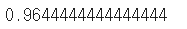11일차
- 오늘은 Decision Tree(결정 트리)에 대해서 알아보도록 하겠다
Decision Tree(의사결정 트리)
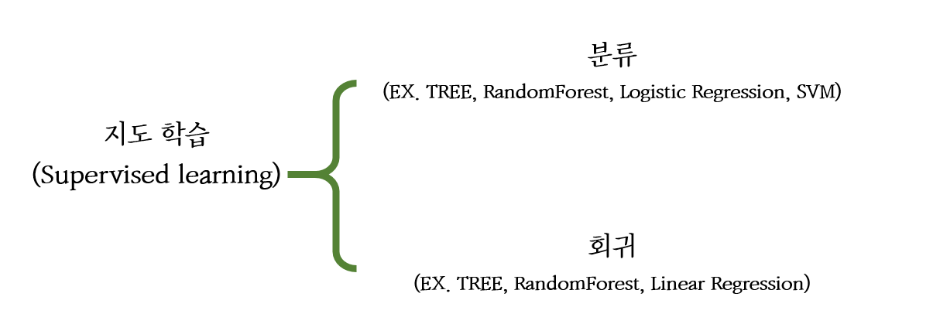
- 앞서 배웠듯이 머신러닝에는 지도학습과 비지도 학습이 존재
- 그 중, 지도 학습은 훈련 데이터와 정답이 모두 포함된 경우
- 이러한 지도 학습은 크게 두 가지로 나뉜다
- 분류(Classification)
- 전형적인 지도학습의 형태로, 예측하고자 하는 종속변수가 범주형일 때, class를 예측하는 것
- 회귀(Regression)
- 특성(feature)를 활용해서 연속형 종속변수를 예측하여 해당 class에 속할 확률을 수치화 해서 표현하는 것

- 결정 트리는 위 두 가지의 경우 중 분류(classification)에 좀 더 적합!
- 사람의 의사결정 방식 및 판단 기법과 매우 유사
- 장점
- 속도가 빠르고 간단
- 데이터에 따라 상대적으로 다른 model에 비해서 성능이 좋음
- 단점
- 독립변수가 이산데이터인 경우에는 적합하지 않다!
- class의 수가 많은 경우, 사용하기 어려움
- 데이터의 수가 적은 경우에도 좋지 않다
Decision Tree 생성 예시
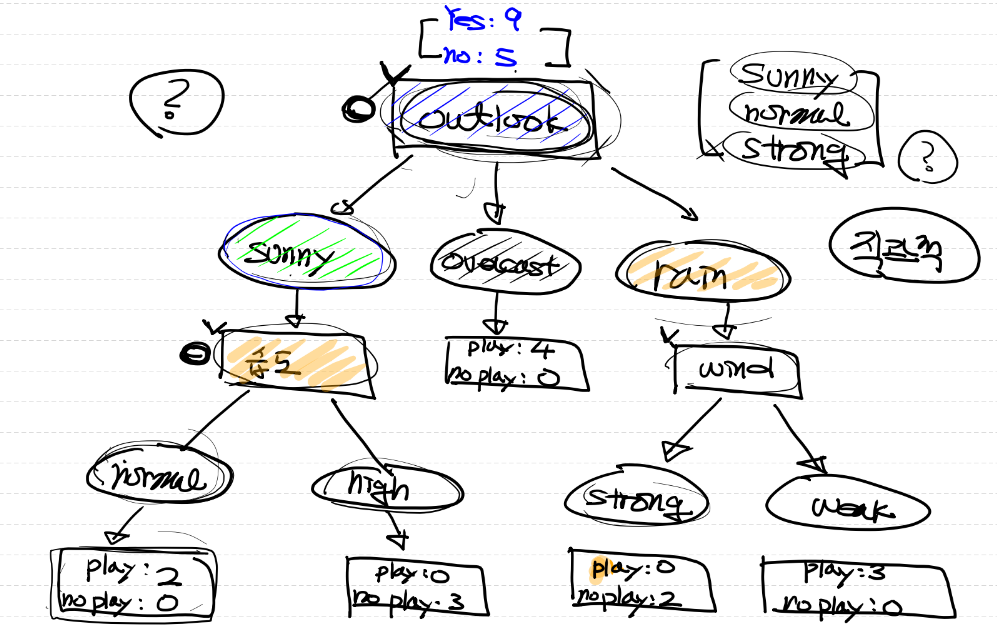
- 위와 같은 형태로 decison tree를 구성하려고 할 때,
- 어떤 기준(feature)을 가지고 Tree를 만들어야 하는지가 중요!
- decision tree의 경우, tree를 분기해 나가는(만들어가는) 과정이
학습 과정이다!!
- 그럼 그 기준은??
