2021-04-04
1.sql 언어 종류 ( DDL, DML ,DCL) ALTER TABLE / PK 조건 ,FK 조건
-
DDL
데이터베이스를 정의하는 언어로 데이터를 생성하거나 수정, 삭제 등 전체 골격을 결정하는 언어
-
CREATE
데이터베이스, 테이블 등을 생성하는 역할
-
ALTER
테이블을 수정하는 역할
-
DROP
데이터베이스, 테이블을 삭제하는 역할
-
TRUNCATE
테이블을 초기화 시키는 역할
-
-
DML
정의된 데이터베이스에 입력된 레코드를 조회, 수정, 삭제 하는 언어
⇒ 테이블에 있는 행과 열을 조작하는 언어
데이터베이스 사용자가 SQL을 통하여 저장된 데이터를 처리하는데 사용하는 언어
1.SELECT
데이터를 조회하는 역할
2.UPDATE
데이터를 삽입하는 역할
3.DELETE
데이터를 삭제하는 역할
-
DCL ( DATA CONTROL LANGUAGE )
데이터베이스에 접근 하거나 객체에 권한을 주는 언어
⇒데이터를 제어하는 언어
-
GRANT
특정 데이터베이스 사용자에게 작업에 대한 권한을 부여
-
REVOKE
특정 데이터베이스 사용자에게 작업에 대한 권한 박탈, 회수
-
-
TCL ( TRANSACTION CONTROL LANGUAGE )
트랜잭션을 제어하는 언어
-
COMMIT
트랜잭션 처리가 정상적으로 종료되어 트랜잭션이 수행한 변경 내용을 데이터베이스에 반영하는 연산
-
ROLLBACK
트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관선이 깨졌을떄, 트랜잭션이 행한 모든 변경 작업을 취소하고 이전 상태로 돌리는 연산
자원, 잠금(LOCK)을 모두 반환한다.
-
SAVEPOINT
SAVEPOINT는 현재의 트랜잭션을 작게 분할하는 명령어 입니다.
저장된 SAVEPOINT는 ROLLBACK TO SAVEPOINT문을 사용하여 지정한 곳까지 ROLLBACK 할 수 있습니다.
여러개의 SQL문을 수반하는 트랜잭션의 경우, 사용자가 트랜잭션 중간 단계에서 SAVEPOINT를 지정할 수 있습니다.
SAVEPOINT 유의사항
-
SAVEPOINT 후 COMMIT연산을 하게 된다면, COMMIT 연산 이전에 만든 SAVEPOINT들은 모두 사라지게 됩니다.
-
SAVEPOINT는 여러개 생성할 수 있습니다.
-
-
PK(Primary Key)와 FK(Foreign Key)는
테이블의 필수 요소로써 모든 테이블은 이들 둘 중 하나 이상을 반드시 포함하고 있다.
-
PK( PRIMARY KEY )
- 테이블을 생성할 때 PK를 정의한다.
- PK는 각 행을고유하게 식별하는 역할을 담당한다.
- 테이블당 하나만 정의 가능하다.
- 지정된 컬럼에는 중복된 값이나 NULL값이 입력될 수 없다.
- NOT NULL + UNIQUE(UK)를 한 것과 같은 기능을 한다.
- PK로 지정 가능한 컬럼이 여러 개 있을 때는 검색에 많이 사용되고 간단하고 짧은 컬럼을 지정한다.
- 주 식별자, 주키 등으로 불린다.
- 고유 인덱스(Unique index)가 자동으로 생성된다.
- 생성 방법 1
CREATE TABLE 테이블(
CONSTRAINT 제약조건이름 PRIMARY KEY (컬럼)
);
- 생성 방법 2
CREATE TABLE 테이블(
컬럼 데이터타입 CONSTRAINT 제약조건이름 PRIMARY KEY,
-
FK ( FOREIGN KEY )
- FK가 정의된 테이블이 자식 테이블이다.
- 참조되는 테이블을 부모 테이블이라고 한다.
- 부모 테이블은 미리 생성되어 있어야 한다.
- 부모 테이블의 참조되는 컬럼에 존재하는 값만을 입력 할 수 있다.
- 부모 테이블은 FK로 인해 삭제가 불가능하다.
- REFERENCES : 참조할 부모 테이블과 부모 테이블에 있는 컬럼을 정의한다.
- ON DELETE CASCADE : 참조되는 부모 테이블의 행에 대한 DELETE를 허용한다.
