 데이터가 아주 크다면 1%만 덜어내도 충분하다.
아래의 데이터를 훈련 세트와 테스트 세트로 나눠보자.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]우선, 2차원 리스트로 먼저 만든다.
fish_data = [[l, w] for l, w in zip(fish_length, fish_weight)]
fish_target = [1] * 35 + [0] * 14리스트의 슬라이싱 연산자를 사용하여 훈련 세트와 테스트 세트를 만든다.
# 훈련 세트로 입력값 중 0부터 34번째 인덱스까지 사용
train_input = fish_data[:35]
# 훈련 세트로 타깃값 중 0부터 34번째 인덱스까지 사용
train_target = fish_target[:35]
# 테스트 세트로 입력값 중 35번째부터 마지막 인덱스까지 사용
test_input = fish_data[35:]
# 테스트 세트로 타깃값 중 35번째부터 마지막 인덱스까지 사용
test_target = fish_target[35:]위와 같이 훈련 세트와 테스트 세트를 나눠보았으니, 모델을 훈련시켜 평가해보자.
kn = kn.fit(train_input, train_target) # 훈련 데이터 세트로 모델 훈련하고고
kn.score(test_input, test_target) # 테스트 데이터 세트로 모델 평가
>>> 0.0결과가 0.0이 나왔다. 어떻게 된 것일까?
샘플링 편향 문제 발생 😯
일반적으로 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향이라고 말한다.
- 특정 종류의 샘플이 과도하게 많은 샘플링 편향을 가지고 있다면 제대로 된 지도 학습 모델을 만들 수 없다.
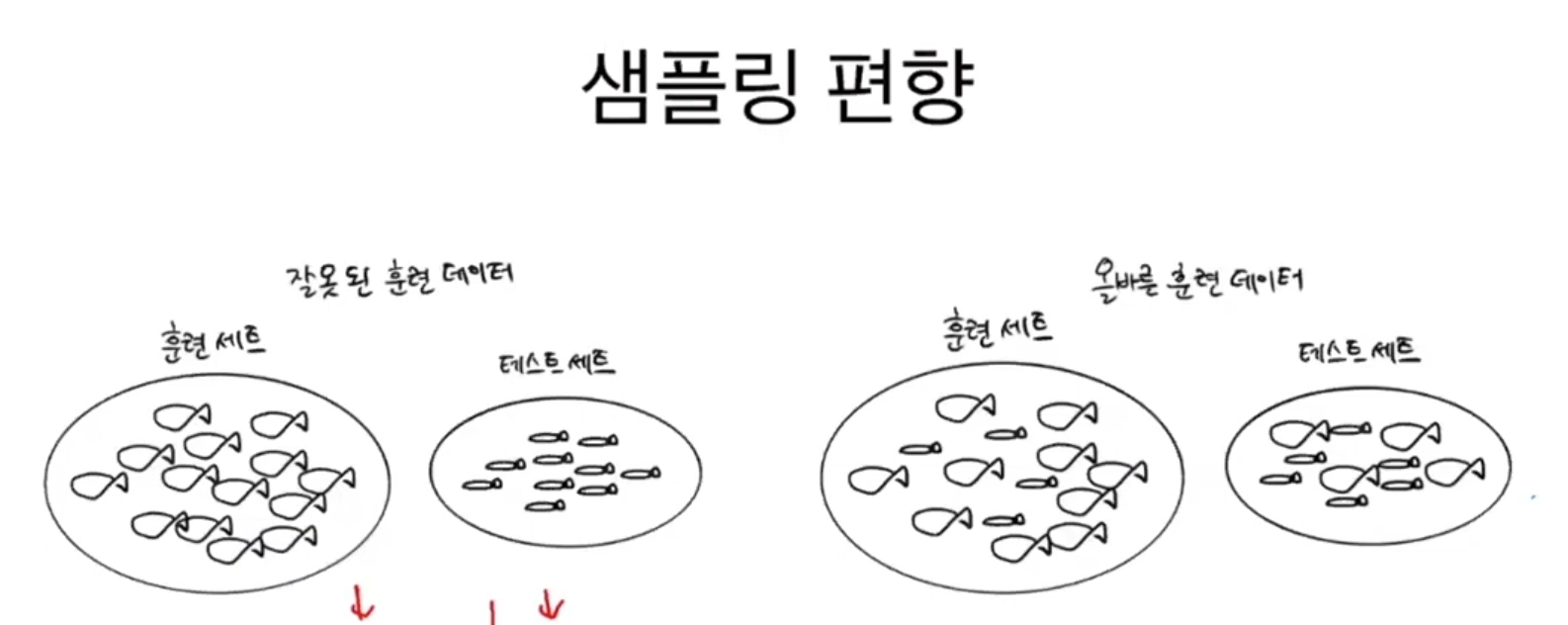
도미와 빙어를 잘 구분하고 싶다면 잘 섞인 샘플 데이터를 사용해야한다.
