Dual-consistency semi-supervision combined with self-supervision for vessel segmentation in retinal OCTA images
인공지능 논문 리뷰
이번에 리뷰할 논문은 School of Information Science and Engineering, Central South University, Changsha 410083, China에서 ZAILIANG CHEN 외 6명이 작성한 Dual-consistency semi-supervision combined with self-supervision for vessel segmentation in retinal OCTA images 라는 논문이다.
초록, 소개, 방법론, 데이터셋 순으로 리뷰했다.
Abstract
광학상관단층촬영(OCTA)은 많은 시각 관련 질병에서 중요한 의미를 갖는 발전된 비침습 혈관 영상 기술이다. 현재 OCTA에서 망막 혈관의 자동 분할이 연구 중이며, 기존 분할 방법은 대규모 픽셀 레벨 주석 이미지(해당 이미지가 무엇인지 식별할 수 있는 설명이 붙은 이미지)가 필요하다. 그러나 레이블에 수동으로 주석을 다는 것은 시간이 많이 걸리고, 많은 노동을 필요로 한다. 따라서 이 제한된 주석의 문제를 해결하기 위해 multi-scale self-supervised puzzle subtasks(DCSS-Net)을 포함하는 dual-consistency semi-supervised segmentation network를 제안함.
Introduction
본 연구의 주요 기여
- semi-supervised segmentation 제안함. fully supervised methods와 유사한 성능을 얻기 위해 소량의 labeled data만 사용하면 되므로 OCTA 영상에서 혈관 레이블링의 어려움과 정확한 혈관 레이블이 있는 이미지의 부족을 완화시킬 수 있다.
- multi-scale self-supervised puzzle subtask가 설계됨. semi-supervised network가 좋은 feature representation을 학습할 수 있도록 지원함으로써 네트워크 성능을 향상시키는데 사용된다.
- Regularization 효과를 더욱 개선하고 정확한 분할 예측을 생성하여 unlabeled data를 최대한 활용하기 위해 data perturbation과 feature perturbation을 기반으로 하는 dual-consistency training strategy가 제안된다.
Methods
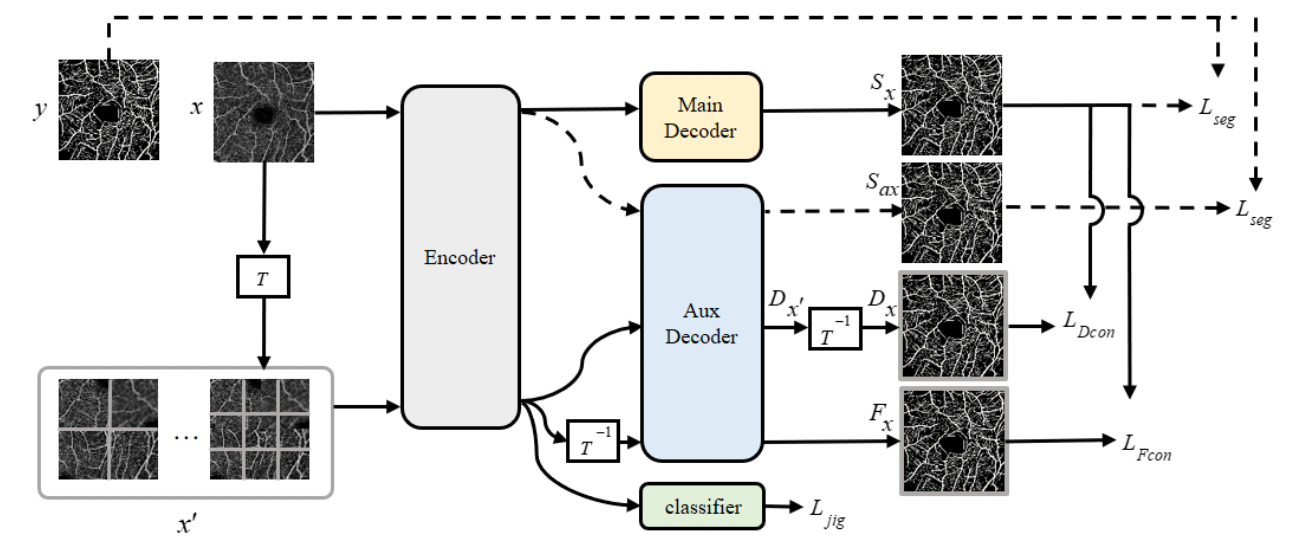
DCSS-Net Framework
- Train set: labeled data & unlabeled data
- Loss: Ljig, LDcon, Lseg, and LFcon
- Lseg(Pixel-level supervised loss): Network Segmentation을 보장하기 위해 labeled data에 사용됨.
