12일차
- 오늘은 앙상블에 대해서 배워볼 예정이다
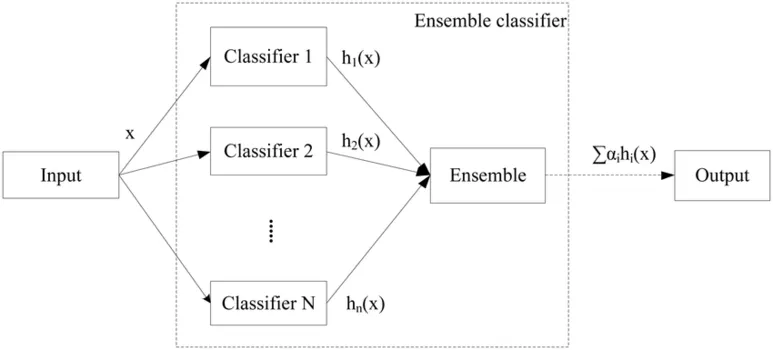
Ensemble(앙상블)
- 특별한 Machine Learing 알고리즘이 아니라
- 여러 모델을 결합해서 성능을 높이는 기법이다!
- 즉, 여러 개의 분류기(classifier)를 생성하고 그 예측을 결합해 더 정확한 결과를 도출해내는 기법이다.
- 크게, 보팅(voting), 배깅(bagging), 부스팅(boosting)으로 분류
Voting(보팅)
- 여러 개의 모델이 투표를 통해 최종 결과를 예측하는 방법이다
- 서로 다른 n개의 모델을 사용
- hard voting(하드 보팅)과 soft voting(소프트 보팅) 2가지
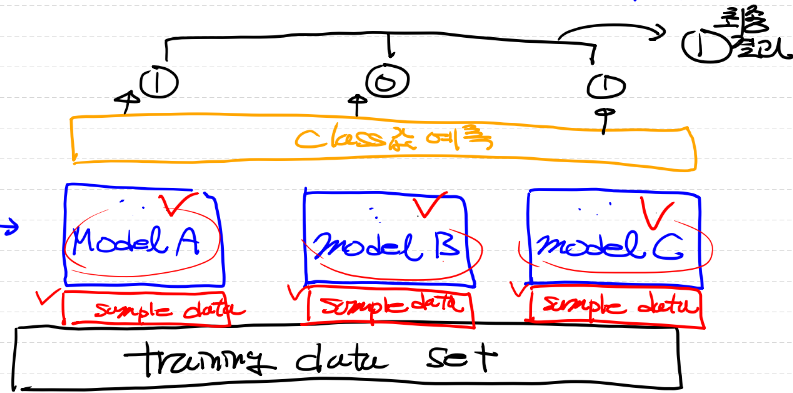
- hard voting은 아래 그림과 같이 여러 개의 모델 중 다수의 모델이 예측한 결과를 최종 결과로 선택하는 방법
- 다수결의 원칙이라고 생각하면 된다
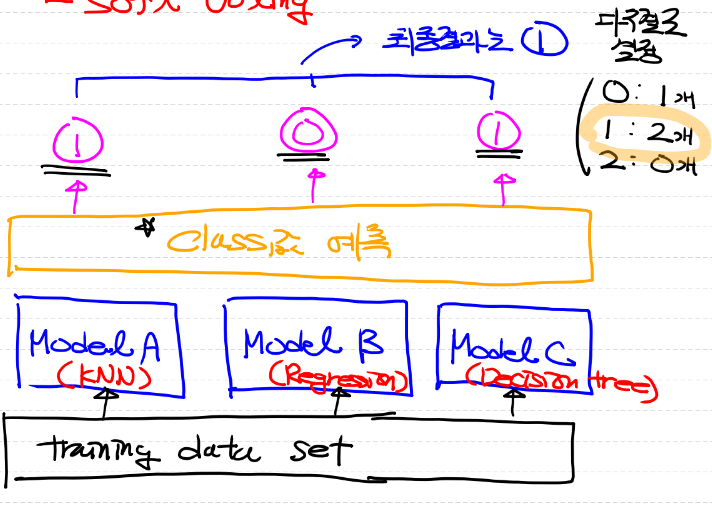
- 다수결의 원칙이라고 생각하면 된다
- soft voting은 각각의 모델의 label값 결정 확률을 모두 더해 평균을 구한 다음 확률이 가장 높은 label 값을 최종 결과로 선택하는 방법
- 일반적으로 hard voting 보다 많이 사용
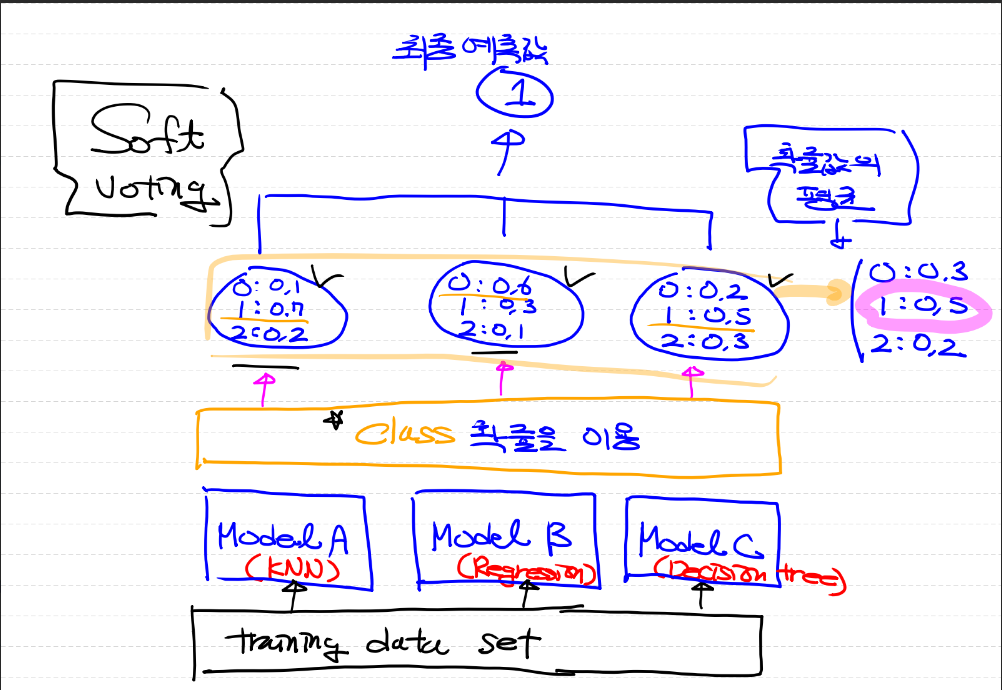
