Time Complexity는 여러 자료구조를 효율성 측면에서 분석하여 상황에 맞게 선택, 사용하기 위한 개념이다. 그런데 이런 Time Complexity를 파악하기 위한 지표가 Complexity Analysis이다. 먼저 Complexity Analysis (복잡도분석)에 대해 알아보자.
Complexity Analysis
복잡도란,
'알고리즘이 그것을 푸는데 있어 시간과 공간을 얼마나 차지하는 지 나타내는 지표' 이다. 시간과 공간의 복잡도가 그 알고리즘이 얼마나 효율적인지를 나타낸다. 어떤 문제가 있다고 가정하자. 그 문제의 크기가 클수록 시간이 오래 걸리는 알고리즘과 문제의 크기와 상관없이 시간이 일정하게 걸리는 알고리즘이 있다면, 후자가 더 효율적이라고 말할 수 있다.
다음의 예제를 보자.
Q. '주어진 숫자들 중 가장 큰 수와 가장 작은 수의 차이'를 구하라.
먼저 단순하게 주어진 숫자들의 차이를 전부 구하는 방법이 있다.
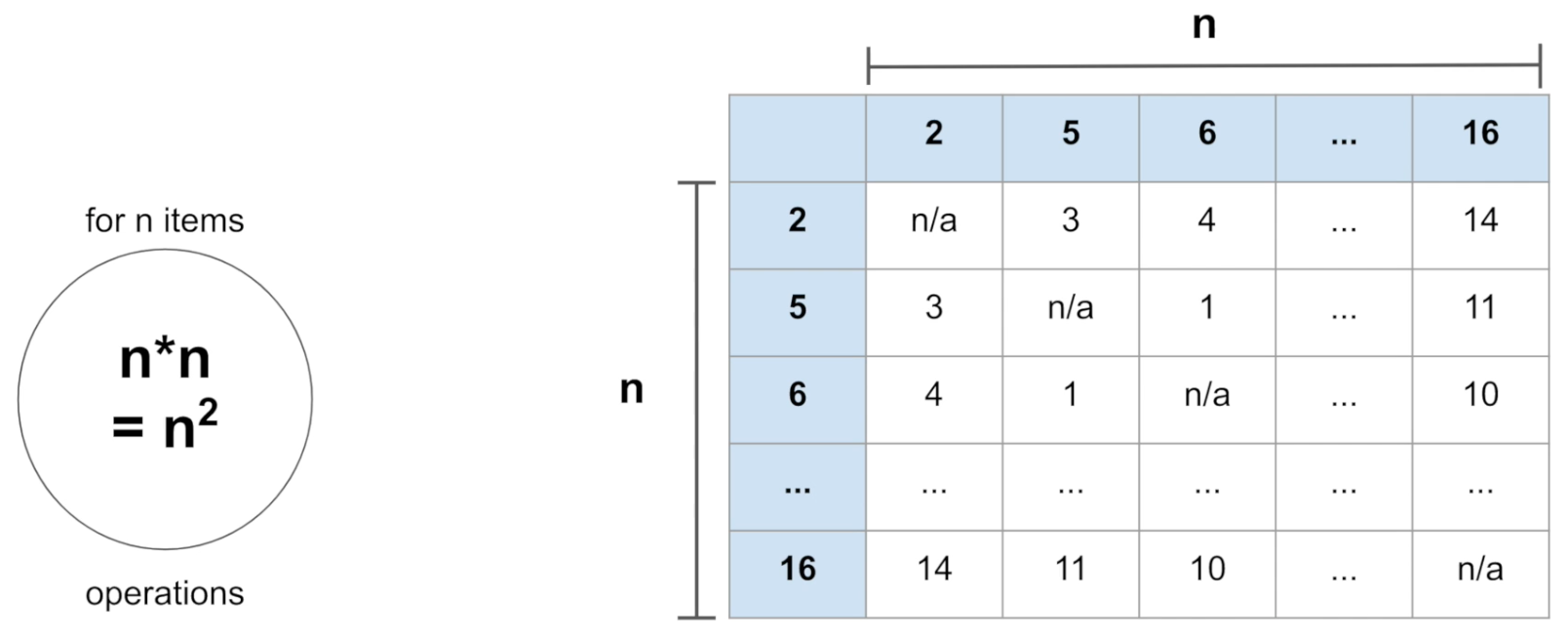
총 n²번의 연산이 필요하다.
이와 같은 방법은 주어진 숫자들이 많을 수록(문제가 커질 수록) 연산이 커진다. 10x10은 5x5보다 4배의 시간이 더 필요하다. 다음의 방법을 살펴보자.
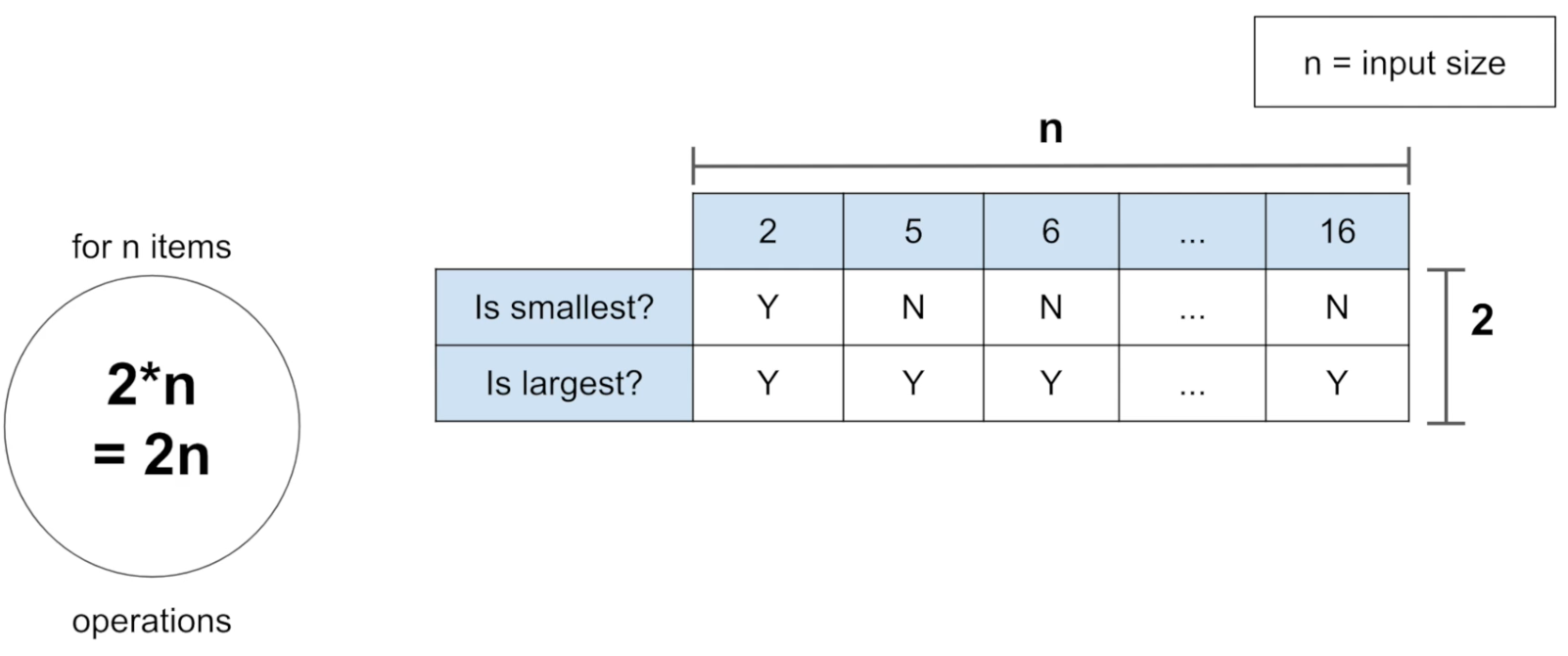
먼저 가장 작은 수를 찾느라 n번 움직이고, 가장 큰 수를 찾기 위해 n번 움직여서 총 2n번의 연산이 요구된다. 그래서 주어진 숫자가 10개인 경우는 5개인 경우보다 2배의 시간이 더 필요하다(10x2 = 2(5x2)). 위의 경우보다 시간복잡도가 더 나아졌다고 할 수 있다.
