Image Classification
구조
- Input: image (e.g. 800 x 600 x 3 image with 3 channel RGB)
- Output: classification의 결과 (e.g. 'cat')
Challenges
- Viewpoint variation
: 다른 각도에서 찍으면 픽셀이 움직이므로, 모델 입장에선 완전히 다른 사진 - Illumination
: 같은 각도에서 찍었을지라도 조명에 따라 사진이 달라짐 - Deformation
: 피사체의 자세에 따라 달라짐 - Occlusion
: 가려짐?? (제대로 못들음) - Background clutter
: 배경 색에 따라 대상 구분이 쉽지 않을 수 있음 - Intraclass variation
: "Cat"이라는 class 안에는 다앙한 모습, 크기 등을 가진 개체가 존재
접근 방식
Naive Approach
def classifiy_image(image):
return class_label하지만, 모든 class에 대해 이미지를 잘 분류하는 알고리즘을 hard-coding할 방법이 없음
Data-Driven Approach
- images와 labels에 대한 데이터셋 수집
- Machine Learning을 이용하여 classifier 학습
- train에 이용하지 않은 images를 이용하여 classifier 평가
# classify_image를 두 개의 api로 분리
def train(images, labels):
return model
def predict(model, test_images):
return test_labelsk-NN (k-Nearest Neighbors Algorithm)
k-Nearest Neighbors
- Train: 가장 가까운 k개 이웃들을 학습
- Predict: 학습 data와 가장 유사한 label을 예측
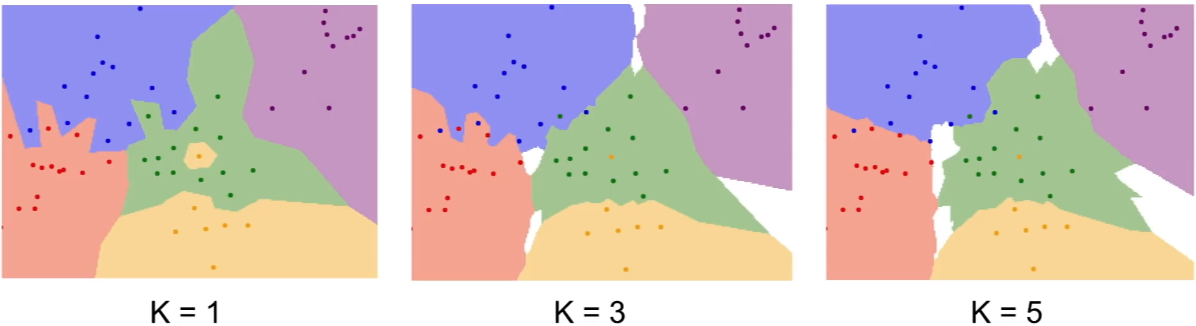
→ k가 커질수록 경계가 부드러워짐
Q: White region?
A: Majority를 결정할 수 없는 공간. 해당 공간을 메우는 방법 역시 다양하게 존재
Note: CV에서 image를 보는 두 관점
1. 고차원 공간에 존재하는 하나의 점
2. 이미지 자체(픽셀들을 벡터들로 간주)
Performance
- Train: O(1)
- Predict: O(n)
- But, 우리는 prediction이 빠른 classifier가 필요 (학습이 느린건 ok)
Distance Metric
-
두 데이터(image)가 얼마나 '유사한지'의 척도를 결정
-
데이터가 존재하는 공간의 기하학적 구조를 결정

→ L1 거리 관점에서 위 사각형은 원과 동일(i.e. 원점에서 모두 같은 거리) -
어떤 distance metric을 선정하느냐에 따라 학습 결과도 달라짐

→ L1을 이용한 결과의 경계가 좌표축에 보다 더 평행함
L1 vs L2
- L1은 L2와 달리, 좌표계의 영향을 받음(i.e. 좌표계를 회전하면 L1 distance가 변함) → 보다 더 수직/수평적 성격
- Input feature vector의 elements가 특징을 가지고 있으면 (ex. 직원 벡터의 봉급, 연차 요소 등) 회전에 민감한 L1 distance가 더 적합할 수 있음
- Feature vector가 일반적인 벡터이고, element 간 의미 파악이 안된다면, L2가 적합
- k-NN의 distance metric을 다르게 하면, vector/image 외의 다른 데이터도 k-NN을 사용할 수 있음(ex. 문장)
k-NN의 문제점
- 너무 느림
- L1, L2가 이미지들 간의 perceptual similarity를 측정하기에는 적절하지 않음
- Ex) 아래 그림은 모두 원본으로부터 동일한 L2 거리를 가짐 -> 유사성을 측정하기에 적합하지 않음