- Ljig(Self-supervised loss): 원본 데이터의 풍부한 정보를 활용하기 위해 모든 이미지에 사용됨.
- LFcon(Feature consistency loss) & LDcon(Data consistency loss): unlabeled image에 사용되어 unlabeled data를 제한하고 segmentation 성능을 향상시킴.
self-supervised learning task를 해결해 네트워크를 최적화함.
Self-supervised tasks는 labeled image와 unlabeled image를 모두 사용해 훈련된다.
labeled images의 경우, supervised loss Lseg는 image label y와 두 decoder의 segmentation 결과 Sx와 Sax를 각각 사용해 계산된다. (main decoder와 aux decoder에 대한 각각의 segmentation 결과에 따라 Lseg가 두개 나옴)
unlabeled image의 경우, data perturbation 및 feature perturbation을 기반으로 하는 dual-consistency training strategy가 제안된다.
메인 디코더의 prediction Sx와 보조 디코더의 prediction을 역변환 한 Dx로 데이터 교란에 기반한 일관성이 계산된다.
feature perturbation 일관성에 기초해 인코딩 된 features는 직접적으로 역변환된다. 그런 다음 보조 디코더에 입력되어 결과 Fx와 메인 디코더의 예측 Sx를 얻어 일관성 손실을 계산한다. T는 이미지 타일 섞기, 뒤집기 및 회전과 같은 작업을 포함하여 본 연구의 퍼즐 subtask 변환을 의미한다.
1. Multiscale puzzle subtask
self-supervised learning에서 영감을 받음.
self-supervision은 회전 예측 및 컬러링과 같은 다양한 pretexts을 사용해 unlabeled image에서 이미지 정보를 마이닝 할 수 있다.
본 연구에서는 semi-supervised segmentation network를 지원하기 위해 self-supervised subtask로서 플립 및 회전 변환으로 구성된 multiscale puzzle을 사용한다.
jigsaw puzzle task
이미지를 동일한 조각으로 나눈다. 표준 jigsaw puzzle과 유사한 3x3 조각으로 나눠 모든 순열에서 해밍거리가 가장 큰 Q 순열을 선택해 subset을 형성한다. 그리고 매번 이 subset에서 하나의 순열을 선택하고 분류기를 사용해 subset에서 어떤 순열이 선택될지 예측함.
Ljig는 이 subtask를 감독하기 위해 교차 엔트로피 손실 함수를 사용한다.
jigsaw puzzle task를 semi-supervised framework에 통합하기 위해, 고전적인 self-supervised 접근 방식에서처럼 각 타일에 대해 공유 가중치 신경망을 사용하는 대신 셔플된 타일을 원래 크기 이미지로 조립한다. 그런 다음 분류를 위해 네트워크로 보낸다.
이 연구에서는 퍼즐 분할 스케일로 2x2와 3x3을 선택했다. 2x2 스케일의 subset 크기 Q는 20으로 설정되고, 3x3 스케일의 subset 크기 Q는 100으로 설정된다. subset은 Q만큼 각 2x2 스케일과 3x3 스케일의 순열 세트에서 훈련중에 선택되며, 영상은 임의로 섞이고 뒤집히고 회전한다. 그런 다음, 입력 네트워크는 학습을 위해 재조립된다.