다른 경우를 보자. 만약 숫자들이 크기 순서대로 정렬이 되어있다면 어떨까?
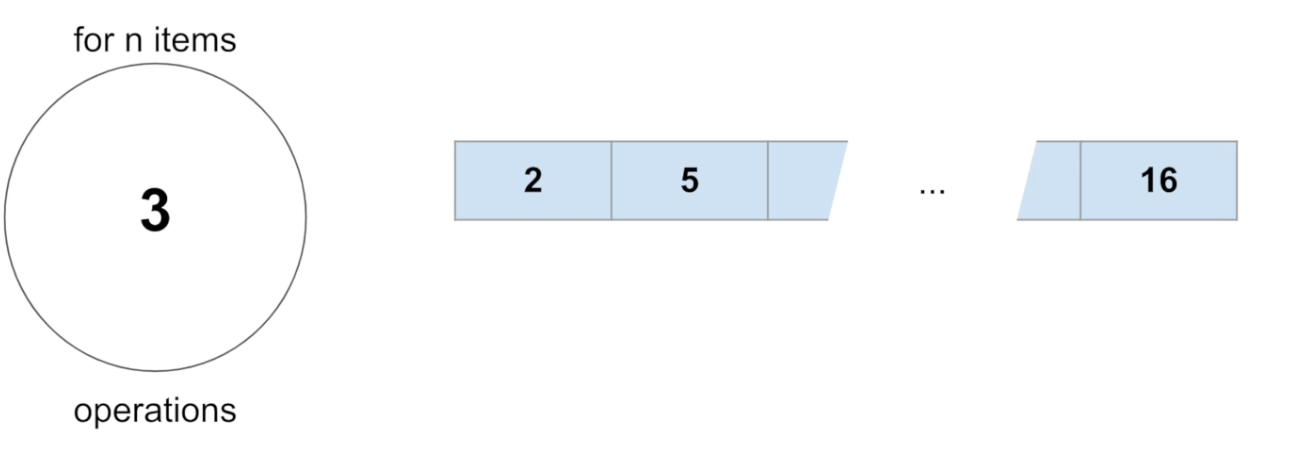
이와 같은 경우엔 3번의 연산만 하면 된다. 가장 작은 수를 찾고, 가장 큰 수를 찾고, 마지막으로 둘의 차이를 구한다. 이런 경우는 숫자가 몇개가 주어지든 연산은 3번일 것이다. 이런 시간 복잡도를 Constant Time 이라고 부른다. 최고로 빠른 시간 복잡도이다.
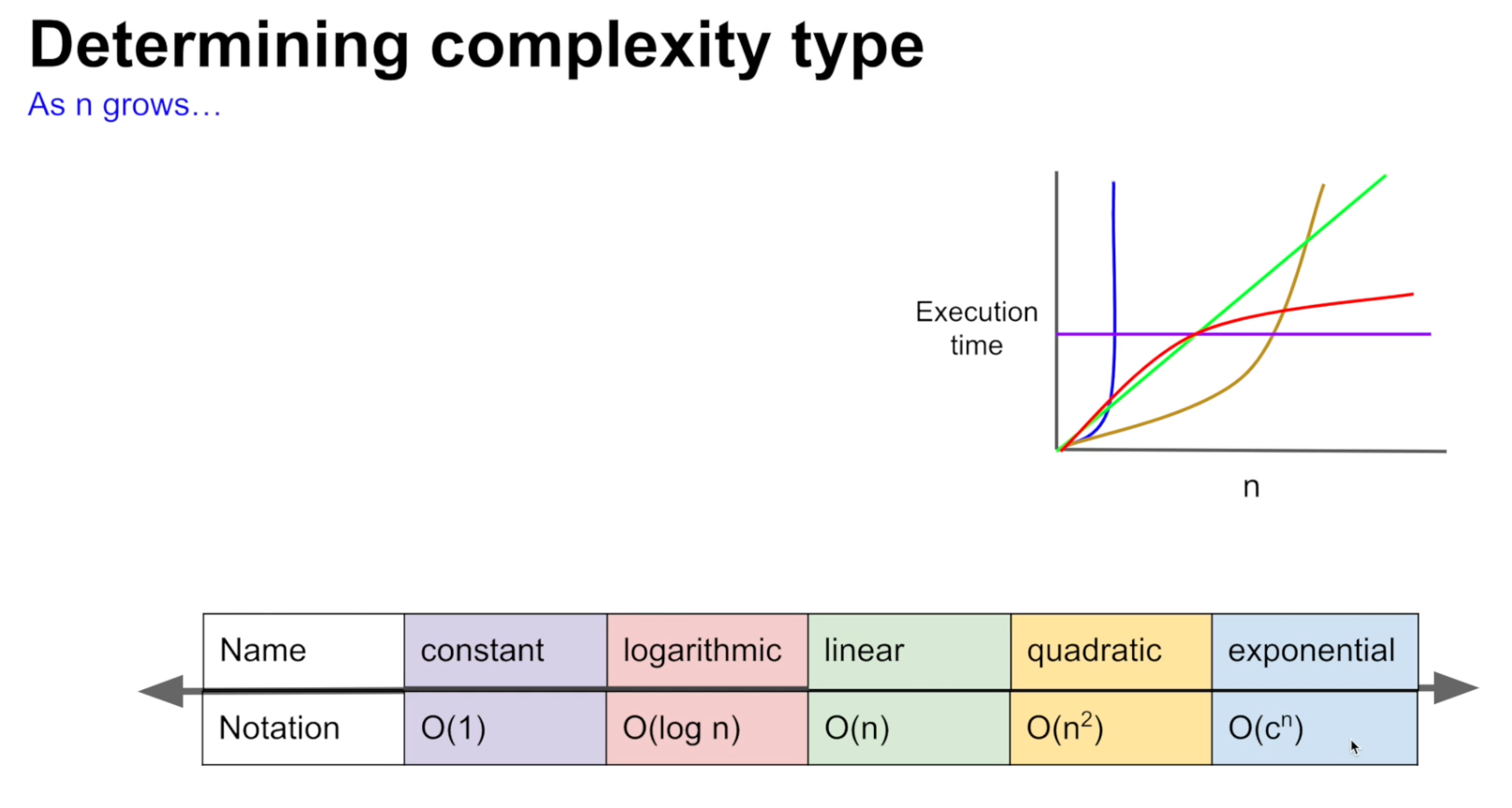
이런 다양한 시간 복잡도를 표현하는 방법엔 Big-O Notation이라는 방법이 있다.