→ 원본(1)으로부터 동일한 L2거리를 갖는 사진들(2~4)
→ L2는 이미지의 유사성을 측정하기엔 적합하지 않다. - Curse of dimensionality
: k-NN을 잘 이용하려면 이웃이 촘촘하게 분포해야함. 따라서 데이터의 차원이 증가할 수록 필요한 데이터가 기하적으로 증가
Hyperparameters
모델에서 사람이 반드시 결정해주어야 하는 사항(ex. k-NN의 k, distance metric)
데이터로 학습시킬 방법이 없어, 직접 설정해야함
Hyperparameters를 결정하는 법(데이터 분할)
- 모든 데이터를 train set으로 활용
- 선택: 가장 높은 정확도를 갖는 hyperparams
- But, 주어진 데이터에 대해서만 가장 높은 정확도를 가지므로, 새로운 데이터에 잘 대응할 것이란 보장이 없음
- ex) k-NN은 k=1일 때 주어진 데이터를 가장 잘 분류하지만, 일반적인 데이터에 대해서는 k가 큰 경우 더 좋은 성능을 보임
Note
ML에서는 모델이 주어진 데이터가 아닌, 한 번도 보지 못한 데이터에 얼마나 잘 대응하는지가 중요
- 전체 dataset을 쪼개서 일부는 train set으로, 나머지는 test set으로 활용
- 선택: test set에서 가장 높은 정확도를 갖는 hyperparams
- But, 그저 'test set'에서만 잘 작동하는 모델을 선택한 것일 수 있음(i.e. 모델이 new data에 잘 작동한다는 보장이 없음)
- train set, validation set, test set으로 나눔
- 선택: validation set에서 가장 높은 정확도를 갖는 hyperparams
- test set은 모든 개발 완료 후에 오직 한번만 수행
- 한 번도 보지 못한 데이터(test set)에 대한 모델의 반응을 볼 수 있음
Q: test set이 "new data"를 대표할 수 있는가?
A: i.i.d. assumption에 의해 이론적으로는 test set이 일반적인 new data와 동일한 분포를 가짐. 실제 상황에서 이 가정을 적용할 수 없다면, 데이터셋을 무작위로 섞어 쓰는 방법으로 이 문제를 완화할 수 있음
- cross validation
- 주로 dataset이 작을 때 사용
- train set을 쪼갠 후, 각 fold를 validation set으로 활용하면서 여러 번 검증 후 평균
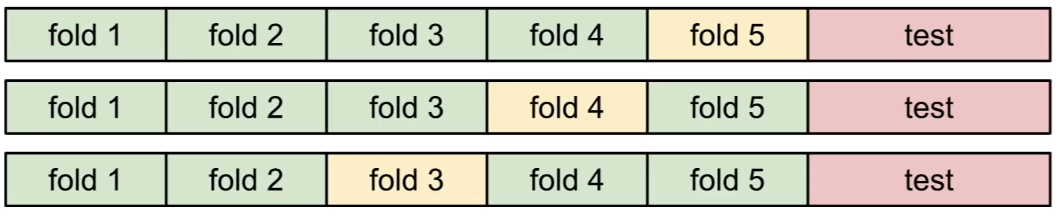
→ 5-fold cross validation
Linear Classification
NN(Neural Network)의 기반을 이루는 알고리즘
Note
Neural Network는 Linear Classifier Blocks의 모음 (레고 블럭)
ex) Img Captioning에서 Img 부분은 CNN, 언어 부분은 RNN을 사용. 이 두 블럭을 쌓아올렸을 뿐. CNN도 Linear Classifier들을 쌓아올린 것
Parametric Model
- Input: image
- Function: f(x, W) (x: input, W: weights)
- Output: 각 class에 대한 점수를 담은 몇 개의 수
(ex. "cat" class의 점수가 높다: 고양이일 확률이 높다) - 장점: test time에 weights만 있으면 ok -> 소형 기기에 적합
(k-NN은 test time에 train set도 필요했음)
Linear Classifier
Parametric Model의 가장 간단한 형태(단순 곱)
Score function: f(x, w) = Wx + b (bias)
Dimensions of terms (ex)
Image: 32 x 32 x 3 = 3072 total (32 for img size, 3 for RGB)
x: 3072 x 1 (column vector로 flattened)
W: 10 x 3072 (10 for classes)
b: 10 x 1