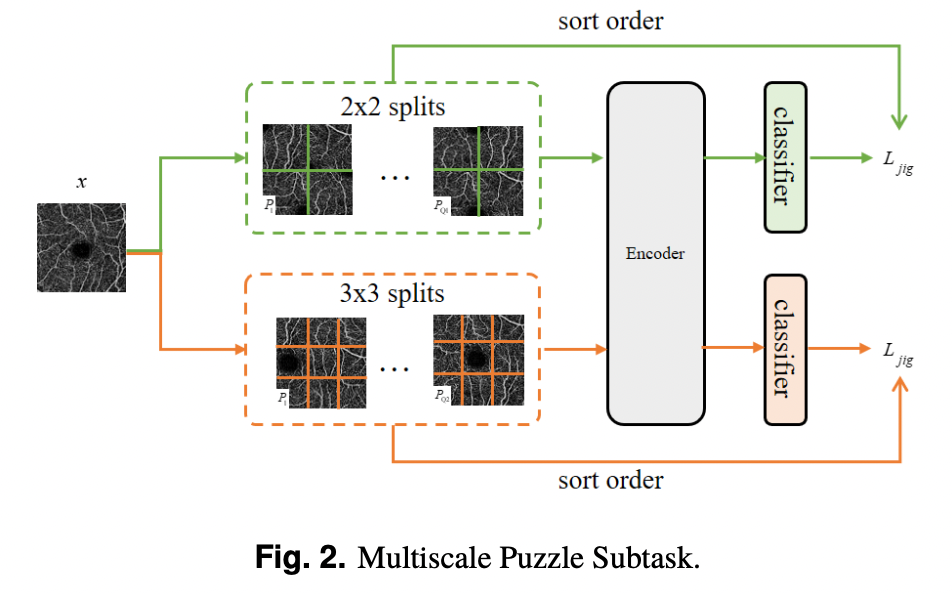
fig2에 대한 이해
input 이미지 x를 2x2, 3x3 두가지 방법으로 분할한다. 이 때 단일 스케일 변환을 쓰지 않고 multiscale 방법을 쓰는 이유는 동일한 위치에서 혈관 이미지를 분할해 이미지 연속성 학습이 저하되는 것을 막고, 타일의 가장자리인 경우 정보가 부족하기 때문에 이를 보완하기 위해 타일을 서로 다른 위치에서 분할해 두 가지의 다른 스케일 변환을 사용한다. 이 때 분할해서 셔플한 후 원래 이미지와 비교해 해밍거리가 가장 큰 이미지들을 재조립한 결과를 subset으로 해 인코더에 넣고, 이 subset에서 하나의 순열을 선택한 다음 분류기를 이용해 어떤 순열이 선택되었는지 예측한다. 그리고 분류기의 예측값을 원래값 인덱스와 비교해 오차를 계산한다.
*Flipping: 이미지 상하반전
2. Dual-consistency learning
- DCSS-Net은 semi-supervised learning에 널리 사용되는 일관성(consistency) 훈련을 채택한다. 그러나 네트워크 구조를 수정하지 않고 data perturbation과 feature perturbation based 이중 일관성 정규화를 모두 가지고 있어 기존 방법과 다르다.
- data perturbation based consistency: 본 연구의 기법의 장점은 jigsaw-transformed 이미지를 추가적인 data perturbation 없이 perturbed image로 직접 사용할 수 있다는 것이다.