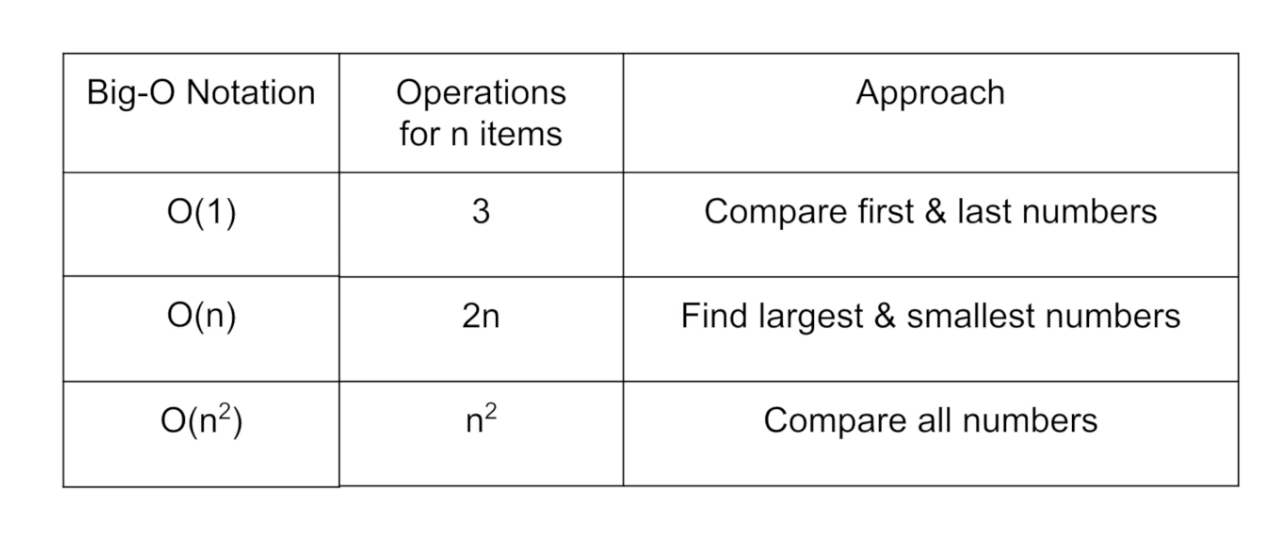
연산식에서 제일 큰 지수를 가진 변수만 보는 방식이다. 앞에 상수가 붙어있다면 상수도 제거한다. 상수, 차수가 낮은 지수를 가진 변수들을 배제하는 이유는 가장 높은 지수를 가진 변수에 미치는 영향이 작기 때문이다.
그래서 지수가 높아질 수록 다음과 같은 양상으로 시간복잡도가 형성된다.
Time Complexity
위에서 알아본 복잡도를 자료구조들에 적용시킬 수 있다.
자료구조들의 특정 상황들(메서드)에서 어떤 Big-O Notation이 적용되는지 한번 알아보자.
Arrays
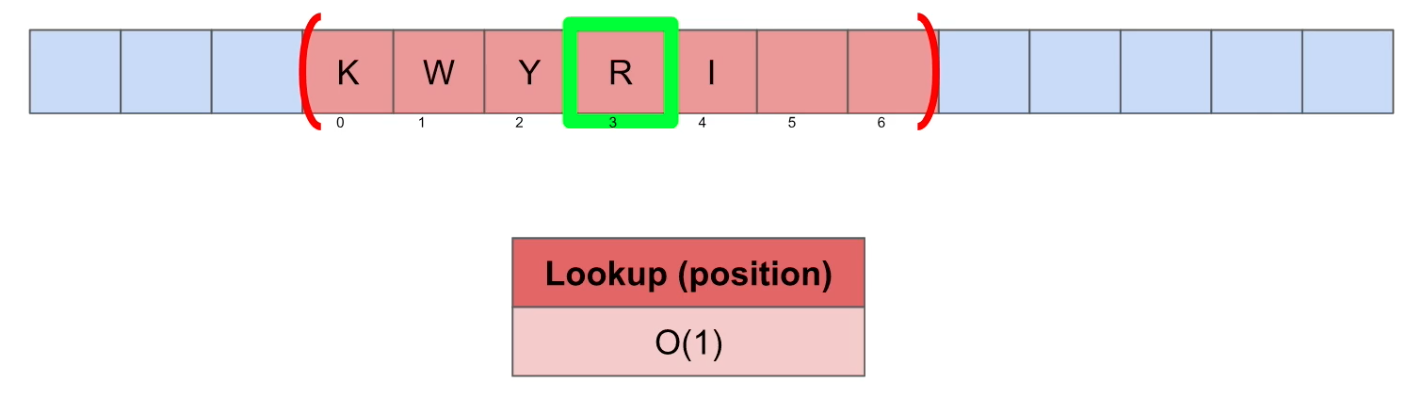
Lookup(특정 위치의 데이터를 가져옴)
Big-O Notation = O(1) : constant. 해당 인덱스를 호출만 하면 됨.
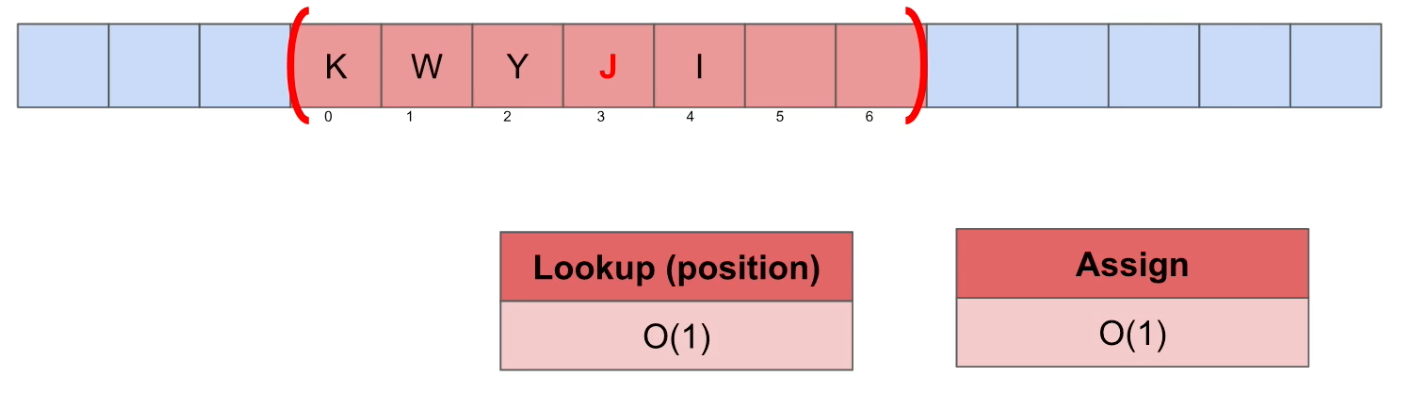
Assign(특정 위치의 데이터를 교체)
Big-O Notation = O(1) : constant. 해당 인덱스를 호출만 하면 됨.