- 위 그림에서 보면 label 0, lable 1, label 2 각각의 확률 평균은 0.3, 0.5, 0.2로 확률이 가장 높은 label 1을 최종 선택한 것을 알 수 있다.
- 일반적으로 hard voting 보다 많이 사용
Bagging(배깅)
- voting과 실행 방식이 유사하지만 차이점이라면, 서로 다른 n개의 모델이 아닌 같은 모델 n개를 사용!!
- 대표적인 bagging 알고리즘으로 random forest가 있다
- 같은 모델을 사용하므로 모델을 좀 더 다양하게 만들기 위해
- 샘플을 여러 번 뽑아 데이터를 재구성하는 부트스트랩(bootstrap) 사용
- 학습 데이터가 충분하지 않아도 충분한 학습효과를 주어 높은 편향(bias)나 underfitting/overfitting 등의 문제를 해결하는데 도움
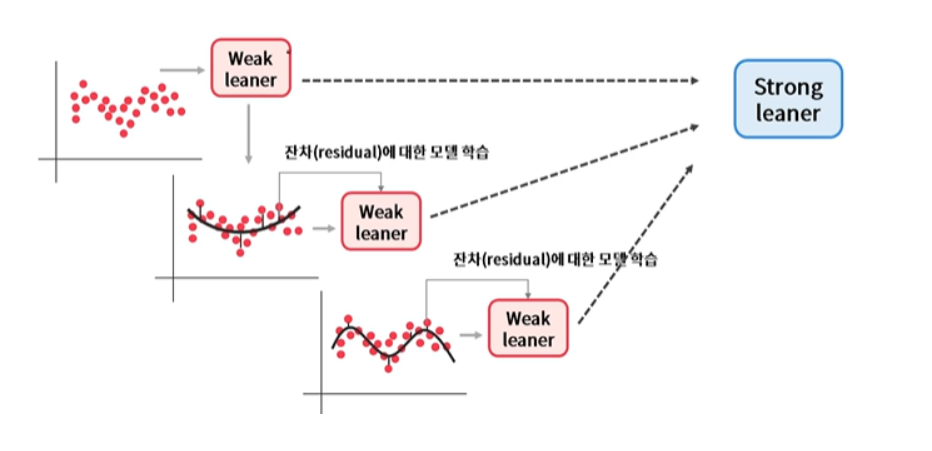
Boosting(부스팅)
- 여러 개의 가벼운 모델을 순차적으로 학습하는 방법
- 잘못 예측한 데이터에 대해 오차를 줄일 수 있는 방향으로 model update 해나가는 방식
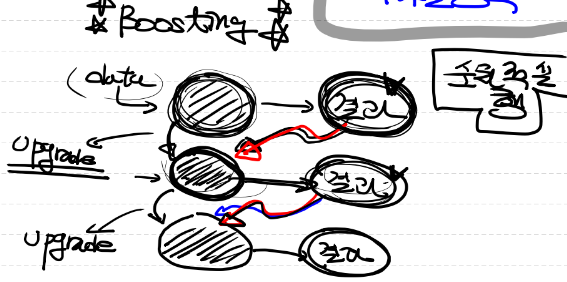
- 위 그림처럼 이전 단계에 학습된 결과를 가지고 모델을 update하는 방향으로 진행
- 크게 AdaBoost, GBM, XGBoost 등이 있다
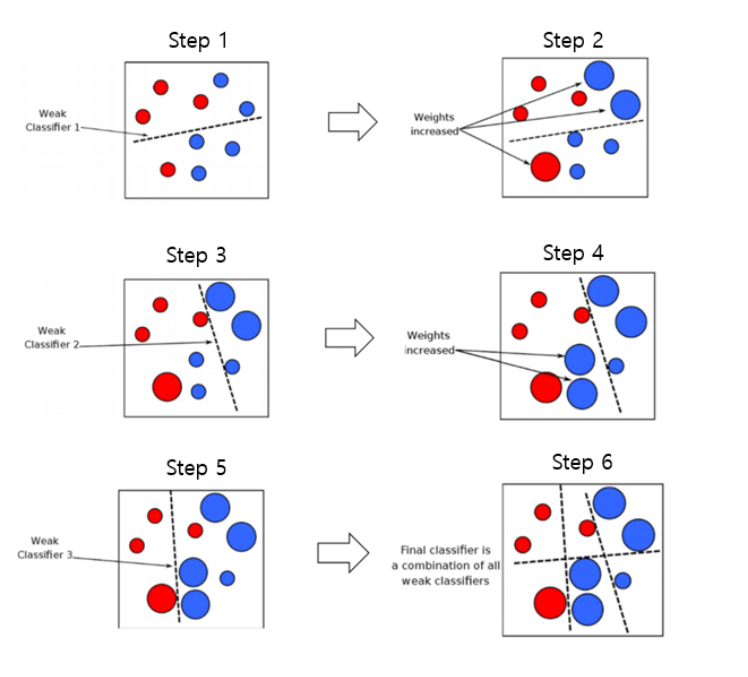
