일단 Medical AI 분야로 가기 위해서는 딥러닝에 대한 이해가 필요할 것 같다는 생각이 들었다.
사실 2020년도 부터 2021년도까지 대략 1년 정도 데이터 분석 인턴을 했었는데...
그 때 당시에 감성분석을 위해 딥러닝을 공부 했었다.(LLM이 세상에 나오기 전...)
LSTM을 주로 공부를 했었는데 사실 제대로 했었던 것 같진 않았다...
어찌됐든 회사이다 보니 빠르게 성과를 냈어야 했고 기술을 빠르게 응용하기 위해서 한 공부여서
중간중간 구멍이 좀 뚫려있는 것 같다는 느낌을 받았다.
그래서 이번 기회에 다시 기초부터 제대로 공부해보려 한다.
딥러닝(DL)이란?
딥러닝(DL)이란 무엇일까?
딥러닝(DL)을 알기 전에 인공지능(AI), 머신러닝(ML)은 무엇이며 무슨 관계인지를 먼저 알아보면 좋을 것 같다.
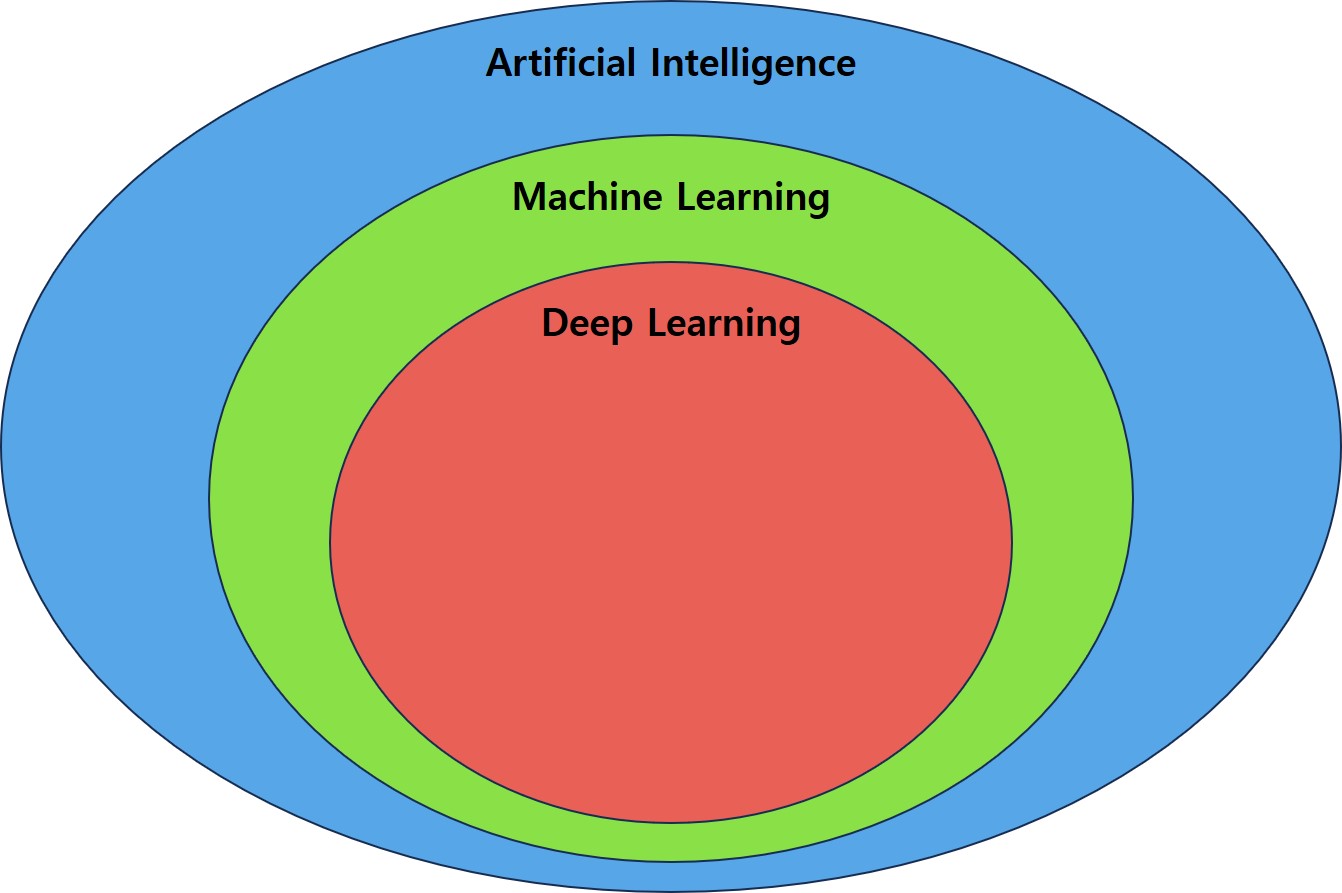
인공지능(AI), 머신러닝(ML)은 무엇이며 무슨 관계인가?