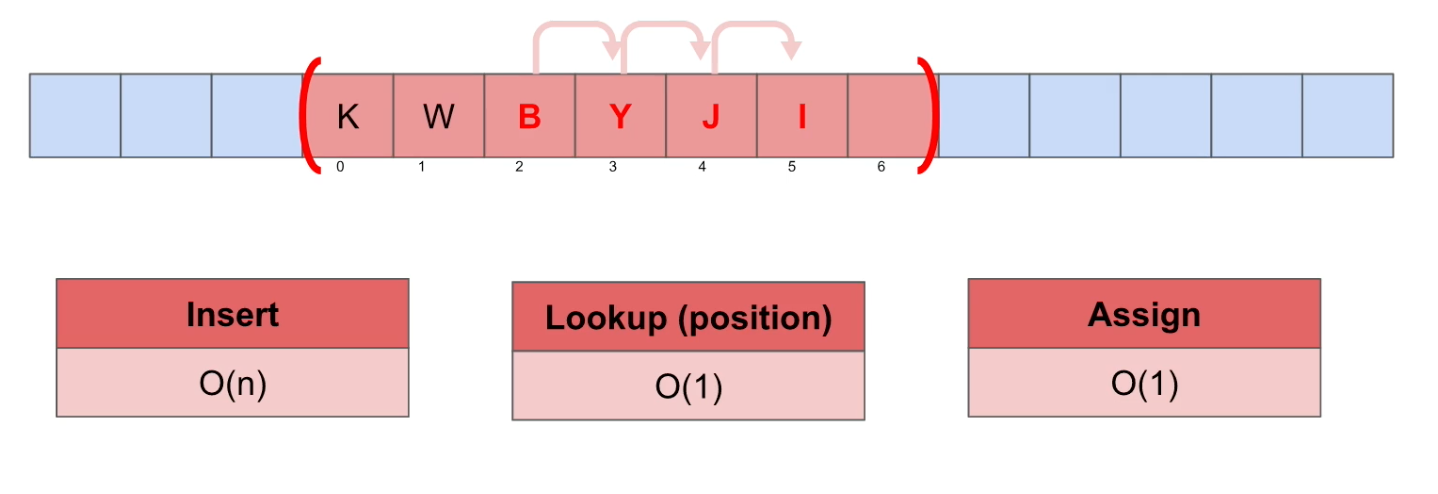
Insert(특정 위치에 데이터를 삽입)
Big-O Notation = O(n) : linear. 뒤로 한칸씩 밀리기에 각각의 위치들을 확인해야함.
Remove(특정 위치의 데이터를 삭제)
Big-O Notation = O(n) : linear. 삭제되어 생긴 빈 공간을 채우기 위해 앞으로 한칸씩 움직임. 각각 위치를 확인해야 한다.
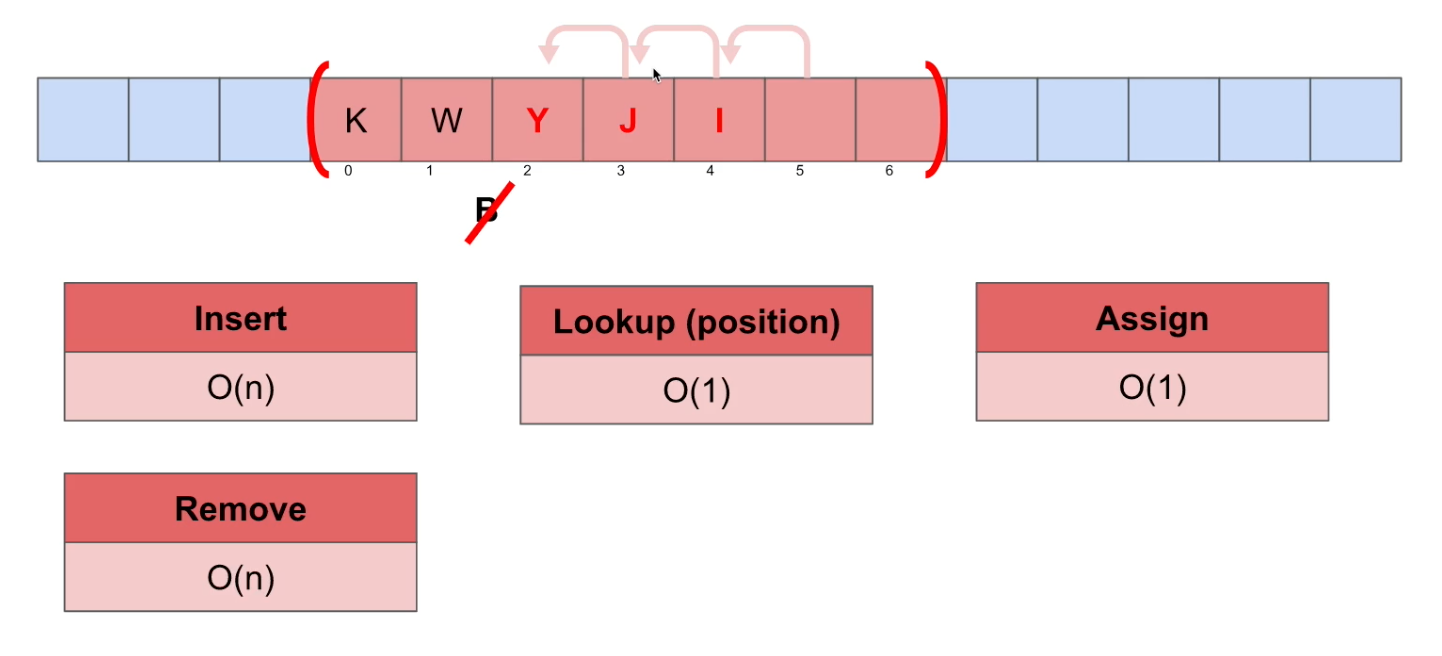
Find(특정 데이터를 찾음)
Big-O Notation = O(n) : linear. 데이터를 하나씩 확인해야 한다.