- 부모 테이블의 행이 지워지면 자식 테이블의 행도 같이 지워진다.
- ON DELETE SET NULL : 참조되는 부모 테이블의 행에 대한 DELETE를 허요한다.
- 부모 테이블의 행이 지워지면 자식 테이블의 행은 NULL 값으로 설정된다.
- 데이터 타입이 반드시 일치해야 한다.
- 참조되는 컬럼은 PK이거나 UK(Unique key)만 가능하다.
- 외부키, 참조키, 외부 식별자 등으로 불린다.
- 생성 방법 1
CREATE TABLE 테이블(
CONSTRAINT 제약조건이름 FOREIGN KEY (컬럼)
REFERENCES 참조할테이블 (참조할컬럼)
[ON DELETE CASCADE | ON DELETE SET NULL]
);
- 생성 방법 2
CREATE TABLE 테이블(
컬럼 데이터타입 CONSTRAINT 제약조건이름 FOREIGN KEY
REFERENCES 참조할테이블 (참조할컬럼)
[ON DELETE CASCADE | ON DELETE SET NULL]
2.SQL 실행 순서
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
3. WHERE 연산자 LIKE : \% %가 들어간 문자 찾을 경우, IN , IS NULL
IN
연산자는 조건의 범위를 지정하는 데 사용된다. 값은 콤마(,)로 구분하여 괄호 내에 묶으며, 이 값 중에서 하나 이상과 일치하면 조건에 맞는 것으로 평가된다.
NOT 연산자의 사용
- WHERE NOT USER_ID IN ( 'USER1' , 'USER2' )
- 조건을 부정할 때 사용되는 WHERE 절의 키워드
- NOT 연산자는 말그대로 바로 뒤에 오는 조건을 부정하는 역할을 한다. 때문에 혼자서는 되지 않는다.
- 다른 연산자와는 달리 필터링 할 열의 뒤가 아닌 앞에 사용된다.
IS NULL
- 컬럼에 들어 있는 값이 NULL 인지 아닌지 판단 하기 위한 연산자
- 해당 하는 값이 NULL 일때 조건을 만족, 반대 상황으로 IS NOT NULL이 존재한다.
4. 함수 - 날짜 , 숫자 , 문자 ,NULL값 체크 IF(), IFNULL() , CLALSESCE();
숫자
- ROUND (M,N) : M값을 N자리 까지 반올림 → N+1자리에서 반올림
- ROUND (M) : M값을 소수점 위로 반올림
- TRUNC(M,N) : M값에서 N미만 자리 버림 → N자리 까지 남음
- MOD (M, N) : M을 N으로 나눈 나머지 반환
- POWER(M,N) : M^N을 수행
- CEIL(M) : M보다 큰 가장 작은 정수를 출력
- FLOOR(M) : M보다 작은 가장 큰 정수를 출력
날짜
날짜 + 숫자 N → 해당 날짜에 N일자를 더한 날짜
날짜 - 숫자 N → 해당 날짜에 N일자를 뺸 날짜
날짜 + N/24 → 해당 날짜에 N시간을 더한 날짜
날짜 - 날짜 → 두 날짜 간의 차이 (일수)
데이터 변환 함수
TO_CHAR : 날짜나 숫자를 문자형으로 변환
→TO_CHAR(날짜, 출력형식) , TO_CHAR(숫자, 출력형식)
TO_DATE : 데이터를 날짜형으로 변환
→ TO_DATE (문자, 변환형식)
TO_ NUMBER : 데이터를 숫자로 해석MBER : 데이터를 숫자로 해석
NULL 함수
IFNULL
- 해당 Column의 값이 NULL을 반환할 때, 다른 값으로 출력할 수 있도록 하는 함수이다.
- SELECT IFNULL(Column명, "Null일 경우 대체 값") FROM 테이블명
IF()??
- Null 처리는 사실
IF함수와IS NULL조건으로도 가능하다. - // NAME Column이 NULL이 True인 경우 "No name"을, False인 경우는 NAME Column을 출력
SELECT IF(IS NULL(NAME), "No name", NAME) as NAME
FROM ANIMAL_INS
CASE
해당 Column 값을 조건식을 통해 True, False를 판단하여 조건에 맞게 Column값을 변환할 때 사용하는 함수이다.
- 기본 구조
CASE
WHEN 조건식1 THEN 식1
WHEN 조건식2 THEN 식2
...