인공지능(AI) 은 사람의 지능적 행위를 컴퓨터가 모방하는 기술로 머신러닝(ML), 딥러닝(DL) 그리고 LLM(Large Language Model) 등을 포괄하는 큰 개념이다. 머신러닝(ML)은 인공지능(AI)의 한 분야로, 주어진 데이터에서 컴퓨터가 스스로 규칙을 찾아 학습하는 방법이다.
딥러닝(DL)은 인공지능(AI)과 머신러닝(ML)의 하위 분류이며, 사람의 지능을 모방한 신경망 구조를 이용한 인공지능 방법론이다.
머신러닝(ML)과 딥러닝(DL) 차이점
자, 그렇다면 머신러닝(ML)과 딥러닝(DL)은 어떤 차이가 있을까?
| 구분 | 머신러닝(ML) | 딥러닝(DL) |
|---|---|---|
| 데이터 처리 | 사람이 특성을 설계해야 함(Feature Engineering | 특성을 스스로 찾아냄 |
| 알고리즘 구조 | 선형 회귀, 결정 트리 같은 비교적 간단한 알고리즘 | 신경망(Neural Network) |
| 성능 | 데이터가 비교적 적어도 동작 가능 | 데이터가 많을수록 성능이 좋아짐 |
| 복잡도 | 비교적 가벼운 계산 | 많은 계산과 GPU 같은 고성능 장치 필요 |
| 응용 분야 | 추천 시스템, 가격 예측 등 | 음성 인식, 이미지 분석, 자율주행, 자연어 처리 등 |
머신러닝(ML)과 딥러닝(DL)은 데이터 처리 방식, 알고리즘 구조, 성능, 복잡도, 응용 분야에서 차이점이 있다.
우선, 데이터 처리 방식에서 머신러닝은 사람이 직접 데이터를 분석하고 중요한 특성을 설계해야 한다. 즉 Feature Engineering이 들어가야 한다는 것이다. 예를 들어 집 가격 예측 모델을 만들 때, 집의 크기, 위치, 방 수와 같은 특성을 정해주어야 한다.
반면, 딥러닝은 데이터를 주면 그 특성을 스스로 학습하고 추출할 수 있어 이미지나 음성 데이터처럼 사람이 정의하기 어려운 복잡한 데이터를 처리하는 데 강점이 있다.
알고리즘 구조에서 머신러닝은 비교적 간단한 알고리즘인 선형 회귀나 결정 트리 같은 기법을 사용한다. 이런 알고리즘은 계산이 빠르고 간단하게 예측할 수 있지만, 복잡한 데이터에서는 성능의 한계가 있을 수 있다.
딥러닝은 신경망(Neural Network) 구조를 사용하여 여러 층을 통해 데이터를 더욱 세밀하게 분석하고 패턴을 추출한다. 그러나 많은 계산량이 필요하고, 고성능의 장치가 필요해 계산에 시간이 많이 소요된다는 단점이 있다.
성능면에서는 머신러닝은 적은 데이터로도 성능을 낼 수 있다. 물론 데이터가 많으면 많을수록 성능은 더욱 향상되지만 그것에 한계가 존재한다.
반면, 딥러닝은 대량의 데이터에서 성능이 크게 향상되며, 데이터가 많으면 많을수록 학습의 성능이 좋아지므로 이미지 분석이나 자연어 처리 같은 방대한 데이터가 필요한 문제에 적합하다고 할 수 있다.
