
1. Embeddings: Collaborative Filtering
협업 필터링은 다른 여러 사용자의 관심분야를 바탕으로 특정 사용자의 관심분야를 예측하는 작업이다. 예를 들어 영화 추천 작업을 살펴보겠다. 1,000,000명의 사용자와 500,000편의 영화 중 각 사용자가 본 영화의 목록이 있다고 가정하고 사용자에게 영화를 추천하는 것이 목표로 잡아 보자.
이 문제를 해결하려면 어떤 영화가 서로 비슷한지 파악하는 방법이 필요하다. 이를 위해 비슷한 영화가 서로 인접하도록 만들어진 저차원 공간에 영화를 임베딩할 수 있다.
임베딩을 학습하는 방법을 설명하기 전에 우선 임베딩에 필요한 유형의 품질과 임베딩 학습을 위해 학습 데이터를 표현하는 방법을 알아보겠다.
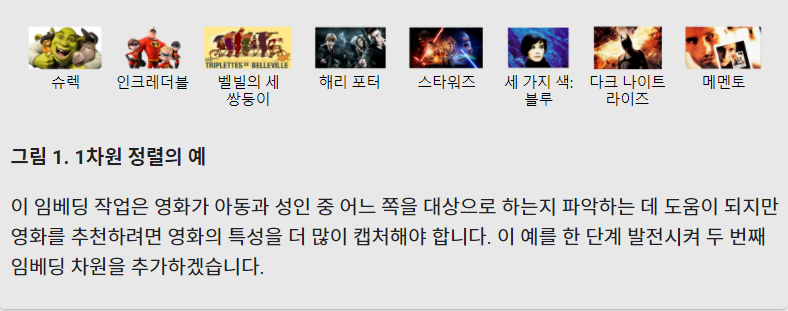
(1) 1차원 수직선에 영화 정렬
(2) 2차원 공간에서 영화 정렬
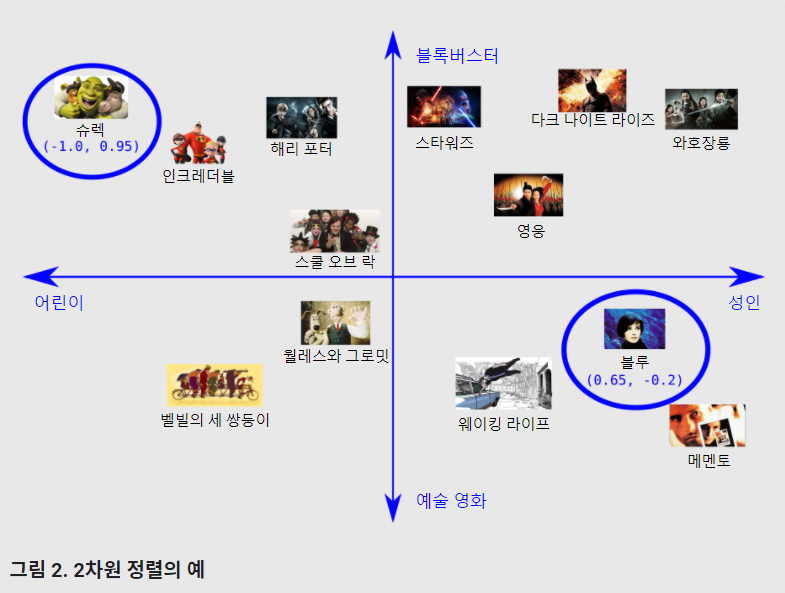
이 2차원 임베딩을 통해 아동과 성인 쪽 어느 쪽을 대상으로 하는지 여부와 블록버스터 영화와 예술 영화 중 어느 쪽에 가까운지 여부에 따라 서로 가깝고 따라서 비슷한 것으로 추론되는 영화 간의 거리를 정의한다. 이 방법은 물론 영화에서 중요한 수많은 특성 중 두 가지에 불과하다.
좀 더 쉽게 말하면 각 단어가 2차원 좌표로 표현되는 임베딩 공간에 이 영화들을 매핑시킨 것이다. 예를 들어 이 공간에서 '슈렉'은 (-1,0, 0.95), '세 가지 색: 블루'는 (0.65, -0.2)로 매핑된다. 일반적으로 d차원 임베딩을 학습할 때 각 영화는 각 차원의 좌표를 나타내는 실수 값 d개로 표현된다.