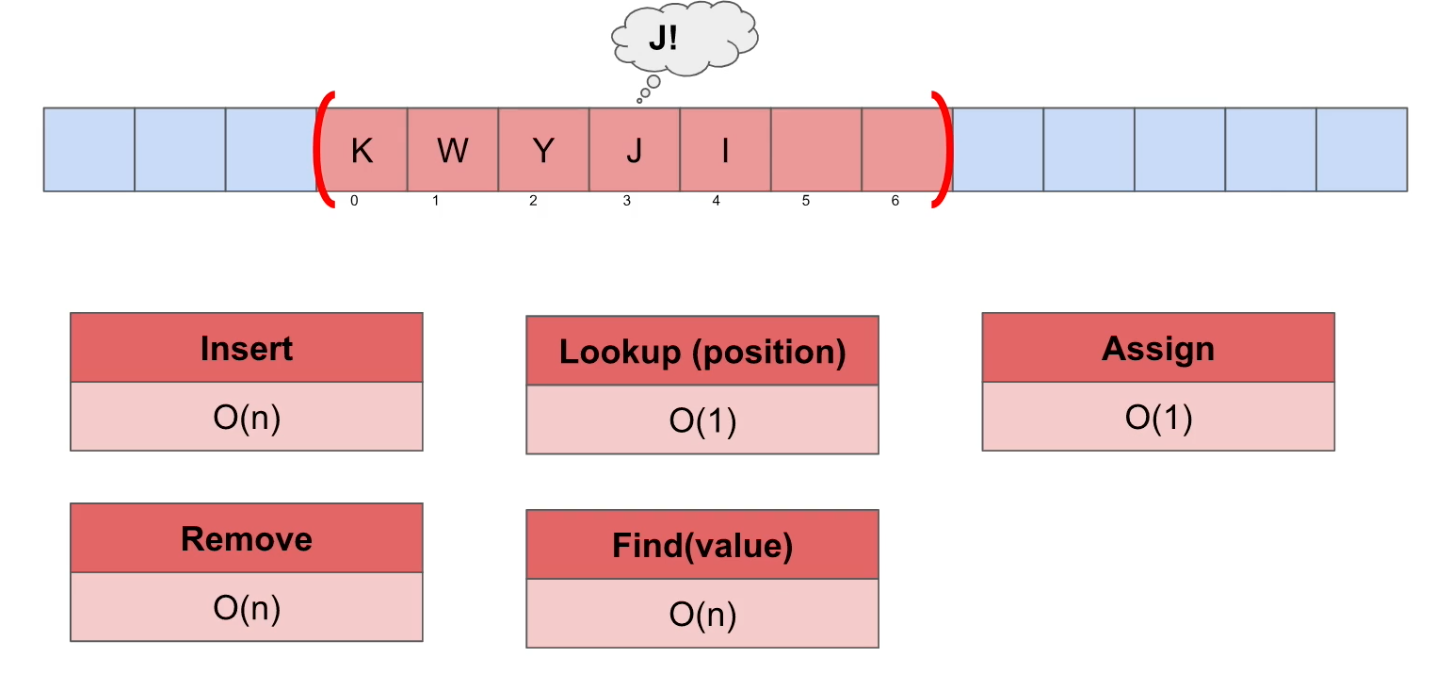
Linked Lists
Lookup(특정 위치의 데이터를 가져옴)
Big-O Notation = O(n) : linear. 데이터를 하나씩 따라가며 확인해야 한다.
Find(특정 데이터를 찾음)
Big-O Notation = O(n) : linear. 데이터를 하나씩 확인해야 한다.
Assign(특정 위치의 데이터를 교체)
Big-O Notation = O(n) : linear. 데이터를 하나씩 확인해야 한다.
Linked List는 위의 세가지 경우 모두 linear에 해당한다(O(n)).
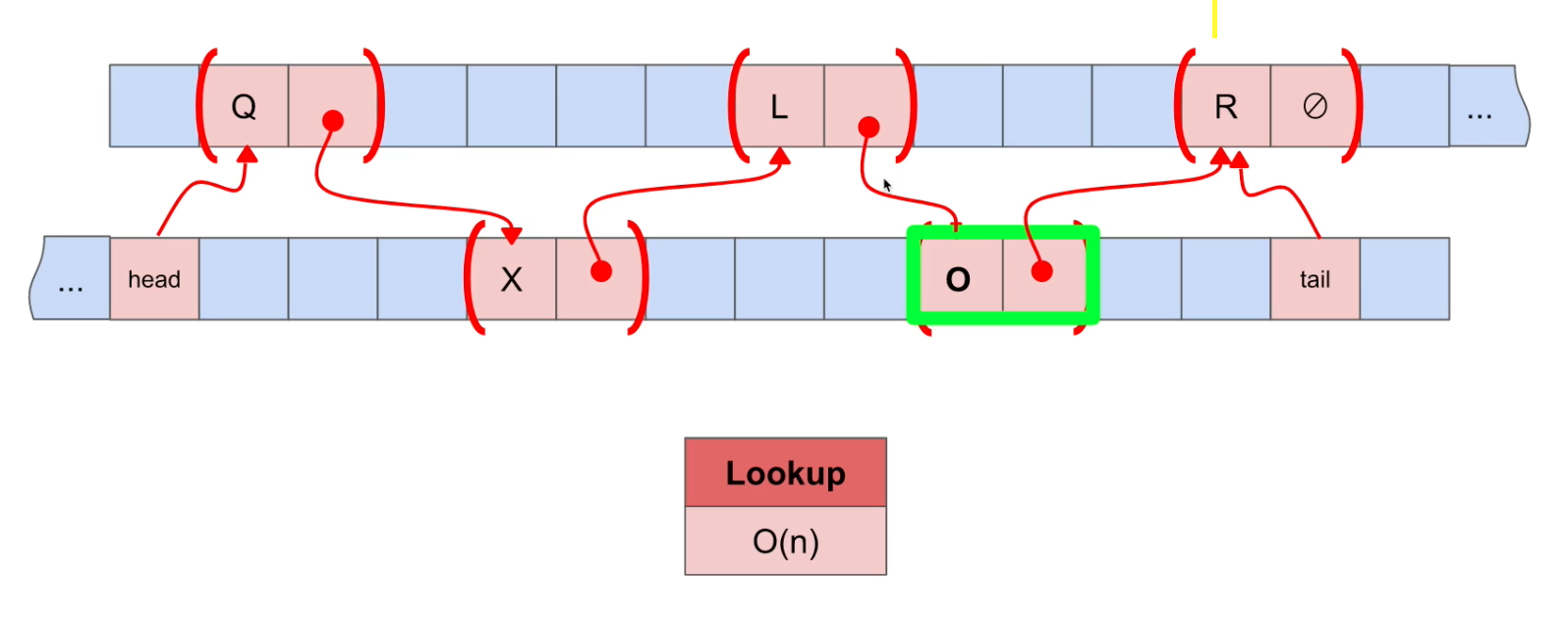
Insert(데이터를 마지막에 추가)
Big-O Notation = O(1) : constant. 마지막 데이터(R)의 넥스트 포인터를 삽입한 데이터(5)에 연결한다(총 1번의 operation). tail도 기존의 마지막 데이터에서 삽입된 데이터로 연결한다.
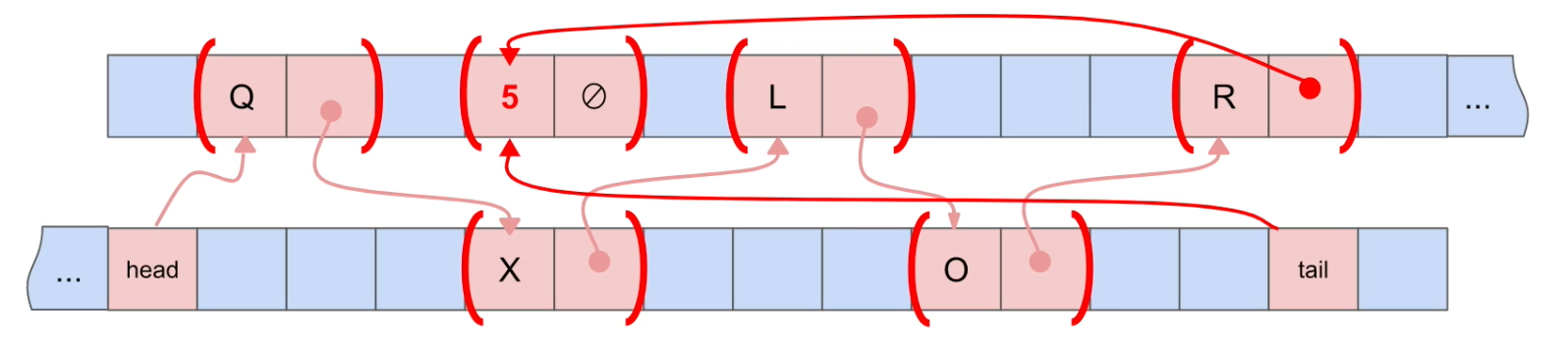
Insert(데이터를 중간에 추가)
Big-O Notation = O(1) : constant. 중간에 넣는 경우(ex. 5를 X와 L 사이에 넣는 경우)에도 넣고자 하는 위치(X)에 가 있는 경우가 많음. 그리고 그 다음 데이터도 알고 있기 때문에(L) 넥스트 포인터, 연결만 바꿔주면 됨.