복잡도 측면에서 머신러닝이 상대적으로 가벼운 계산을 요구하고 고성능 장치 없이도 동작할 수 있어 간단한 문제 해결에 적합하다. 하지만 딥러닝은 복잡한 신경망을 훈련시키기 위해 많은 계산 자원과 GPU 같은 고성능 장치가 필요하며, 모델 훈련에 꽤 오랜 시간이 걸릴 수 있다.
마지막으로, 응용 분야에서 머신러닝은 추천 시스템, 가격 예측, 간단한 분류 문제 등과 같이 비교적 적은 데이터로 잘 동작하는 문제에 주로 사용된다.
반면, 딥러닝은 음성 인식, 이미지 분석, 자율주행, 자연어 처리 등 데이터가 방대하고 복잡한 문제를 해결하는 데 주로 사용된다.
머신러닝(ML)과 딥러닝(DL)은 각각의 강점이 다르며, 문제의 특성에 맞춰 선택하여 사용하는 것이 중요하다.
딥러닝(DL)의 구조와 모델
지금까지 딥러닝(DL)에 대해 대략적으로 알아보았다.
이제부터 딥러닝(DL)의 가장 큰 특징인 신경망(Neural Network)과 여러 모델에 대해 간략하게 알아보고자 한다.
신경망(Neural Network)
딥러닝(DL)의 가장 큰 특징은 신경망(Neural Network)을 통한 학습 방식이다.
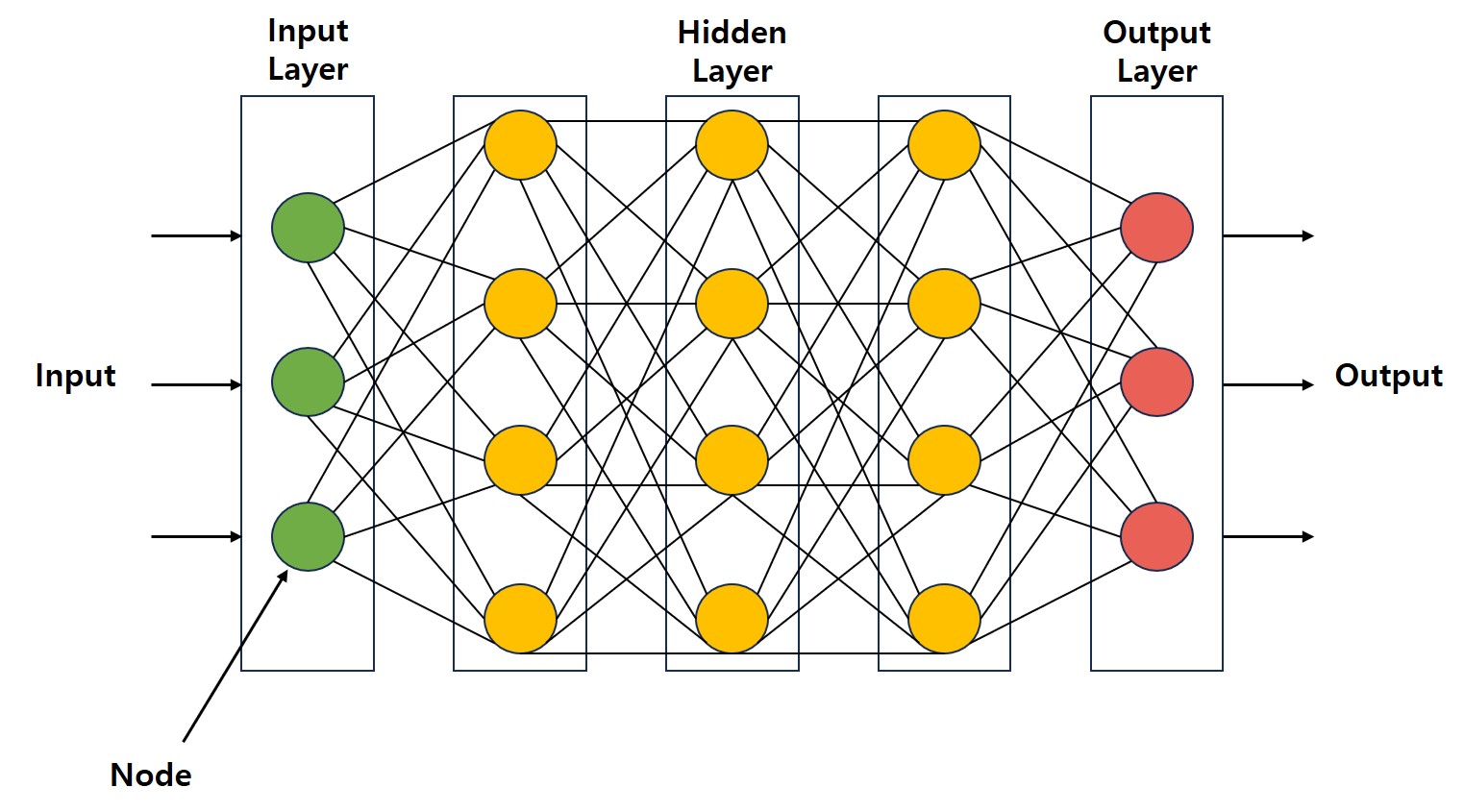
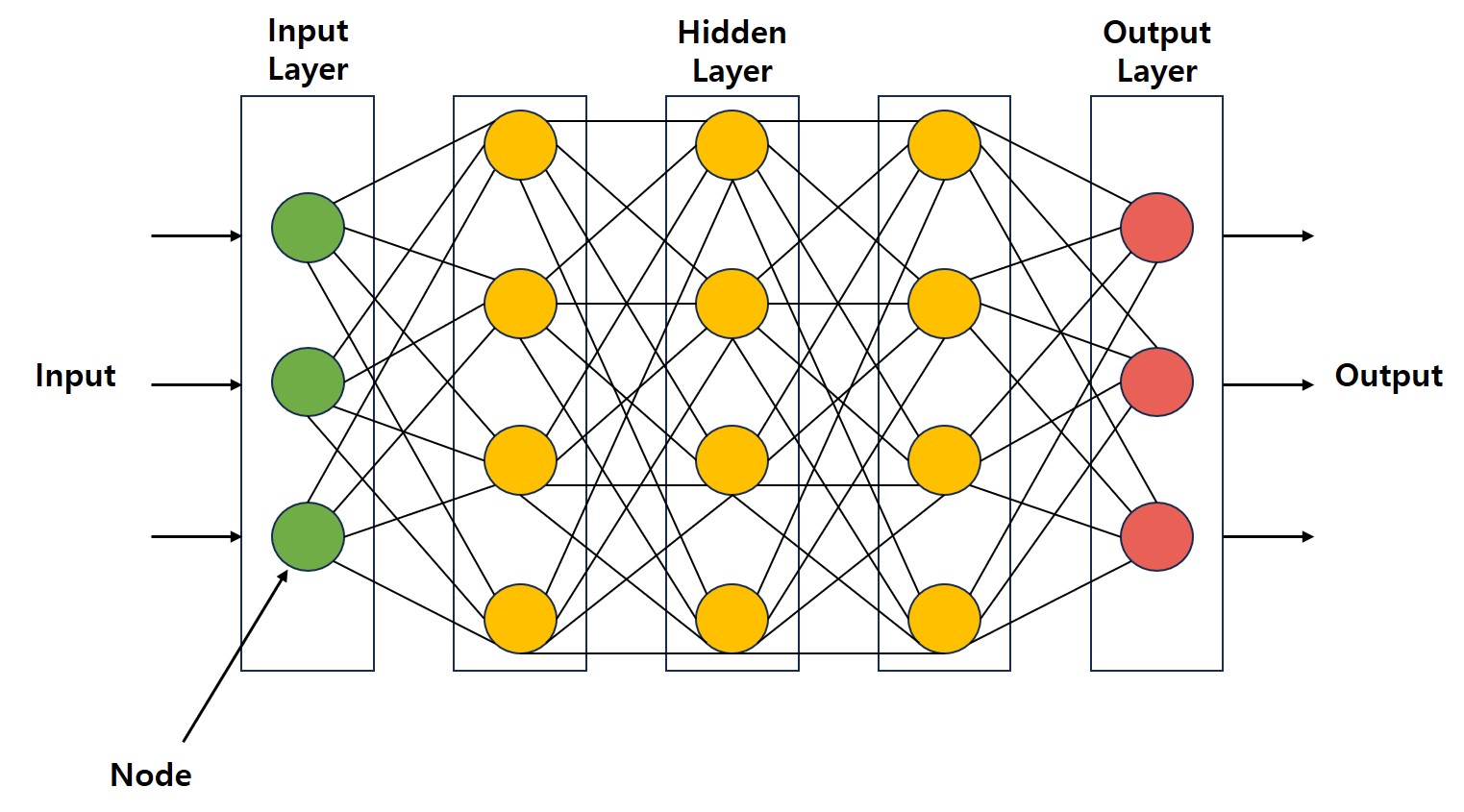
딥러닝(DL)의 신경망(Neural Network)은 인간의 신경망 구조를 모방한 것으로 딥러닝에서는 이것을 인공신경망(Artificial Neural Network) 또는 퍼셉트론(Perceptron)이라 한다.