AdaBoost
- 오류 데이터에 가중치를 부여하며 부스팅을 수행하는 방식
GBM(Gradient Boosting Machine)
- 가중치 업데이트 방식으로 Gradient Descent(경사하강법) 사용
- 반복 수행을 통해 오류(실제-예측)를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법
- 예측 성능은 뛰어나나 수행 시간이 오래 걸린다는 단점이 있다
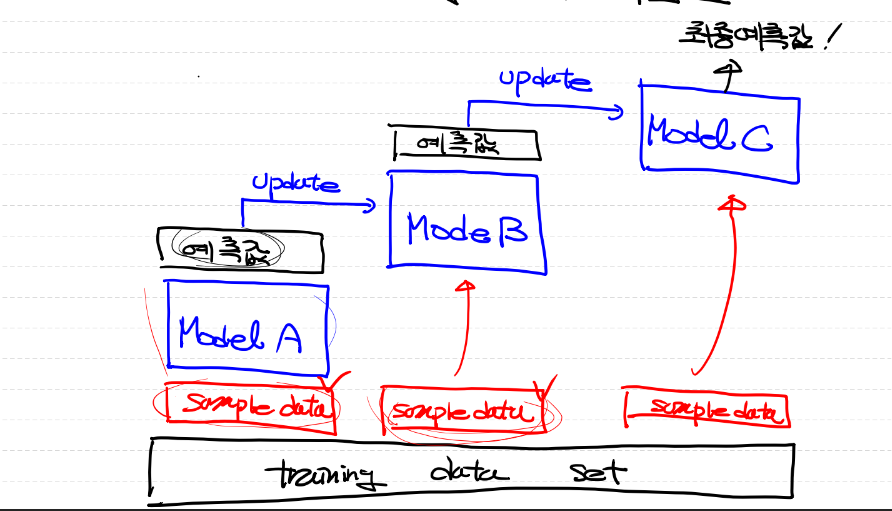
XGBoost
- 일반적으로 많이 사용되는 boosting 알고리즘 기법
- 뛰어난 예측 성능, 빠른 수행시간, 과적합 규제 등의 장점이 존재
- 아래 그림과 같은 방식으로 진행
코드
- 앙상블(Ensemble) 구현
- iris 데이터 사용, 모델은 knn, svm, decision tree 3개 사용
Voting
- 라이브러리 호출 및 전처리
# 필요 module import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import VotingClassifier
# Raw Data Loading
iris = load_iris()
# DataFrame으로 변환해서 처리하는게 쉽고 편해요!
df = pd.DataFrame(iris.data,
columns=iris.feature_names)
