혼자 공부하는 머신러닝+딥러닝을 참고하여 공부하고 있다.
앙상블(ensemble)
- 앙상블 모델이란 여러 개의 분류기를 학습하고 더 좋은 성능을 내는 모델이다.
- 단일 모델보다 앙상블 모델이 성능이 더 좋다.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_breast_cancer
# data는 sklearn에 내장되어있는 유방암 데이터를 활용했다.
cancer = load_breast_cancer()
cancer.keys()
#dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
data = cancer.data
target = cancer.target
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)1. 랜덤포레스트(Random Forest)
- 랜덤포레스트는 지도학습 알고리즘으로 분류와 회귀에 모두 사용
- 여러 개의 의사결정나무를 조합한 모델
- 앙상블 기법은 보팅(voting), 배깅(bagging), 부스팅(boosting)으로 나뉜다. 배깅은 데이터를 무작위로 추출하여 다양한 서브 데이터셋을 생성하고 이들을 각각 동시에 학습하고 그 결과를 다수결이나 평균으로 결정하는 것이다. 랜덤포레스트는 의사결정나무를 배깅 방식으로 만든 알고리즘이다.
- 랜덤 포레스트는 데이터셋에서 중복을 허용하여 무작위로 N개의 데이터를 선택한다.(부트스트랩)
- 의사결정 나무와 마찬가지로 분류의 경우 지니계수 혹은 엔트로피를 줄이는 방식으로 진행된다.
from sklearn.ensemble import RandomForestClassifier
params = {'min_samples_split': [8,16,20],
'max_depth': [3,5,10],
'min_samples_split': [8,12,18],
'n_estimators' :[100,300,500]
}
gs = GridSearchCV(RandomForestClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_) #{'max_depth': 5, 'min_samples_split': 8, 'n_estimators': 100}
final_gs = RandomForestClassifier(random_state=42,max_depth=gs.best_params_['max_depth'],
min_samples_split = gs.best_params_['min_samples_split'],
n_estimators = gs.best_params_['n_estimators'])
final_gs.fit(train_input, train_target)
print('Train', final_gs.score(train_input, train_target)) # 0.9934065934065934
print('test', final_gs.score(test_input,test_target)) # 0.9649122807017544
# feature_importances
f_gs = pd.DataFrame([final_gs.feature_importances_],columns=cancer.feature_names)
sns.barplot(f_gs,orient='h')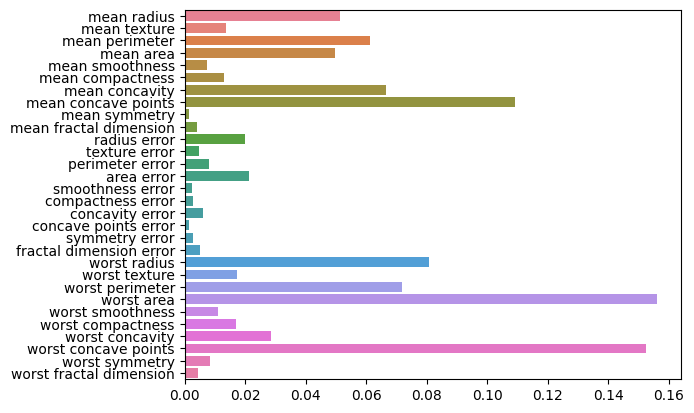
랜덤포레스트의 서브 데이터셋에 포함되지 않은 것을 OOB샘플이라 하는데, 이것을 활용하여 모델을 검증할 수 있다.
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_) # 0.95604395604395612. 엑스트라 트리(Extra Trees)
- 랜덤포레스트와 달리 중복된 훈련 데이터 샘플을 사용하지 않고, 전체 데이터세트를 사용한다.
- 노드를 분할할 때 최적의 노드로 분할하는 것이 아닌 무작위 분할
- 랜덤이기 때문에 훈련 데이터에 모델이 과대적합되는 것을 막을 수 있다.
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# 1.0 0.9626373626373625
et.fit(train_input, train_target)
et_df = pd.DataFrame([et.feature_importances_],columns=cancer.feature_names)
# feature_importances 시각화
sns.barplot(et_df,orient='h')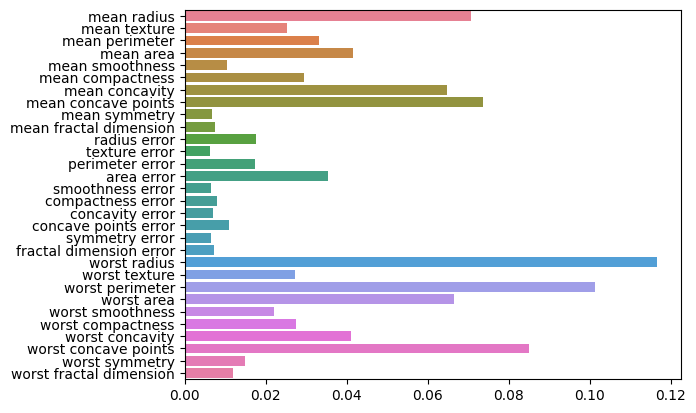
특성의 중요도를 비교해보면 어느 기법을 쓰느냐에 따라 특성의 중요도가 많이 달라진다는 것을 알 수 있다.

데이터분석공부중