ELSE 조건에 맞는경우가 없는 경우 실행할 식
ENDCOALESCE
COALESCE는 지정한 표현식들 중에 NULL이 아닌 첫 번째 값을 반환한다.모든 DBMS에서 사용가능
표현식은 여러 항목 지정이 가능하고, 처음으로 만나는 NULL이 아닌 값을 출력한다.표현식이 모두 NULL일 경우엔 결과도 NULL 반환
5. LIMIT 사용법 (5), (5,5)
LIMIT A,B → A번 인덱스 쿼리부터 B개만큼 출력하겠다는 의미
EX) LIMIT 3,3 : 3번 인덱스 컬럼부터 3개만 SELECT 한다.
6. GROUP BY - HAVING , ROLLUP-GROUPING
GROUP BY 절
- GROUP BY 절은 데이터들을 원하는 그룹으로 나눌 수 있다.
- 나누고자 하는 그룹의 컬럼명을 SELECT절과 GROUP BY절 뒤에 추가하면 된다.
- 집계함수와 함께 사용되는 상수는 GROUP BY 절에 추가하지 않아도 된다. (개발자 분들이 많이 실수 함)
HAVING 절
- WHERE 절에서는 집계함수를 사용 할 수 없다.
- HAVING 절은 집계함수를 가지고 조건비교를 할 때 사용한다.
- HAVING절은 GROUP BY절과 함께 사용이 된다.
ROLLU
-
ROLLUP 함수는 소그룹 간의 소계를 계산한다.
-
ROLLUP은 GROUP BY의 확장 형태로 사용하기 쉬운데, GROUP BY에 있는 항목들을 오른쪽에서 왼쪽순으로 그룹으로 묶어 집계를 낸다.
-
GROUP BY a, b, c, d 로 묶은 뒤 ROLLUP 을 적용시켜 주면
⇒ (a, b, c, d) / (a, b, c) / (a, b) / (a) / () 이런식으로 그룹을 만들어가며 집계를 낸다
-
- 방법1.
SELECT store, item, SUM(cnt) AS all_cnt, SUM(cost) AS all_cost
FROM sql_test_a
GROUP BY store, item WITH ROLLUP
-
- 방법2.
SELECT store, item, SUM(cnt) AS all_cnt, SUM(cost) AS all_cost
FROM sql_test_a
GROUP BY ROLLUP (store, item)
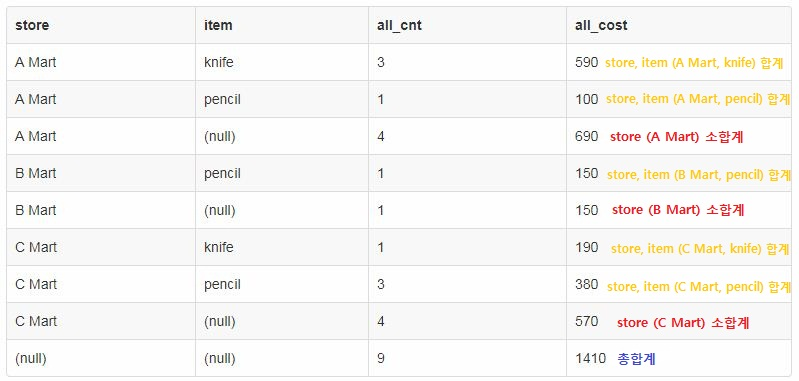
-
7. JOIN(IN , OUTTER, SELF) ON, USING, / WHERE로 조인 하는 방법
.png)
-
JOIN을 이용한 조인 방법
SELECT USER_ID
FROM USER_ID AS 'U' JOIN DEPT_ID AS 'D'
ON U.USER_ID = D.USER_ID
-
WHERE을 이용한 조인 방법
SELECT USER_ID
FROM USER_ID AS 'U' , DEPT_ID AS 'D'
WHERE U.USER_ID= D.USER_ID
8. SUBQUERY
서브 쿼리(subquery)
-
creat table, insert, delete , update,
-
select , from, where , having 에서 모두 가능하다select , from, where , having 에서 모두 가능하다
-
서브쿼리란 다른 쿼리 내부에 포함되어 있는 SELETE 문을 의미한다.
-
서브쿼리를 포함하고 있는 쿼리를 외부 쿼리(outer query) 또는 메인 쿼리라고 부르며 서브쿼리는 내부 쿼리(inner query)라고도 부른다.
-
서브쿼리는 비교 연산자 오른쪽에 존재 해야한다.