df.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
df['target'] = iris.target
# display(df)
# 결측치와 이상치는 없다고 가정하고 진행!
# 중복데이터 처리
df = df.drop_duplicates()
# 이제 x_data와 t_data를 추출하면 될 거 같아요!
# x_data는 4개의 feature
x_data = df.drop(['target'],
axis=1,
inplace=False).values
t_data = df['target'].values
# 데이터 분리보다 정규화를 먼저 진행하는게 조금 더 편해요!
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# 데이터 분리
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
test_size=0.3,
stratify=t_data,
random_state=0)- 각각의 model 구현
# KNN 구현
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_data_train_norm,
t_data_train)
knn_acc = accuracy_score(t_data_test, knn.predict(x_data_test_norm))
print(f'KNN 모델의 정확도 : {knn_acc}')
# SVM 구현
svm = SVC(kernel='linear',
C=0.5,
probability=True)
svm.fit(x_data_train_norm,
t_data_train)
svm_acc = accuracy_score(t_data_test, svm.predict(x_data_test_norm))
print(f'SVM 모델의 정확도 : {svm_acc}')
# DT 구현
dt = DecisionTreeClassifier()
dt.fit(x_data_train_norm,
t_data_train)
dt_acc = accuracy_score(t_data_test, dt.predict(x_data_test_norm))
print(f'DT 모델의 정확도 : {dt_acc}')
- 앙상블 모델 생성
# 앙상블 모델을 만들어요!
# hard voting classifier(hvc)
hvc = VotingClassifier(estimators=[('KNN',knn),
('SVM',svm),
('DT',dt)],
voting='hard')
hvc.fit(x_data_train_norm, t_data_train)
hvc_acc = accuracy_score(t_data_test, hvc.predict(x_data_test_norm))
print(f'앙상블 모델(hard voting)의 accuracy : {hvc_acc}')
# soft voting classifier(svc)
svc = VotingClassifier(estimators=[('KNN',knn),
('SVM',svm),
('DT',dt)],
voting='soft')
svc.fit(x_data_train_norm, t_data_train)
svc_acc = accuracy_score(t_data_test, svc.predict(x_data_test_norm))
print(f'앙상블 모델(soft voting)의 accuracy : {svc_acc}')
Bagging
- Decision Tree를 모아서 만든 Random Forest를 구현
%reset
# 앙상블 Bagging을 구현해 보아요!
# Decision Tree를 모아서 만든 Random Forest를 구현
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# Raw Data Loading
iris = load_iris()
df = pd.DataFrame(iris.data,
columns = iris.feature_names)
df.columns = ['sepal_height','sepal_width','petal_height','petal_width']
df['target'] = iris.target
# 결측치, 이상치는 없다고 가정
# 중복 데이터 정리
df = df.drop_duplicates()
# 데이터셋 준비
x_data = df.drop('target',axis=1,inplace=False).values
t_data = df['target'].values
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# 데이터 분리
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
stratify=t_data,
test_size=0.3,
random_state=0)
# DT 구현
dt = DecisionTreeClassifier()
dt.fit(x_data_train_norm,
t_data_train)
dt_acc = accuracy_score(t_data_test, dt.predict(x_data_test_norm))
print(f'DT 모델의 정확도 : {dt_acc}')
# Random Forest 구현
# n_estimators = decision tree의 개수
# max_depth = 트리의 높이 지정
rcf = RandomForestClassifier(n_estimators=50,
max_depth=3,
random_state=20)
rcf.fit(x_data_train_norm, t_data_train)
rcf_acc = accuracy_score(t_data_test, rcf.predict(x_data_test_norm))
print(f'RandomForest 모델의 accuracy : {rcf_acc}')
Boosting
- XGBoost 기법 사용
# 앙상블 boost
%reset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier
# Raw Data Loading
iris = load_iris()
df = pd.DataFrame(iris.data,
columns = iris.feature_names)
df.columns = ['sepal_height','sepal_width','petal_height','petal_width']
df['target'] = iris.target
# 결측치, 이상치는 없다고 가정
# 중복 데이터 정리
df = df.drop_duplicates()
# 데이터셋 준비
x_data = df.drop('target',axis=1,inplace=False).values
t_data = df['target'].values
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# 데이터 분리
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
stratify=t_data,
test_size=0.3,
random_state=0)
xgb = XGBClassifier(n_estimators=50,
max_depth=3,
random_state=20)
xgb.fit(x_data_train_norm, t_data_train)
xgb_acc = accuracy_score(t_data_test, xgb.predict(x_data_test_norm))
print(f'XGB 모델의 정확도 : {xgb_acc}')