인공신경망은 여러 개의 노드(Node)와 층(Layer)으로 구성되어 있으며, 각 노드는 입력된 데이터를 처리하고 그 결과를 다음 층으로 전달하는 방식으로 작동한다.
인공신경망은 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 이루어져 있으며, 각 층은 여러 개의 노드로 구성된다.
-
입력층(Input Layer): 인공신경망의 첫 번째 층으로, 외부에서 들어오는 데이터를 받는 역할을 한다.
-
은닉층(Hidden Layer): 입력된 데이터를 처리하는 중간 층으로, 해당 층의 수와 노드의 수에 따라 인공신경망의 성능과 복잡도가 결정된다.
-
출력층(Output Layer): 모델의 최종 예측값이나 결과를 생성하는 층이다.
각 층의 노드는 가중치(Weight)와 편향(Bias)을 적용하여 입력을 변형한 후, 활성화 함수(Activation Function)를 통해 출력을 계산한다. 이 과정이 반복되면 인공신경망은 점차적으로 데이터를 잘 분류하거나 예측할 수 있도록 학습하게 된다.
인공신경망은 역전파(Backpropagation)라는 알고리즘을 통해 학습하는데, 이 알고리즘은 모델이 예측한 값과 실제 값 사이의 오차를 계산하고, 이를 바탕으로 가중치와 편향을 조정하여 모델을 개선한다.
이러한 방식으로 인공신경망은 복잡한 패턴을 학습하고, 다양한 데이터에 대한 예측을 수행할 수 있는 것이다.
딥러닝 모델
다음으로, 딤러닝의 대표적인 모델들에 대해 간략히 소개하고자 한다.
1. 합성곱 신경망(CNN, Convolutional Neural Network)
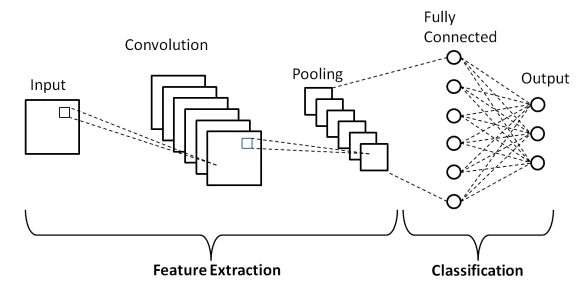
합성곱 신경망은 주로 이미지 처리에 좋은 성능을 보여주는 모델이다. CNN은 이미지에서 중요한 특징을 자동으로 추출할 수 있도록 설계된 모델로, 합성곱 층(Convolutional Layer), 풀링 층(Pooling Layer), 그리고 완전 연결층(Fully Connected Layer)으로 구성된다. 이미지 분류, 물체 인식, 얼굴 인식 등에서 널리 사용된다.