이 예에서는 각 차원에 이름을 지정했다. 임베딩을 학습할 때 개별 차원은 이름으로 학습되지 않는다. 임베딩을 보고 차원에 의미론적인 뜻을 할당할 수도 있지만 그러지 못하는 경우도 있다. 이러한 각 차원을 간혹 잠재 차원이라고 하는데 잠재 차원이 나타내는 특징이 데이터상에 명확하게 드러나는 것이 아니라 유추되는 것이기 때문에 이렇게 불리곤 한다.
결국 중요한 것은 주어진 차원에서 특정 영화의 값이라기보다는 임베딩 공간에서 영화들 간의 거리값이 된다.
2. Embeddings: Categorical Data
범주형 데이터(Categorical Data)란 선택사항이 유한한 집합에 속한 하나 이상의 이산 항목을 표현하는 입력 특성을 가리킨다. 예를 들어 사용자가 시청한 영화의 집합, 문서에 사용된 단어의 집합, 직업의 집합 등이 있다.
범주형 데이터(categorical data)는 대부분의 요소가 0인 희소 텐서를 통해 가장 효율적으로 표현된다. 예를 들어 영화 추천 모델을 개발한다고 하면 그림 3에서 확인할 수 있는 것처럼 모든 영화에 고유 ID를 부여한 후 사용자가 본 영화의 희소 텐서로 사용자를 나타낼 수 있다.
영화 추천 문제에 관한 샘플 입력이다.

그림 3. 영화 추천 문제에 관한 데이터
그림 3 행렬의 각 행은 사용자의 영화 시청 기록을 포착한 예이다. 각 사용자는 가능한 모든 영화 중 일부만 시청했을 것이기 때문에 이 행은 희소 텐서로 표현된다. 마지막 행은 영화 아이콘 위에 표시된 어휘 색인을 사용하여 희소 텐서 [1, 3, 999999]에 대응한다.
마찬가지로 단어, 문장, 문서를 희소 백터로 표현할 수 있는데, 이 때는 각 어휘 목록에 속한 단어가 앞에서 살펴본 영화 추천 예제에서의 영화와 비슷한 역할을 하게 된다.
머신러닝 시스템 내에서 이러한 표현을 사용하려면 의미론적으로 유사한 항목(영화 또는 단어)이 벡터 공간에서 비슷한 거리에 있도록 각 희소 벡터를 숫자 벡터로 표현하는 방법이 필요하다. 하지만 단어를 어떻게 숫자 벡터로 표현할 수 있을까?
가장 간단한 방법은 어휘의 모든 단어에 대해 노드가 있는 거대한 입력 레이어를 정의하거나, 적어도 데이터에 나타나는 각 단어에 대해 노드가 있는 입력 레이어를 정의하는 것이다. 데이터에 500,000개의 고유한 단어가 있다면 한 단어는 길이 500,000인 벡터로 표현할 수 있고 각 단어는 이 벡터의 한 슬롯에 할당할 수 있다.
'말(horse)'이라는 단어를 색인 1247에 할당한 다음 망(network)에 '말'을 전달하는 경우 1247번째 입력 노드에 1을, 나머지 노드 전체에는 0을 복사할 수 있다. 이러한 유형의 표현은 색인 하나에만 0이 아닌 값이 있기 때문에 원-핫 인코딩(one-hot encoding)이라고 부른다.
더 일반적으로는 벡터에 더 큰 텍스트 뭉치에 있는 단어의 수가 포함될 수 있다. 이는 'BOW(bag of words)' 표현으로 알려져 있으며 BOW 벡터에서는 500,000개의 노드 중 여러 개의 노드의 값이 0이 아닐 수 있다.
하지만 어떤 방식으로든 0이 아닌 값을 결정하더라도 단어당 노드 1개 방식으로는 0이 아닌 값이 상대적으로 거의 없는 매우 큰 벡터인 지극히 희소한 입력 벡터가 발생한다. 희소 표현에는 모델의 효과적인 학습을 어렵게 만들 수 있는 몇 가지 문제점이 있다.