- 순도(homogeneity)가 높고,
- 불순도(impurity) 혹은 불확실성(entropy)가 낮은 방향으로 분기!!
-> 즉 순도가 증가하고 불순도(불확실성)가 감소하는 방향
정보 획득과 엔트로피
- 정보 획득은 분기 이전의 불순도와 분기 이후의 불순도의 차이를 의미
- 이를 수치화 시킨 것이 정보 획득량이다
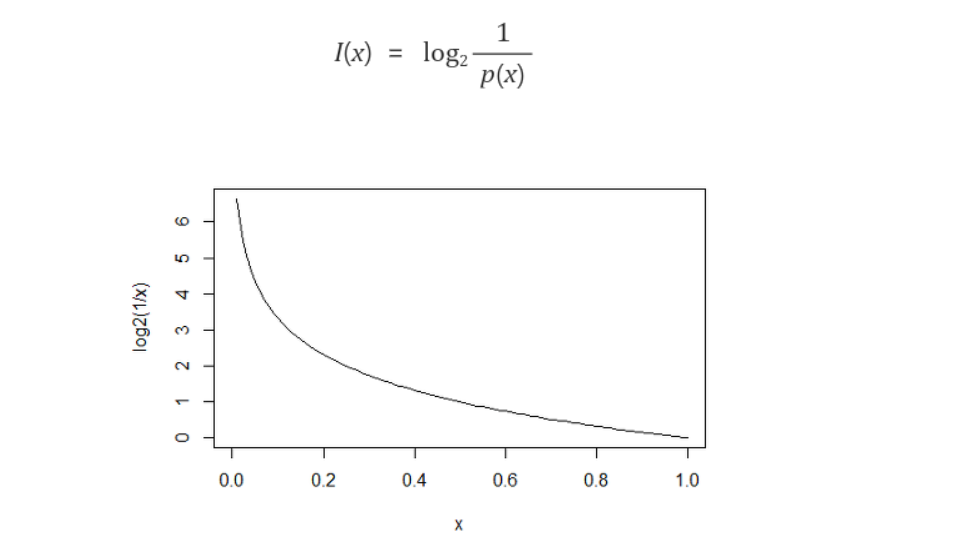
- 정보획득량을 계산하기 위한 정보 함수는 위와 같으며,
- 무조건 일어날 일(확률이 1)일 수록 0에 수렴하고 거의 일어나지 않을 일(확률이 0)일 수록 무한대로 수렴한다!
ex) 아침에 해가 동쪽에서 뜨는 경우 -> 확률 1
아침에 해가 북쪽에서 뜨는 경우 -> 확률 0
- Entropy(불확실성)
- 무질서 정도를 정량화 한 값으로 이 값이 높다는 것은 무질서도가 높은,
- 즉, 특징을 찾기 힘들다는 것을 의미한다.
- 엔트로피 함수는 다음과 같다
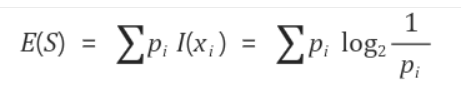
- A에서 B로 전이할 때,
- 불확실한 상황(entropy가 높다) -> 정보량이 많다
- 불확실하지 않은 상황(entropy가 낮다) -> 정보량이 작다!

Decision Tree 정리
- 상태의 전이
- 순도가 증가하는 방향으로 진행
- entropy가 최대한 감소하는 방향으로 진행
- 하나의 영역에 대해서
- 동일한 범주의 data만 존재하는 경우
-> 불확실성 0
- 두 범주의 데이터가 반반씩 존재하는 경우
-> 불확실성 1
KNN(K-Nearest Neighbors)
- 지도학습의 알고리즘 중 하나
- 말 그대로, 비슷한 특성이나 속성을 가진 값들끼리 모여있는 것을 의미
- 데이터에 대해, 거리가 가까운 K개의 다른 데이터들의 레이블을 파악해
- 빈도수가 가장 높게 나온 데이터의 레이블로 분류하는 것
- 반드시 정규화를 진행해야 한다는 특징이 있다.