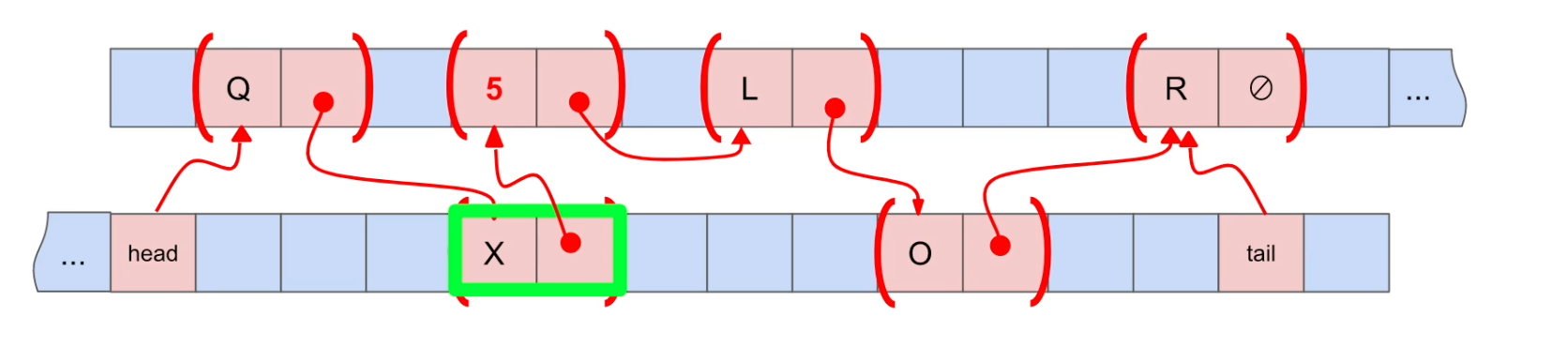
Remove(특정 위치의 데이터를 삭제)
Big-O Notation = O(n) : linear. 지우고자 하는 데이터(ex. 5)의 위치를 알고 있을 때, 이전 데이터(X)를 다음 데이터(L)와 잇고 해당 데이터(5)와 다음 데이터(L)의 연결을 끊으면 됨. 그런데 이전 데이터(X)가 뭔지 모르므로 해당 데이터(5)가 나올 때까지 조회해보아야 함.
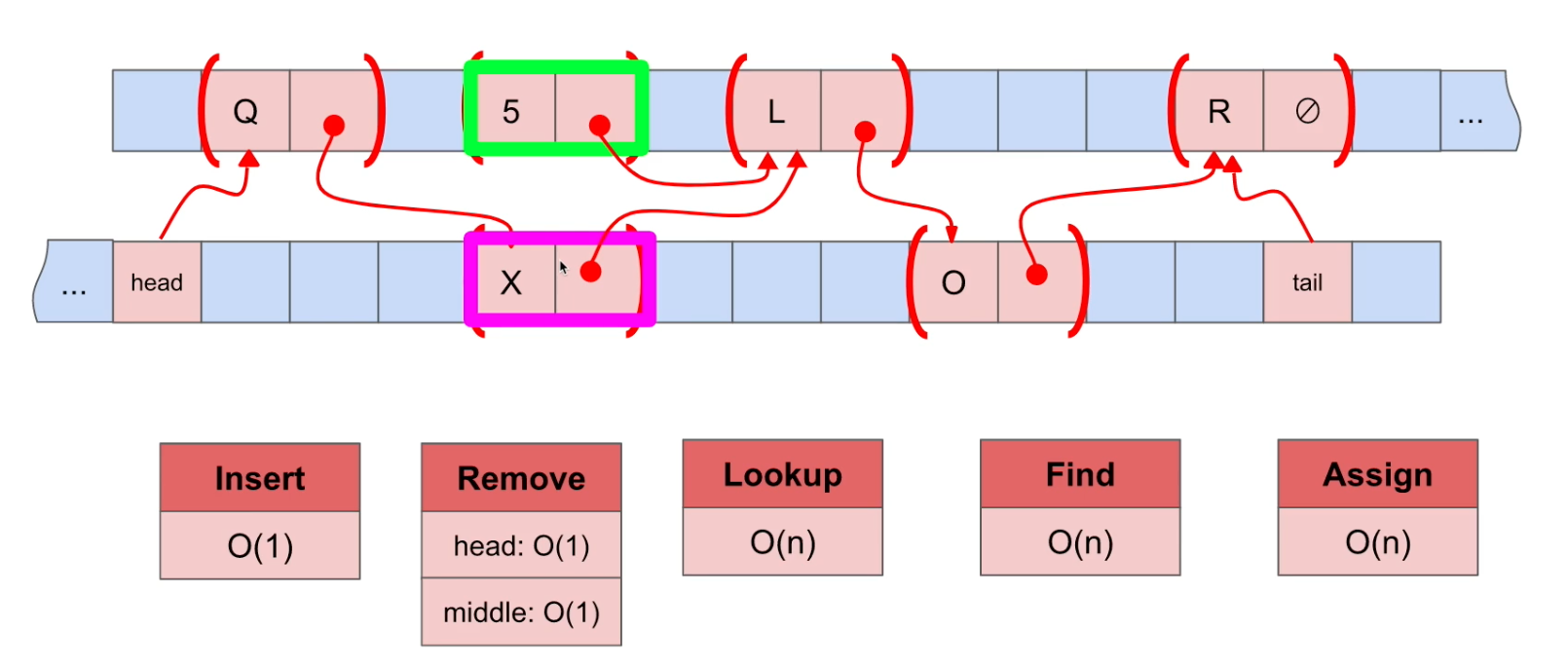
Doubly-Linked Lists
Doubly-Linked Lists는 Linked List와 다르게 이전 데이터에 대한 노드가 존재한다.
Lookup(특정 위치의 데이터를 가져옴)
Big-O Notation = O(n) : linear. 데이터를 하나씩 따라가며 확인해야 한다.
Find(특정 데이터를 찾음)
Big-O Notation = O(n) : linear. 데이터를 하나씩 확인해야 한다.
Assign(특정 위치의 데이터를 교체)
Big-O Notation = O(n) : linear. 데이터를 하나씩 확인해야 한다.