-
종류
중첩 서브 쿼리 → where 문제 작성하는 서브쿼리
인라인 뷰 → from 문에 작성하는 서브쿼리, 동적으로 생성된 테이블로 사용가능 , 저장 x
스칼라 서브쿼리 → select문제 작성하는 서브쿼리
-
주의사항
서브쿼리는 반드시 ()로 감싸야한다.
서브 쿼리는 단일 행 또는 다중 행 비교 연산자와 함께 사용된다.
서브쿼리에는 order by를 사용하지 못한다.
→서브쿼리와 조인이 가능한데 어떤것이 더 권장 사항인가 ? → case by case (보통 조인이 빠르다)
-
인라인 뷰-Top N
모든 사원의 사번, 이름 급여를 출력
사원 정보를 급여순으로 정렬
한 페이지당 5명이 출력
현제페이지가 3페이지라고 가정 → 급여 순 11등~15등가지 출력
-
인라인 뷰 -LImt 활용(MySQL)
-
스칼라 서브쿼리
select 절에 있는 서브쿼리
한 개의 행만 반환
- TCL . TX 시작, TX종료 -> COMMIT, ROLLBACK , SAVEPOINT
-
TCL ( TRANSACTION CONTROL LANGUAGE )
트랜잭션을 제어하는 언어
-
COMMIT
트랜잭션 처리가 정상적으로 종료되어 트랜잭션이 수행한 변경 내용을 데이터베이스에 반영하는 연산
-
ROLLBACK
트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관선이 깨졌을떄, 트랜잭션이 행한 모든 변경 작업을 취소하고 이전 상태로 돌리는 연산
자원, 잠금(LOCK)을 모두 반환한다.
-
SAVEPOINT
SAVEPOINT는 현재의 트랜잭션을 작게 분할하는 명령어 입니다.
저장된 SAVEPOINT는 ROLLBACK TO SAVEPOINT문을 사용하여 지정한 곳까지 ROLLBACK 할 수 있습니다.
여러개의 SQL문을 수반하는 트랜잭션의 경우, 사용자가 트랜잭션 중간 단계에서 SAVEPOINT를 지정할 수 있습니다.
SAVEPOINT 유의사항
-
SAVEPOINT 후 COMMIT연산을 하게 된다면, COMMIT 연산 이전에 만든 SAVEPOINT들은 모두 사라지게 됩니다.
-
SAVEPOINT는 여러개 생성할 수 있습니다.
-
-
10. INDEX 언제 써야하는지 , VIEW 사용 목적
VIEW
- 뷰란 하나의 가상테이블이라고 생각하면 된다. → 물리적인 저장 공간을 가지지 않음
- 뷰는 실제 데이터가 하드웨어에 저장되는 것은 아니지만 뷰를 통해 데이터를 관리할 수 있다.
- 뷰는 복잡한 Query를 얻을 수 있는 결과를 간단한 Query로 얻을 수 있게 한다.
- 한개의 뷰로 여러 테이블에 대한 데이터를 검색할 수 있다.
- 특정 평가 기준에 따른 사용자 별로 다른 데이터를 액세스할 수 있도록 한다.
⇒ 워크벤치를 껏다가 키면 뷰를 다시 만드는 쿼리가 실행되고 검색하는 sql 실행
⇒ 뷰를 access 하게 되면 간접적으로 테이블을 access하게 됨
⇒ 선택된 컬럼 정보만 참고 가능
VIEW의 사용 목적
- 보안관리를 목적으로 활용한다.(보안성)
- 사용상의 편의를 목적으로 활용한다.(편의성)
- 수행속도의 향상의 목적으로 활용한다.(속도 향상)
- SQL의 성능을 향상시킬 목적으로 활용한다.(활용성)
- 임시적인 작업을 위해 활용한다.
VIEW 문법
Create [or replace] view 뷰 이름
as sub-query
-
예시
Create view v_emp
As
Select empid,ename, sal
from emp
where deptid=20;
Index ( == 정렬 )
인덱스는 WHERE 절에서 효과가 있다
인덱스는 테이블의 동작 속도를 높여주는 자료 구조입니다.
인덱스로 데이터의 위치를 빠르게 찾아주는 역할을 합니다.
테이블 컬럼의 빠른 검색을 위해 사용하는 독립된 객체
⇒ 카디널리티가 높을 수록 인덱스 설정에 좋은 컬럼입니다.
= 한 컬럼이 갖고 있는 값의 중복 정도가 낮을 수록 좋습니다.