(1) 망 크기
입력 벡터가 거대해지면 신경망에 엄청나게 많은 가중치가 만들어진다. 어휘에 M개의 단어가 있고 입력 위에 있는 망의 첫 번째 레이어에 N개의 노드가 있으면 해당 레이어에 대해 MxN개의 가중치를 학습시켜야 한다. 가중치의 수가 커지면 다음과 같은 문제가 발생한다.
-
데이터의 양. 모델의 가중치가 많을수록 효과적인 학습을 위해 더 많은 데이터가 필요하다.
-
계산량. 가중치가 많을수록 모델을 학습하고 사용하는 데 더 많은 계산이 필요하다. 따라서 하드웨어가 이를 지원하지 못할 가능성이 높아진다.
(2) 벡터 간의 의미 있는 관계 부족
이미지 분류자에 RGB 채널의 픽셀 값을 공급하는 경우, '가까운' 값에 대해 언급할 필요가 있다. 불그스름한 파란색은 의미론적으로든 벡터 간 기하학적 거리로든 순수한 청색에 가깝다. 그러나 '말'에 대한 색인 1247에 1을 가진 벡터는 '텔레비전'에 대한 색인 238에서 1을 갖는 벡터보다 '영양'에 대한 색인 50,430에서 1을 갖는 벡터에 더 가깝지 않다.
(3) 솔루션: 임베딩
이러한 문제에 대한 해결책은 크기가 큰 희소 벡터를 의미론적 관계를 보존하는 저차원 공간으로 변환하는 임베딩을 사용하는 것이다. 다음 섹션에서는 임베딩에 대해 직관적, 개념적, 프로그래밍 방식으로 살펴보겠다.
3. Embeddings: Translating to a Lower-Dimensional Space
고차원 데이터를 저차원 공간에 매핑하여 희소한 입력 데이터의 핵심 문제를 해결할 수 있다.
작은 다차원 공간에서도 의미론적으로 유사한 항목은 한데 묶고 유사하지 않은 항목은 서로 떨어뜨리는 작업을 자유롭게 수행할 수 있고 벡터 공간의 위치(거리와 방향)는 좋은 임베딩을 통해 의미론을 인코딩할 수 있다. 예를 들어 아래에 나온 실제 임베딩의 시각화 자료는 국가와 수도 간의 관계와 같은 의미론적인 관계를 캡처하는 기하학적인 관계를 나타낸다.

위와 같은 종류의 의미 있는 공간은 머신러닝 시스템이 패턴을 감지하여 학습 작업을 향상시킬 수 있는 기회를 제공한다.
(1) 망 축소하기
풍부한 의미론적 관계를 인코딩하기에 충분한 차원이 필요하지만 그와 동시에 시스템을 더 빠르게 학습할 수 있게 할만큼의 작은 임베딩 공간도 필요하다. 유용한 임베딩은 대략 수백 차원에 달할 수 있다. 이 크기는 자연어 작업에 필요한 어휘의 크기보다 10의 몇 승만큼이나 더 작다.
(2) 검색표로서의 임베딩
임베딩은 하나의 행렬이고, 행렬의 각 열은 어휘 항목 하나에 대응한다. 단일 어휘 항목에 대한 밀집 벡터를 얻으려면 해당 항목에 대응하는 열을 검색한다.
하지만 희소한 BOW(bag of words) 벡터는 어떻게 변환해야 할까? 여러 개의 어휘 항목(예: 문장 또는 단락의 모든 단어)을 나타내는 희소 벡터에 대한 밀집 벡터를 얻으려면 개별 항목에 대해 임베딩을 검색한 다음 이를 전부 더하면 된다.
희소 벡터에 어휘 항목의 수가 포함되어 있으면 각 임베딩에 해당 항목의 수를 곱한 다음 이를 합계에 추가할 수 있다.
(3) 행렬 곱셈으로서의 임베딩 검색
방금 설명한 검색, 곱셈, 덧셈 절차는 행렬 곱셈과 동일하다. 1xN 크기의 희소 표현 S와 NxM 크기의 임베딩 표 E가 주어지면 행렬 곱셈 SxE를 통해 1xM 밀집 벡터를 얻을 수 있다.
4. 임베딩 획득하기
(1) 표준 차원 축소 기법
(2) word2vec
(3) 더 큰 모델의 일부로서 임베딩 학습

.
.
.
강의 링크 : 구글 머신러닝 단기 집중과정