그림 1과 같이 self-supervised subtask의 영상 x를 타일로 섞은 후 회전하고 플립하여 x’를 얻는다. 입력 네트워크에 의해 얻어진 분할 결과 Dx’의 변환을 반전시킨 후, 최종 분할 결과 Dx를 얻는다. 일관성 손실 LDcon은 원본 영상의 분할 결과 Sx로 구성된다.
feature perturbation-based consistency regularization: unlabeled data를 최대한 활용하고 과적합을 방지하기 위해 도입. 본 연구의 네트워크 구조는 인코딩 및 디코딩 구조를 기반으로 한다. jigsaw-transformed 이미지 x’는 인코딩된 feature를 얻기 위해 인코더에 입력되며, 그 feature는 반대로 변환된다. 그런 다음, 이러한 특징들이 보조 디코더에 입력되어 혈관 분할 결과 Fx를 얻는다.
일관성 손실 LFcon은 feature perturbation에 기반해 평균 제곱 오차를 사용해 계산된다.
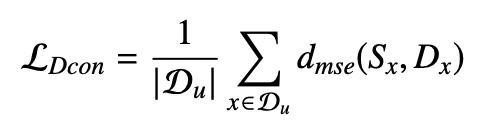
Data perturbation MSE
dmse(Sx,Dx)는 Sx,Dx의 평균 제곱오차, Du는 unlabeled training data.
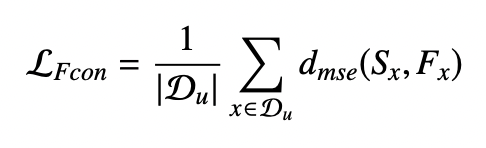
feature perturbation MSE
dmse(Sx,Fx)는 Sx,Fx의 평균 제곱오차, Du는 라벨링 안된 훈련데이터.
3. Loss function
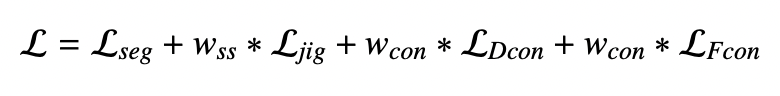
- Wcon: 메인 디코더의 원시 노이즈 예측을 사용하지 않기 위한 비지도 가중치 증가 함수
- Wss: puzzle subtask의 분류 손실 가중치
- Lseg: labeled image에 대해 감독되는 손실로, 교차 엔트로피 손실을 손실 함수로 사용
- LDcon & LFcon: 각각 data perturbation-based and feature perturbation-based 일관성 손실로, 메인 디코더와 보조 디코더의 출력 차이를 측정한다.
- Ljig: 모든 훈련 이미지의 puzzle subtask에 대한 분류 손실로, 교차 엔트로피 손실을 손실 함수로 사용한다.
Experiments
1. Datasets
본 연구에서, 제안한 DCSS-Net은 두 개의 망막 OCTA 이미지 데이터 세트에서 평가된다. 하나는 공개 데이터 세트 ROSE-1이고 다른 하나는 개인 데이터 세트이다.
ROSE-1 데이터 세트는 공개 OCTA 데이터셋.
39개 피사체의 SVC, DVC 및 SVC+DVC의 세 가지 수준에서 총 117개의 이미지를 포함하고 있으며, 각 이미지의 크기는 304×304 픽셀이다. 39개의 이미지를 포함하여 혈관이 풍부한 SVC 이미지를 실험에 사용하는데, 이 중 30개가 훈련 세트를 구성하고 9개가 테스트 세트이다. 이 데이터 세트에는 혈관 중심선 주석 및 픽셀 수준 주석이 있는 영상도 포함되어 있습니다. 이 연구에서는 픽셀 수준의 주석을 실험에 사용한다.
또한 Changsha Aier Eye Hospital에서 62개의 표면 OCTA 혈관 이미지를 수집했는데, 이 중 40개는 훈련 세트로 사용되었고 22개는 테스트 세트로 사용되었다. 400 × 400 픽셀 크기의 사용된 모든 이미지는 옵토뷰 OCTA 장치에 의해 포베아 중심의 6 × 6 mm 스캔 영역에 캡처되었다. 혈관은 5년 경력의 안과 의사가 픽셀 단위로 주석을 달았다.