- 인덱스 생성 기준
- sql문의 where절에서 자주 사용되는 컬럼이 대상이 됨
- 빈번하게 변경되지 않는 테이블에 적용
- 데이터가 많은 테이블에 효과적
- 테이블 간 join에 사용되는 컬럼을 선정
PK의 경우 이미 index가 생성 되어 있다.
- index 생성
Create index i_emp_name on emp(fname);
- index 생성
-
수동 index
create index 구문으로 인덱스 생성ndex 구문으로 인덱스 생성
-
자동 index → PK, unique → 자동생성
11. ERD(Entity Relationship Diagram)
ERD는 개념 데이터 모델링 단계에서 작성하는 다이어그램
→ 개체(Entity), 속성(Attribute) , 관계(Relationship)로 구성된 ER Diagram으로 표현
-
실체(Entity) : 관리하고자 하는 정보의 실체
둥근 사각형으로 작성
Entity 이름은 단수형이고 유일하며 대문자로 크게 표기 할 것. ( )안에 동의어 표기 가능.
모든 Entity는 하나 이상의 식별자 (UID : Unique Identifier)을 가져야한다.
UID가 없다면 Entity가 아님
-
속성(Attribute) : Entity를 구성하고 있는 구성 요소
Attribute 이름은 소문자로 작게 표기할 것.
Entity 이름과 Attribute 이름이 같으면 안됨.
"#" 은 UID. "*"는 필수(Mandatory). "o"는 선택(Optional) Attribute를 의미
자신의 Attribute가 아니면서 Relation을 위해 자신의 Attribute로 표시해서는 안된다.
-
관계(Relationship) : Entity간의 관계
두 Entity 사이에 선을 긋고 관계 명칭을 기록한다.
선택 사항을 표시한다.
점선은 선택 (may be) 을 의미 (부서입장에서는 사원을 배치받을 수도 있고, 안받을 수도 있기 때문에)
실선은 필수 (must be) 를 의미 (사원입장에서는 반드시 부서에 배치되어야 하기 때문)
관계 형태를 표시한다.
새 발 모양은 하나 이상 (one or more) 을 의미 (사원 여러명이 한 부서에 속할 수 있기때문)
단 선은 단 하나 (one and only one) 를 의미 (한명의 사원은 한 부서에만 소속될 수 있다.)
12. 정규화
- 관계형 데이터베이스에서 중복을 최소화하기 위해 데이터를 구조화하는 작업
함수적 종속성
애트리뷰트 데이터들의 의미와 애트리뷰트들 간의 상호 관계로부터 유도되는 제약조건의 일종.
X 와 Y 를 임의의 애트리뷰트 집합이라고 할 때, X 의 값이 Y 의 값을 유일하게(unique) 결정한다면 "X는 Y 를 함수적으로 결정한다."라고 한다.
.png)
- 모든 제 2 정규형 릴레이션은 제 1 정규형을 갖는다.
- 모든 제 3 정규형 릴레이션은 제 2 정규형을 갖는다.
- 모든 BCNF 정규형 릴레이션은 제 3 정규형을 갖는다.
반 정규화 (De-normalization, 비정규화)
정규화된 엔티티, 속성, 관계를 시스템의 성능 향상 및 개발과 운영의 단순화를 위해 중복 통합, 분리 등을 수행하는 데이터 모델링 기법 중 하나이다.
복습시 E북 참조해서 볼 것
RDBMS ?
- 관계형(relational) 데이터베이스 시스템
- 테이블 기반(table based)의 DBMS.
