로지스틱 회귀분석
혼자 공부하는 머신러닝 + 딥러닝 책을 참고하여 머신러닝 공부를 하고 있다.
로지스틱 회귀 분석은 이름은 회귀지만 분류 문제이다.
이 알고리즘은 선형방정식을 학습하는데 target값으로 0~1 사이의 확률값을 갖는다. 그렇기 때문에 아주 큰 음수를 넣으면 0이 되고, 아주 큰 양수를 넣으면 1이 되는 시그모이드 함수를 사용한다.
시그모이드 함수(Sigmoid Function)
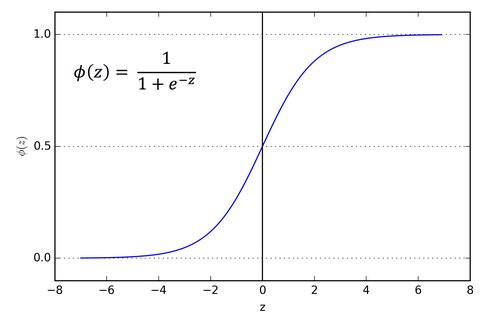
출처 : https://dmsvk01.tistory.com/21
아래는 -5부터 5까지 0.1 간격으로의 숫자를 시그모이드 함수에 넣어 만든 그래프이다. 모두 0과 1 사이의 값을 갖는 것을 확인 할 수 있다.
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(-5,5,0.1)
phi = 1/ (1+np.exp(-z))
plt.plot(z,phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()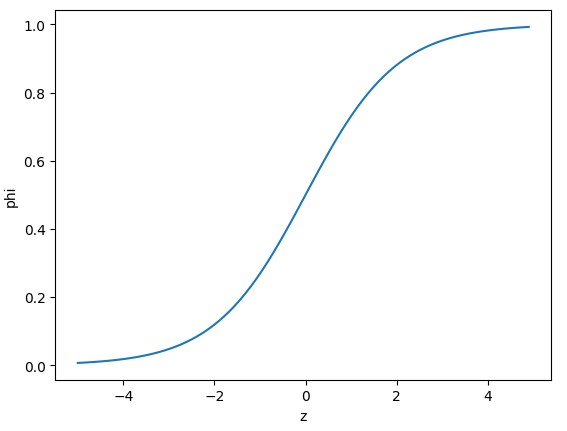
로지스틱회귀(이진분류)
1. 데이터 전처리
import pandas as pd
import numpy as np
fish = pd.read_csv('https://bit.ly/fish_csv_data')
print(pd.unique(fish.Species))
# ['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']
# 7개의 타겟값을 갖는 것을 알 수 있다.
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
# 분석에 활용하기 위해 넘파이 배열로 바꾼다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input,fish_target)
# 표준화 작업 - 훈련세트의 통계값으로 테스트세트를 변환해야함
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
# target값으로 빙어와 도미인 행만 골라냄
bream_smelt_indexes = (train_target=='Bream')|(train_target=='Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]2. 분석
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
print(lr.predict(train_bream_smelt[:5]))
# ['Bream' 'Bream' 'Bream' 'Smelt' 'Bream']
# 네번째 샘플만 빙어로 예측
print(lr.classes_) #0이 'Bream' 1이 'Smelt'라는 것을 확인 가능
# ['Bream' 'Smelt']
print(lr.predict_proba(train_bream_smelt[:5]))확률로 계산했을 때 네번째만 양성클래스인 빙어의 확률이 높게 예측하였다. 이는 위의 target값을 예측한 것과 비교했을때 로지스틱 회귀로 이진 분류에 성공했다는 것을 알 수 있다.

print(lr.coef_,lr.intercept_)
# [[-0.40528484 -0.59619904 -0.68016433 -0.96961284 -0.7355347 ]] [-2.42120371]이는 target = -0.405(Weight) -0.596(Length) -0.680(Diagonal) -0.970(Height) -0.736(Width) -2.42로 표현할 수 있다.
로지스틱회귀(다중분류)
1. 분석
target값으로 7가지 생선 모두 사용하면 되기 때문에 따로 데이터를 준비할 필요가 없다.
lr.fit(train_scaled,train_target)
print(lr.score(train_scaled,train_target))
print(lr.score(test_scaled,test_target))
# 0.8151260504201681, 0.8
#트레인셋이나 테스트셋에 대한 점수가 낮게 나와 이는 데이터셋이 적거나 모델이 너무 단순하여 생길 수 있는 문제이다.
print(lr.predict(test_scaled[:5]))
# ['Bream' 'Bream' 'Parkki' 'Bream' 'Bream']
# 세번째만 'Parkki'로 예측
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba, decimals = 3)) # decimals은 소수점 몇째자리까지 나타낼지를 표현
print(lr.classes_)
# ['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
세번째 행만 'Parkki'의 확률값이 높은 것을 확인할 수 있다. 다중 분류일 때 선형방정식은 7개(클래스의 갯수)나 계산하기 때문에 다중분류는 소프트맥스 함수를 사용하여 7개의 확률로 변환한다.
print(lr.coef_.shape,lr.intercept_.shape)
(7, 5) (7,)소프트맥스 함수는 시그모이드 함수와 같이 0~1 사이에 값을 갖게하지만 전체 합이 1이 되도록 만든다.

데이터분석공부중