넘파이 (numpy)
넘파이는 파이썬의 대표적인 배열 라이브러리이다.
넘파이는 고차원의 배열을 손쉽게 만들고 조작할 수 있는 간편한 도구를 많이 제공한다.
numpy라이브러리를import하고 2차원 배열을 만들자.
import numpy as np
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)앞서 샘플링 편향 문제를 해결하기 위해 numpy라이브러리를 사용하여 랜덤하게 샘플을 선택해 훈련 세트와 테스트 세트를 만들어보고자 한다.
본 책에서는 배열을 섞은 후에 나누는 방식 대신에 무작위로 샘플을 고르는 방법을 사용하였다.
np.random.seed(42) # 일정한 결과를 얻기 위해 시드 설정
index = np.arange(49)
np.random.shuffle(index) # 주어진 배열 섞음여기서 사용된 random.seed() 함수는 넘파이에서 난수를 생성하기 위한 정수 초깃값을 지정하는 함수이다. 초깃값이 같으면 동일한 난수를 뽑을 수 있다. 따라서 랜덤 함수의 결과를 동일하게 재현하고 싶을 때 사용한다.
본 책에서는 일정한 결과를 얻기 위해 random seed를 42로 설정하였다.
또한, shuffle() 함수는 주어진 배열을 랜덤하게 섞는 함수이다. 다차원 배열일 경우 첫 번째 축(행)에 대해서만 섞는다.
완성된 배열을 가지고 슬라이싱 연산자를 통해 훈련 세트와 테스트 세트를 나눠보자.
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]데이터가 잘 섞인지 시각화하여 확인하였다.
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(test_input[:,0], test_input[:,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()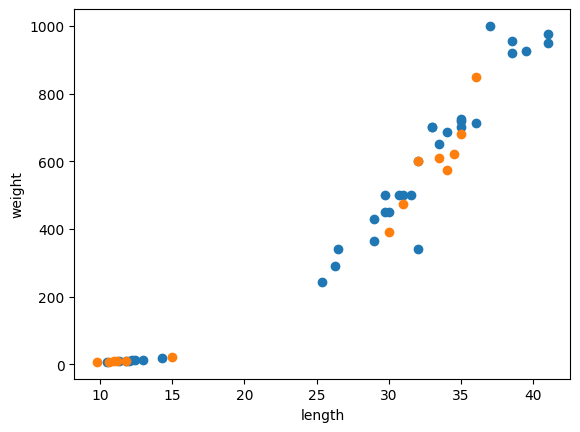
여기서 잠깐! 🤚 배열 인덱싱이란?
- 넘파이는 슬라이싱 외에 배열 인덱싱이란 기능도 제공한다.
- 배열 인덱싱은 1개의 인덱스가 아닌 여러 개의 인덱스로 한 번에 여러 개의 원소를 선택할 수 있다.
print(input_arr[[1,3]]) # 두번째, 네번째 샘플 선택
>>>
[[ 26.3 290. ]
[ 29. 363. ]]이렇게 두 번째, 네 번재 샘플을 선택하거나
아님 행과 열로 표현하여 인덱스 접근이 가능하다.
test_input[:,0] # 전체 행에 관해 0번째 열의 값만 가져온다.[행, 열] 로도 표현가능하다.
두 번째 머신러닝 프로그램
KNN 모델을 사용하여 평가해보고자 한다.
kn = kn.fit(train_input, train_target)
kn.score(test_input, test_target)
>>> 1.0 # 정확도 100%마무리하며...
모델을 훈련할 때 사용한 데이터로 모델의 성능을 평가하는 것은 정답을 미리 알려주고 시험을 보는 것과 같다. 따라서 공정하게 점수를 매기기 위해서는 훈련에 참여하지 않은 샘플을 사용해야 한다.
이렇게 좋은 머신러닝 모델을 만들고자 하려면 데이터 부터 클린 해야한다는 점을 기억하자.
전체 소스 코드
JeongeunBae의 Github에서 전체 코드를 확인하실 수 있습니다. 😄
https://github.com/JeongEunBae/TIL/blob/main/Basic_ML_DL%20(%ED%98%BC%EA%B3%B5%EB%A8%B8%EC%8B%A0)/2_1_%ED%9B%88%EB%A0%A8_%EC%84%B8%ED%8A%B8%EC%99%80_%ED%85%8C%EC%8A%A4%ED%8A%B8_%EC%84%B8%ED%8A%B8.ipynb