- 테이터를 테이블 단위로 관리→ 하나의 테이블은 여러 컬럼으로 구성
- 중복 데이터를 최소화 시킴
- 같은 데이터가 여러 컬럼 또는 테이블에 존재 했을 경우, 데이터를 수정 시 문제가 발생할 가능성이 높아짐 → 정규화
- 여러 테이블에 분산되어 있는 데이터를 검색 시 테이블 간의 관계(join)를 이용하여 필요한 데이터를 검색분산되어 있는 데이터를 검색 시 테이블 간의 관계(join)를 이용하여 필요한 데이터를 검색
Table 의 개수= DTO의 개수
SQL(structured query Language)
database에 있는 정보를 사용 할 수 있도록 지원하는 언어
모든 DBMS에서 사용 가능
대소문자 구별 X → 단, 데이터의 대소문자는 구분
x로 시작한 → like x%
안에 %가 들어 있으면 \%로 확인
DML ( data Manipulation Language )
SELECT
-
CASE
CASE exp1 WHEN exp2 THEN exp3 (if문)
MYSQL 내장 함수
ABS(숫자) → 절대값
CEILING(숫자) → 값보다 큰 정수 중 가장 작은수 ( 올림 )
FLOOR(숫자) → 값보다 작은 정수중 가장 큰 수 ( 버림 )
ROUND(숫자) → 반 올림
TRUNCATE(숫자) → 숫자를 기준으로 버림
POW , POWER(X,Y) → X의 Y승
MOD(분자 , 분모) → 분자를 분모로 나눈 나머지
GREATEST → max
LEAST → min
-
문자관련 함수
-
CONCAT(문자열1, 문자열2,문자열3) → 문자열들을 결합
-
INSERT(문자열,시작위치 길이 , 새로운 문자열 → 시작위치부터 길이만큼 새로운 문자열로 대치
-
REPLACE (문자열, 기존문자열 , 바뀔문자열) → 문자열 중 기존 문자열을 바뀔 문자열로 변경
-
INSTR( 문자열, 찾는 문자열 ) → 문자열 중 찾는 문자열의 위치 값을 리턴
-
MID('문자열, 시작 위치, 개수 ) → 문자열 중 시작위치부터 개수만큼 리턴)
-
SUBSTRING(문자열 , 시작위치 , 개수) → 문자열 중 시작위치부터 개수만큼 리턴
-
LTRIM → 공백제거(왼쪽)
-
RTRIM → 공백제거 (오른쪽)
-
TRIM → 공백제거 (양쪽)
-
LEFT ('문자열', 개수)→ 문자열 중 왼쪽에서 개수만큼 추출
-
RIGHT(문자열, 개수)→ 문자열 중 오른쪽에서 개수만큼 추출
-
REVERSE(문자열) → 문자열을 반대로 나열
-
날짜 관련 함수
-
DATE_FORMAT(날짜, '형식') → 날짜를 형식에 맞게 리턴형식') → 날짜를 형식에 맞게 리턴
-
그룹(aggregate) 함수
-
COUNT (필드명) → NULL 값이 아닌 레코드 수를 리턴
-
SUM
-
AVG
-
MAX
-
MIN
JOIN
둘 이상의 테이블에서 데이터가 필요한 경우 테이블 조인이 필요
일반적으로 조인 조건을 포함하는 where 절을 작성해야한다.
조인 조건은 일반적으로 각 테이블의 pk및 fk로 구성됩니다.
-
종류
INNER JOIN ,
OUTER JOIN ( left, right)
-
join 조건의 명시에 따른 구분
NATURAL JOIN
CROSS JOIN(FULL JOIN) -
주의
조인의 처리는 어느 테이블을 먼저 읽을지를 결정하는것이 중요(작업량이 달라진다)
INNER JOIN : 어느 테이블을 읽어도 결과가 달라 지지 않는다. 옵티마이저가 최선의 순서를 맞춰줌NER JOIN : 어느 테이블을 읽어도 결과가 달라 지지 않는다. 옵티마이저가 최선의 순서를 맞춰줌
OUTER JOIN : 반드시 OUTER가 되는 테이블을 먼저 읽어야하므로 옵티마이저가 조인 순서를 선택 할 수 없다
-
Inner join → 기본적인 조인
-
natural join →알아서 조인할것을 찾아준다. natural join은 공통 column이 하나일때 사용하는것을 권장
-
outer join →
서브 쿼리(subquery)
-
creat table, insert, delete , update,
-
select , from, where , having 에서 모두 가능하다select , from, where , having 에서 모두 가능하다
-
서브쿼리란 다른 쿼리 내부에 포함되어 있는 SELETE 문을 의미한다.
-
서브쿼리를 포함하고 있는 쿼리를 외부 쿼리(outer query) 또는 메인 쿼리라고 부르며 서브쿼리는 내부 쿼리(inner query)라고도 부른다.
-
서브쿼리는 비교 연산자 오른쪽에 존재 해야한다.
-
종류
중첩 서브 쿼리 → where 문제 작성하는 서브쿼리
인라인 뷰 → from 문에 작성하는 서브쿼리, 동적으로 생성된 테이블로 사용가능 , 저장 x
스칼라 서브쿼리 → select문제 작성하는 서브쿼리
-
주의사항
서브쿼리는 반드시 ()로 감싸야한다.