2. 순환 신경망(RNN, Recurrent Neural Network)
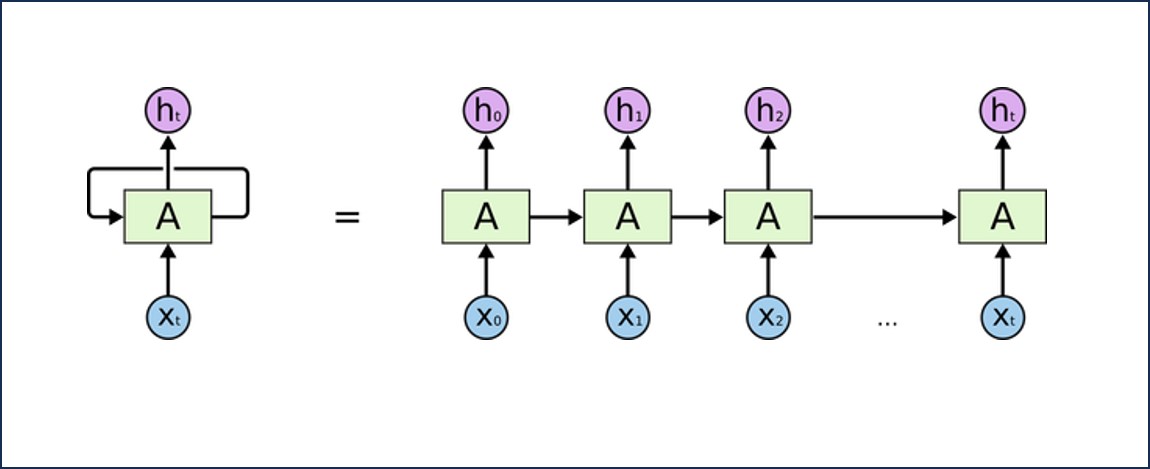
순환 신경망은 시퀀스 데이터를 처리하는 데 특화된 모델로, 이전 입력값을 기억하고 그 정보를 다음 시간 단계로 전달한다. RNN은 자연어 처리(NLP), 음성 인식, 주가 예측 등 시퀀스 형태의 데이터를 다룰 때 사용된다. 기본 RNN은 기울기 소실 문제(Vanishing Gradient Problem)를 겪기 때문에 이를 개선한 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit) 모델이 많이 사용된다.
3. 생성적 적대 신경망(GAN, Generative Adversarial Network)
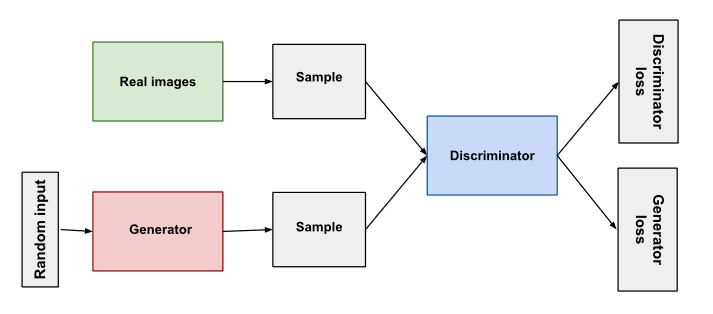
생성적 적대 신경망은 두 개의 신경망을 경쟁적으로 훈련시키는 모델로, 이미지 생성, 스타일 변환, 데이터 증강 등에 사용된다. 하나는 데이터를 생성하는 생성자(Genrator)이고, 다른 하나는 생성된 데이터가 진짜인지 가짜인지를 구별하는 판별자(Discriminator)이다. 이 두 네트워크는 서로 경쟁하면서 점점 더 진짜와 유사한 데이터를 생성하게 된다.
4. 트랜스포머(Transformer)
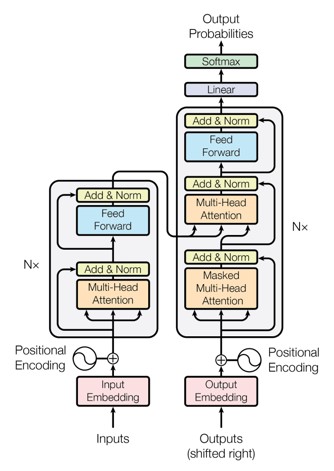
트랜스포머 모델은 자연어 처리(NLP) 분야에서 주로 사용되는 모델로, 시퀀스 데이터를 처리하는데 매우 효율적이다. 트랜스포머는 RNN을 대체할 수 있는 모델로, 어텐션 매커니즘(Attention Mechanism)을 사용하여 입력 데이터의 중요 부분을 강조하고, 병렬 처리 능력을 개선하여 성능을 높인다.
BERT, GPT, T5와 같은 모델들이 트랜스포머 아키텍처를 기반으로 하고 있다.
오늘은 딥러닝과 인공지능, 머신러닝의 관계와 머신러닝과 딥러닝의 차이점, 그리고 딥러닝의 기본 원리와 여러 모델들에 대해 간략히 알아보았다.
다음 시간에는 인공신경망에 대해 좀더 자세히 다뤄보고자 한다.
