UTF-8 인코딩
유니코드
유니코드란 전세계의 모든 언어를 컴퓨터상에서 표현할 수 있도록 글자와 코드를 1:1로 맵핑한 표준 코드 입니다.
표준 체계 정의를 통해 사용자나 환경에 따라 문자가 다르게 표현되는일 없이 일관되게 사용할 수 있습니다.
유니코드 값을 나타내기 위해서는 코드 포인트를 사용합니다. 예를 들어, 'A'의 유니코드 값은 U+0041로 표현합니다.
유니코드는 공식적으로 31비트 문자집합이지만 현재까지는 21비트 이내로 모두 표현 가능합니다.
UTF-8
실제로 유니코드를 컴퓨터에서 사용하기 위해서는 컴퓨터가 이해할 수 있도록 인코딩 하여야 합니다. utf-8은 유니코드를 위한 문자 인코딩 방식 중 하나입니다.
-
utf-8은 가변 인코딩 방식
- 글자마다 byte 길이가 다름
- 가변을 구분하기 위해서는 첫 바이트에 표식을 넣음
- 1바이트는 그대로 인코딩
- 2바이트는 110으로 시작
- 3바이트는 1110으로 시작
- 나머지 바이트는 10으로 시작
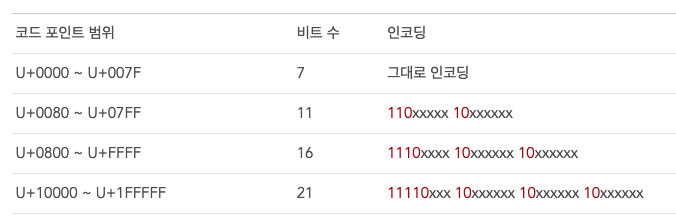
=> ASCII 문자들은 코드포인트 범위 U+0000 ~ U+007F에 맵핑되므로 1바이트로 그대로 표현
- 한글의 경우 초성,중성,종성을 각 1바이트로 인식하는 조합형 방식
[참고][네이버 D2 - 한글 인코딩의 이해 2편: 유니코드와 Java를 이용한 한글 처리](https://d2.naver.com/helloworld/76650)

제리하이웨이