→ [3 x 4] * [4 x 1] + [3 x 1] -> [3 x 1]
Linear Classifier를 보는 관점
- Template Matching
- W의 행: 각 class에 대한 template
- 결과의 행: W의 row vector와 Image(column vector)의 내적(i.e. 유사도)
- Bias: 데이터에 독립적인 scaling offset
-
템플릿 매칭 관점에서 가중치 행렬의 한 행을 뽑아서 이미지로 시각화시켜보면 lc가 어떻게 학습되는지 볼 수 있음

→ Template 시각화. 'plane' 템플릿은 전반적으로 푸른색 -
문제점: 한 class에 대해 한 template만 학습
- 한 class 내에 다양한 특징이 있지만, template은 1개밖에 없음
- ex) 위 그림의 'horse' template을 자세히 보면 머리가 2개
- NN같은 더 복잡한 모델은 여러 템플릿을 가질 수 있어 해결 가능
- 고차원 공간의 점과 직선
- Image: 고차원 공간의 한 점
- linear classifier: 각 점들을 구분해주는 선형 경계
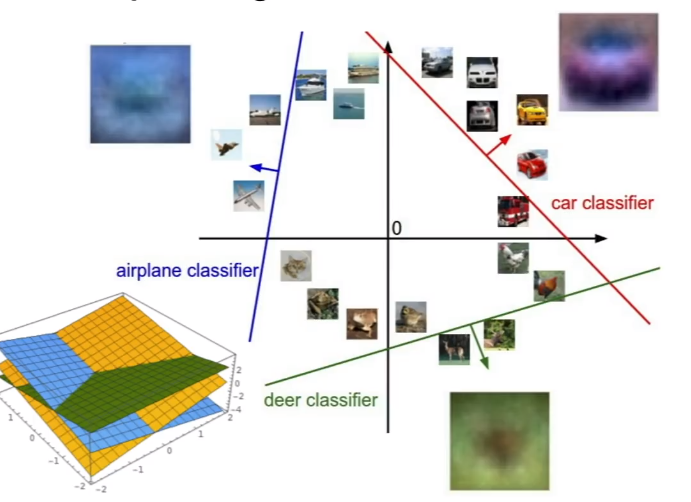
→ 푸른색 선을 학습하여, 비행기와 다른 클래스를 구분할 수 있음
- 문제점: 선형 경계로 구분할 수 없는 경우
- 아래 경우들은 선형적인 classifier로는 클래스들을 분류할 수 없음
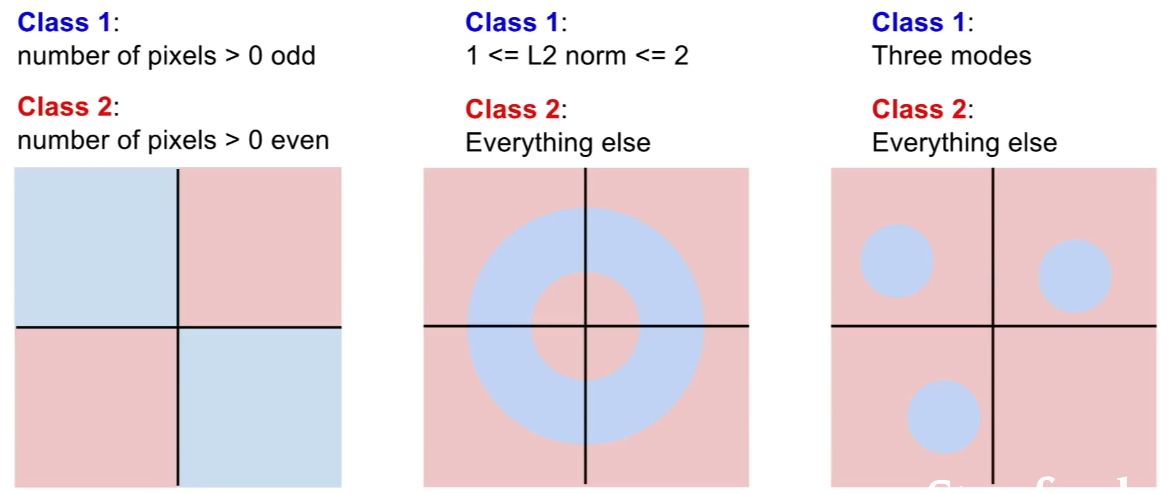
→ parity problem(case 1), multi-modal problem(case 3) 등=
- 아래 경우들은 선형적인 classifier로는 클래스들을 분류할 수 없음
Coming Up
- loss function: quantifying what it means to have a 'goo' W
- optimization: start with random W and find a W that minimizes the loss
- convnet: tweak the functional form of f
Reference