Doubly-Linked List는 역시 위의 세가지 경우 모두 linear에 해당한다(O(n)).
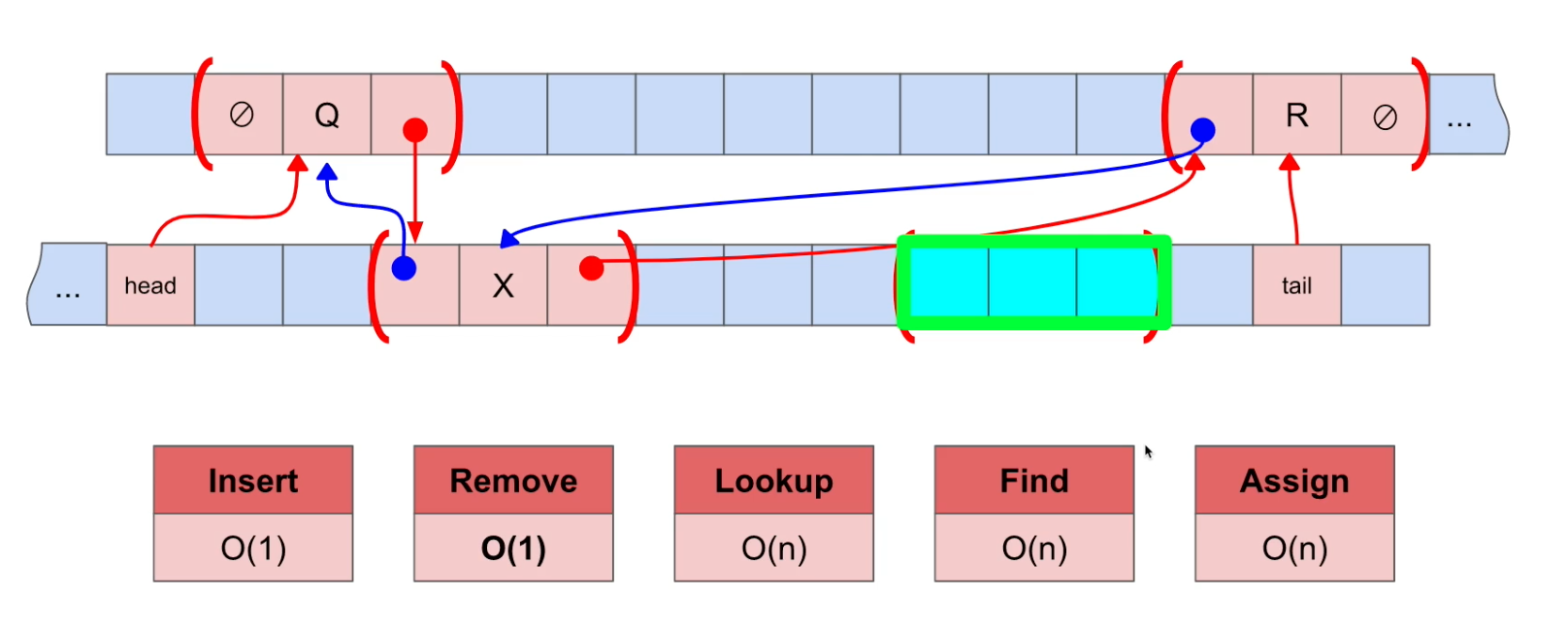
Remove(특정 위치의 데이터를 삭제)
Big-O Notation = O(1) : constant. Linked List와 이전 데이터(X)를 알고 있다. 이후 이전 데이터와 다음 데이터를 잇고 나서 배제된 데이터는 garbage collector에 의해 수거된다.
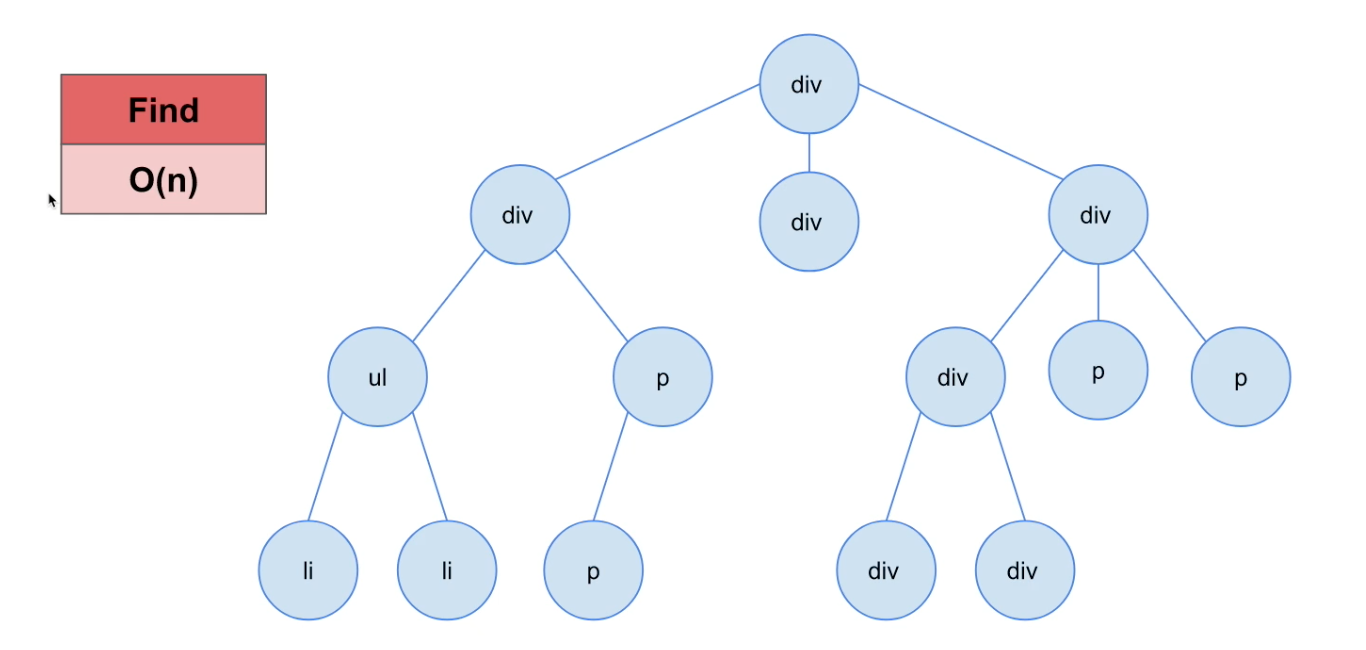
Trees
Find(특정 데이터를 찾음)
Big-O Notation = O(n) : linear. 일반적인 형태의 Tree의 경우, 데이터를 하나씩 확인해야 한다.