- 아래 그림은 검은색 점을 KNN을 이용해 분류하는 예시이다
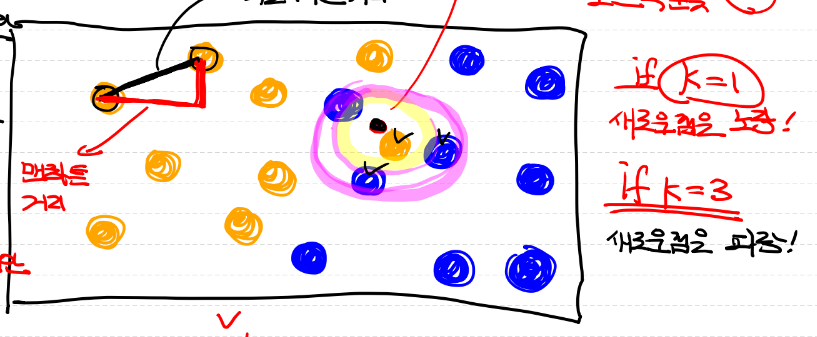
- 일반적으로 k = 1인 경우, 수학적으로 어느정도 성능이 보장됨을 의미
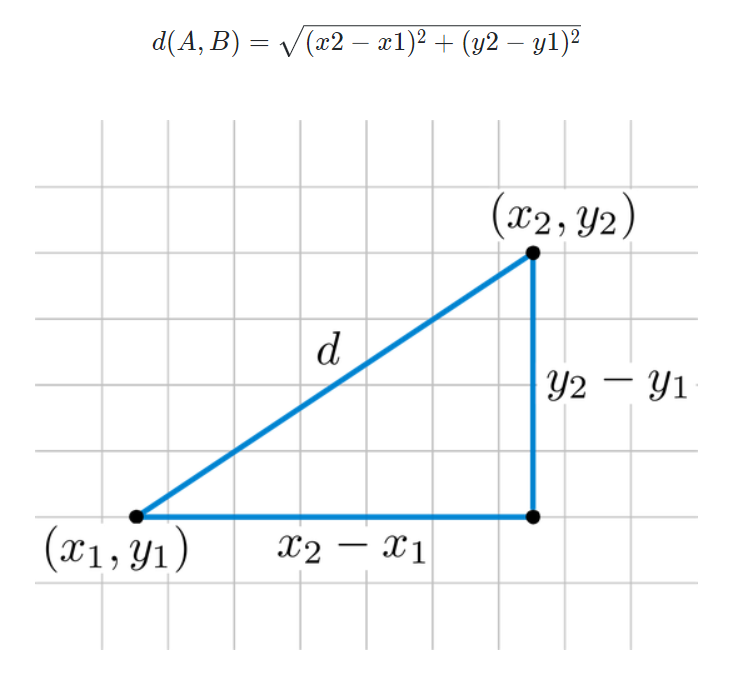
유클리디안 거리
- KNN 알고리즘에서의 거리계산 방법
주의점
- 구현 시, 변수의 범위값을 재조정해야 한다!
- why?
- 거리 측정 시, 숫자를 사용하므로 변수 값의 범위를 재조정해줘야 변수의 중요도를 고르게 해석할 수 있기 때문!
- 그럼 어떻게 재조정해요?
-> 정규화 사용하면 된다
코드 구현
# result_ori -> 엔트로피 구하는 공식
# np.log2() -> 주어진 값의 이진 로그를 계산하여 반환
import numpy as np
result_ori = -(10/16 * np.log2(10/16)) - (6/16*np.log2(6/16))
result_ori
# R1 영역
r1 = (8/16) * -((7/8)*np.log2(7/8) + (1/8)*np.log2(1/8))
# R2 영역
r2 = (8/16) * -((5/8)*np.log2(5/8) + (3/8)*np.log2(3/8))
result = r1 + r2
result
# 따라서 정보 획득량은!
# 전체 entropy - 분기 후 entropy
result_ori - result
- 아래 그림에 대한 코드

# root node를 wind로 분류해서 entropy 계산
# weak -> [yes 6, no 2]
# strong -> [yes 3, no 3]
result_wind_weak = (8/14) * -((6/8)*np.log2(6/8) + (2/8)*np.log2(2/8))
result_wind_strong = (6/14) * -((3/6)*np.log2(3/6) + (3/6)*np.log2(3/6))
result_wind = result_wind_weak + result_wind_strong
result_wind
# sunny -> [yes 2 no 3]
# overcast -> [yes 4 no 0]
# rain -> [yes 3 no 2]
result_outlook_sunny = 5/14 * (-2/5 * np.log2(2/5) - 3/5 * np.log2(3/5))
result_outlook_overcast = 4/14 * (-4/4 * np.log2(4/4))
result_outlook_rain = 5/14 * (-3/5 * np.log2(3/5) - 2/5 * np.log2(2/5))
result_outlook = result_outlook_sunny + result_outlook_overcast + result_outlook_rain
result_outlook
# humidity
# high -> [yes 3 no 4]
# normal -> [yes 6 no 1]
result_humidity_high = 7/14 * (-3/7 * np.log2(3/7) - 4/7 * np.log2(4/7))
result_humidity_normal = 7/14 * (-6/7 *np.log2(6/7) - 1/7 * np.log2(1/7))
result_humidity = result_humidity_high + result_humidity_normal
result_humidity
# 전체 데이터를 wind로 분류했을때 우리가 얻을 수 있는 정보량
print(result - result_wind)
# 전체 데이터를 outlook으로 분류했을때 우리가 얻을 수 있는 정보량
print(result - result_outlook)
# 전체 데이터를 humidity로 분류했을때 우리가 얻을 수 있는 정보량
print(result - result_humidity)