서브 쿼리는 단일 행 또는 다중 행 비교 연산자와 함께 사용된다.
서브쿼리에는 order by를 사용하지 못한다.
→서브쿼리와 조인이 가능한데 어떤것이 더 권장 사항인가 ? → case by case (보통 조인이 빠르다)
-
인라인 뷰-Top N
모든 사원의 사번, 이름 급여를 출력
사원 정보를 급여순으로 정렬
한 페이지당 5명이 출력
현제페이지가 3페이지라고 가정 → 급여 순 11등~15등가지 출력
-
인라인 뷰 -LImt 활용(MySQL)
-
스칼라 서브쿼리
select 절에 있는 서브쿼리
한 개의 행만 반환
SET (집합 연산자)
- 모든 집합 연산자는 동일한 우선 순위를 갖는다
- select 절에 있는 column의 개수와 type이 일치해야한다.
- mysql 지원
- union → 두 쿼리에서 선택된 모든 행 반환 (중복은 한번만)
- union all → 두 쿼리에서 선택된 모든 행 반환( 모든 중복 포함)
- mysql 지원 (X)
- intersect → 두 쿼리에서 선택된 모든 중복행 반환
- minus → 첫번째 쿼리에서 선택한 행 반환 (중복행 제거)
검색
이름(name) → like 래미안
코드(code) → equals a123
매매가(price) → equals 1억
? 를 사용하는 치환 변수는 값에다가만 쓸수 잇다 → column 명은 불가능
GROUP BY CLAUSE
- select 문에서 group by 절을 사용하는 경우 데이터베이스는 쿼리 된 테이블의 행을 그룹으로 묶는다.
- 데이터베이스는 선택 목록의 집계 함수를 각 행 그룹에 적용하고 그룹에 대해 단일 결과 행을 반환한다.
- group by절을 생략하면 데이터베이스는 선택 목록의 집계함수를 쿼리 된 테이블의 모든 행에 적용합니다.
- select절의 모든 요소는 group by 절의 표현식, 집계 함수를 포함하는 표현식 또는 상수만 가능
- ⇒ select절에 잇는 요소들은 반드시 그룹바이에 들어 가있어야한다
memberDTO 와 memberDTO_Detail 이 있을때 Detail이 memberDTO를 상속 받아서 로그인을 할떄는 MemberDTO를 사용하고 정보를 수정 할때는 memberDTO_Detail 을 객채로 사용 하여서 할 수 있다.
→ 질답형 게시판엔 질문은 하나지만, 답변은 여러개가 등록될 수 있는데 질문 테이블과 답변 테이블을 따로 구성하고 게시글ID로 연결해주는게 맞나요?
데이터 모델링
모델링이라는 것은 우리 주변에 있는 사람, 사물, 개념 등 다양한 현상을 발생시키는 것들을 일정한 표기법에 의해 나타내는 것을 이야기 한다.
- 개념적 모델링: 개체와 개체들 간의 관계에서 ER다이어그램을 만드는 과정
- 논리적 모델링: ER다이어그램을 사용하여 관계 스키마 모델을 만드는 과정
- 물리적 모델링: 관계 스키마 모델의 물리적 구조를 정의하고 구현하는 과정
.png)
개념적 데이터 모델링(ERD) ⇒ 개념 스키마(ER-다이어 모델링(ERD) ⇒ 개념 스키마(ER-다이어그램)
- 고수준의 데이터 모델 (사람이 이해하는 수준)
- 전체 시스템에 대한 개념적인 정보를 나타내는 데 사용
- 개체-관계 모델 (ER model , entity-relationship model) 대표적인 개념적 데이터 모델이다.
엔티티 어트리뷰트 릴레이셔쉽을 포함 해야한다.