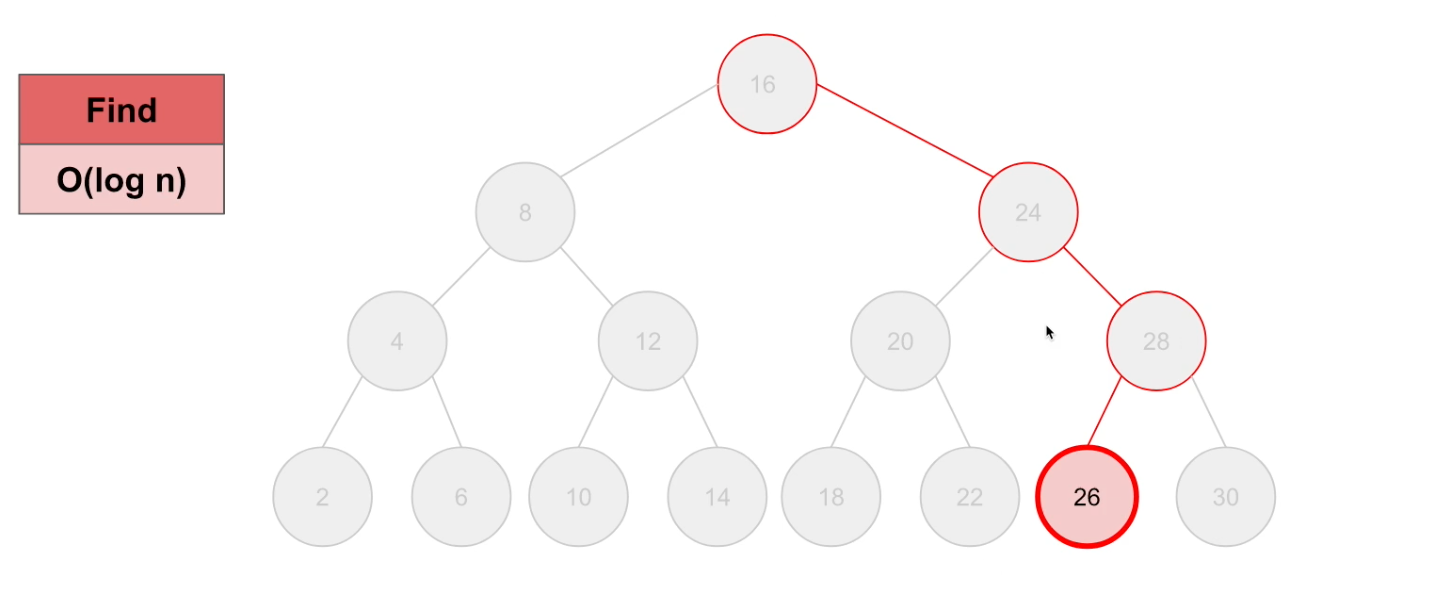
Binary Search Trees
Find(특정 데이터를 찾음)
Big-O Notation = O(log n) : logarithmic. 이진 트리의 경우 데이터의 크기에 따라 경로가 세분화되어있기에 constant보다는 느리지만 linear보다는 빠른 logarithmic(log n)의 Time Complexity를 보여준다.
다음과 같은 예시를 보자.
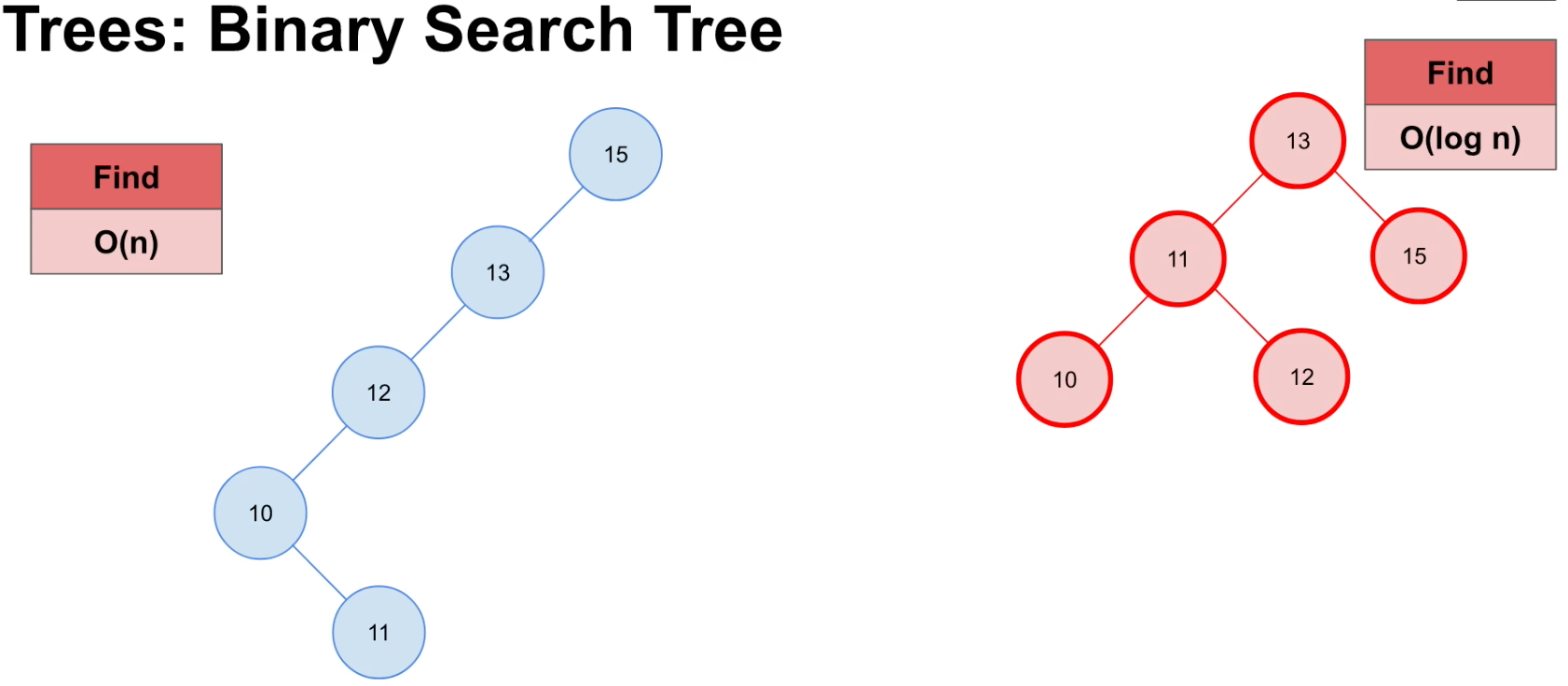
왼쪽 트리의 예시는 이진 트리임에도 불균형하게 형성되어있다. 그렇기 때문에 어떤 데이터를 찾기 위해선 타고 내려갈 수 밖에 없는 구조로 되어있고 그래서 이런 경우의 Find는 다음과 같다.
Find(특정 데이터를 찾음)
Big-O Notation = O(n) : linear. 불균형한 이진트리(왼쪽). 데이터를 하나씩 확인해야 한다.
그렇다면 균형잡힌 이진 트리는 어떤 것일까?
한 부모를 기준으로 좌우 노드 수의 비율이 2:1을 넘지 않는 것이다.
오른쪽의 트리를 보자.
13을 기준으로 했을 때, 좌(11-10 or 11-12)와 우(15)의 개수 비율이 2:1을 유지하고 있다. 왼쪽 트리의 경우는 아예 우측 노드가 없기 때문에 불균형하다고 할 수 있다.
이렇게 균형잡힌 이진 트리의 경우, 먼저 확인했듯이 특정 데이터를 찾는 Time Complexity는 O(log n) : logarithmic 이다.