- iris(붓꽃) 데이터를 활용한 decison tree
# 위와 같은 Decision Tree를 사용하려면 어떻게 해야하나요?
# sklearn을 이용해서 사용하면 되요!
# iris 예제를 이용하여 Decision Tree를 구현해 보아요
# feature는 2개만 사용할 거에요!(꽃받침의 길이, 꽃잎의 길이)
# 필요 module import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from mlxtend.plotting import plot_decision_regions
from sklearn.tree import DecisionTreeClassifier
# Raw Data Loading
iris = load_iris()
df = pd.DataFrame(iris.data,
columns=iris.feature_names)
df.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
df['target'] = iris.target
# 중복 데이터 정리
df = df.drop_duplicates()
# 데이터셋 준비
x_data = df.drop(['sepal_width', 'petal_width','target'],axis=1,inplace=False).values
t_data = df['target'].values
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# 데이터 분리
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
stratify=t_data,
test_size=0.3)
# 모델 생성
model = DecisionTreeClassifier()
model.fit(x_data_train_norm,
t_data_train)
# Evaiuation
score = accuracy_score(t_data_test, model.predict(x_data_test_norm))
# 시각화
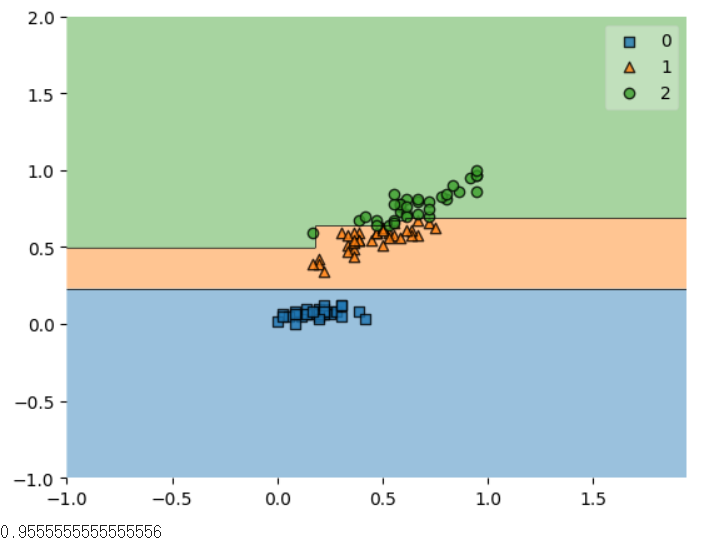
plot_decision_regions(X=x_data_train_norm,
y=t_data_train,
clf=model)
plt.show()
score
# 필요 module import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
df = pd.read_csv('/content/drive/MyDrive/AI스쿨 파일/ML/MNIST/train.csv')
df
# 데이터셋 분리
x_data = df.drop('label',axis=1,inplace=False).values
t_data = df['label'].values
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# 데이터 분리
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
stratify=t_data,
test_size=0.3,
random_state=0)
# tensorflow 구현
keras_model = Sequential()
keras_model.add(Flatten(input_shape=(784,)))
keras_model.add(Dense(units=10,
activation='softmax'))
keras_model.compile(optimizer=Adam(learning_rate=1e-2),
loss='sparse_categorical_crossentropy',
metrics=['acc'])
keras_model.fit(x_data_train_norm,
t_data_train,
epochs=100,
batch_size=100,
verbose=1,
validation_split=0.3)
keras_model.evaluate(x_data_test_norm,
t_data_test)
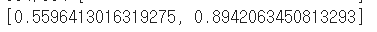
# sklearn 구현
sklearn_model = LogisticRegression()
sklearn_model.fit(x_data_train_norm,
t_data_train)
accuracy_score(t_data_test,
sklearn_model.predict(x_data_test_norm))
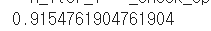
svm_model = SVC()
svm_model.fit(x_data_train_norm,
t_data_train)
accuracy_score(t_data_test,svm_model.predict(x_data_test_norm))
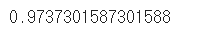
# Decision Tree 구현
model = DecisionTreeClassifier()
model.fit(x_data_train_norm,
t_data_train)
accuracy_score(t_data_test, model.predict(x_data_test_norm))
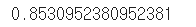
# KNN 이용한 구현
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier(n_neighbors=5)
knn_model.fit(x_data_train_norm,
t_data_train)
accuracy_score(t_data_test, knn_model.predict(x_data_test_norm))