엔티티 ( 테이블 )
-
명사형
-
모델의 관리 대상
-
사람과 물건 , 장소 같은 실체가 있는 것이나 개념을 엔티티로 선택
-
시스템 구축 단계까지 진행되면 파일이나 데이터베이스의 테이블로 구현
-
ER 다이어그램에서는 사각형으로 표현
-
개체(Entity): 사람, 사물, 장소, 개념, 사건과 같이 유무형의 정보를 가지고 있는 독립적인 실체
-
데이터베이스에서 주로 다루는 개체: 낱개로 구성된 것으로 각각 데이터 값을 가지며 데이터 값이 변하는 것
-
비슷한 속성의 개체 타입을 구성하며 개체 집합으로 묶임
-
entity 찾는법
영속적으로 존재하는것
새로 식별이 가능한 데이터 요소를 가짐
엔티티는 반드시 attribute를 가져야함
속성 ( attribute )
-
속성 또는 열
-
저장할 필요가 있는 실체에 관한 정보
-
개체의 성질, 분류, 수량 , 상태 , 특성 등을 나타내는 세부사항
-
유형
기초속성 - 원래 갖고 있는 속성으로 현업에서 기본적으로 사용되는 속성
추출속성 - 기초 속성으로부터 계산(가공)에 의해 얻어질 수 있는 속성
설계속성 - 실제로 존재하지 않으나 시스템의 효율성을 도모하기 위해 설계자가 임의로 부여하는 속성
도메인 (domain)
- 어트리뷰트가 취할 수 있는 같은 타입의 원자 값들의 집합을 의미
- 실제 애트리뷰트 값이 나타날 때, 그 값의 합법 여부를 시스템이 검사하는 데에도 이용
식별자
-
기본키 (primary Key)
개체에서 각 인스턴스를 유일하게 식별하는데 가장 적합한 key
기본키 설정 시 고려할 사항으로 해당 실체를 대표할 수 있을것, 업무적 활용도가 높을것
관계
-
정의
두 엔티티간의 업무적인 연관성 혹은 사실
-
relationship 분석
각 엔티티 간에 특정한 존재여부 결정
현재의 관계 뿐만 아니라 장래에 사용될 경우도 고려
-
E-R 다이어그램으로 관계를 설정하는 순서
-
관계가 있는 두 실체를 실선으로 연결하고 관계를 부여
-
관계차수를 표현
차수성 (cardinality) - 한 실체의 하나의 인스턴스가 다른 실체의 몇 개 의 인스턴스와 관련될 수 있는가를 정의
- 경우에따라 발생 횟수 를 조사
- 양쪽 방향 모두 조사
- 1: 1 , 1: N , N: N
선택성( optinality ) : 선택적인지 반드시 인지를 표시
- 일반적이고 상식적인 선에서만 먼저 판단
- 항상 그 관계를 만족해야만 하는지 파악
- 관계를 만족되지 않는 경우를 찾아보고 하나라도 만족되지 않는 경우가 있으면 optional로 표시
- 양쪽 방향 모두 조사
-
.png)
3. 선택성을 표시논리적 데이터 모델링 ⇒ 관계형 스키마
-
개념적 데이터베이스 모델링 관계에서 정의된 ER-diagram을 mapping Rule을 적용하여 관계형 데이터베이스 이론에 입각한 스키마를 설계하는 단계와 이를 이용하여 필요하다면 정규화 하는 단계로 구성
-
기본키 (primary key)
후보키 중에서 선택한 주 키
널의 값을 가질 수 없다( not NULL)
동일한 값이 중복해서 저장될 수 없다 (UNIQUE)
-
Mapping RULE
개념적 데이터베이스 모델에서 도출된 개체 타입과 관계 타입의 테이블 정의
개념 논리
단순 엔티티 → 테이블
속성 → 컬럼
식별자 → 기본키
관계 → 참조키 , 테이블\
-
1:N 관계 타입의 변환
N인 쪽의 테이블에 1의 데이터를 넣어서 참조한다.
물리적 데이터 모델링
VIEW
물리적인 저장 공간을 가지지 않음
하나 이상의 테이블로부터 만들어 짐
워크벤치를 껏다가 키면 뷰를 다시 만드는 쿼리가 실행되고 검색하는 sql 실행
뷰를 access 하게 되면 간접적으로 테이블을 access하게 됨
선택된 컬럼 정보만 참고 가능
-
문법
Create [or replace] view 뷰 이름
as sub-query
-
예시
Create view v_emp
As
Select empid,ename, sal
from emp
where deptid=20;
Index
테이블 컬럼의 빠른 검색을 위해 사용하는 독립된 객체
- 인덱스 생성 기준
- sql문의 where절에서 자주 사용되는 컬럼이 대상이 됨
- 빈번하게 변경되지 않는 테이블에 적용
- 데이터가 많은 테이블에 효과적
- 테이블 간 join에 사용되는 컬럼을 선정
PK의 경우 이미 index가 생성 되어 있다.
- index 생성
Create index i_emp_name on emp(fname);
- index 생성
-
수동 index
create index 구문으로 인덱스 생성ndex 구문으로 인덱스 생성
-
자동 index → PK, unique → 자동생성
