13일차
- 오늘부터 딥러닝 부분에 대해서 다룰 예정
Deep Learning(딥러닝)
- 1개의 logistic regression을 나타내는 node가 서로 연결되어 있는 신경망 구조
- 입력층, 1개 이상의 은닉층(hidden layer), 출력층을 구축하고 있다
-> layer로 구성 - 출력층의 오차를 기반으로 layer의 각 node가 가지는 가중치를 학습하는 machine learning 기법
- 몇 개의 은닉층을 사용하는게 좋은지는 문제마다 다르다!
-> 일반적으로 node의 수 보다는 layer의 개수가 중요!
-> 필요 이상의 은닉충 존재 시 overfitting 발생!!
binary classification
- logistic regression을 1개 사용하는 경우
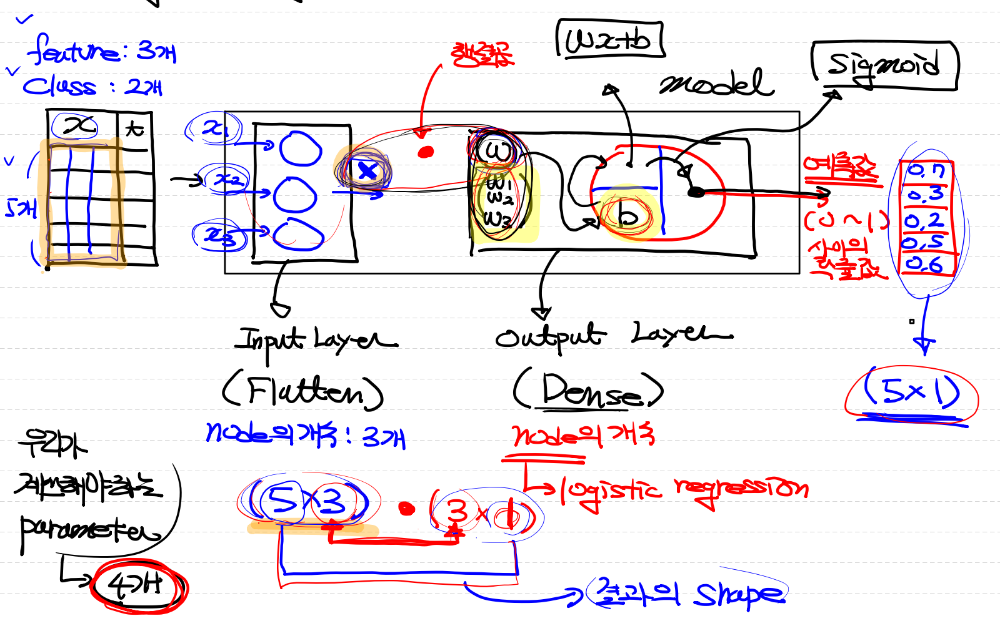
위 그림을 간단하게 표현하면 아래와 같다
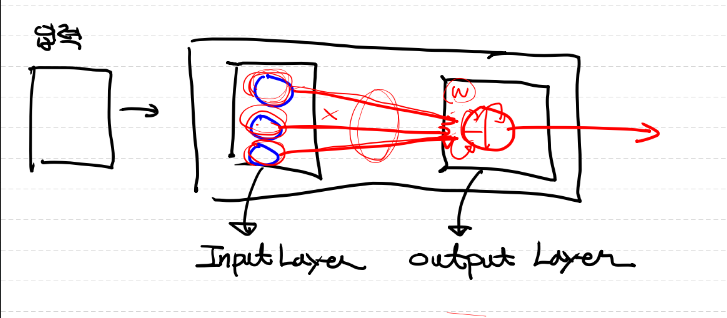
multinomial classification
- logistic regression을 여러 개 사용하는 경우
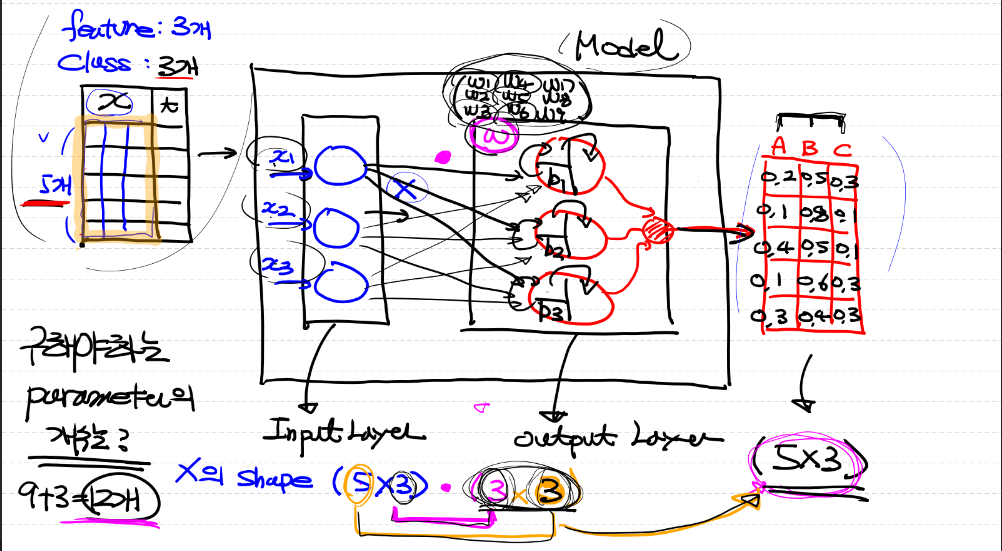
- 합성곱을 사용해서 총 계산해야 하는 parameter의 개수를 구할 수 있다.
DNN(Deep Neural Network)
- 은닉층을 2개 이상 지닌 학습 방법을 의미한다
- 컴퓨터가 스스로 분류 레이블을 생성하고 공간을 왜곡하고 데이터를 구분짓는 과정을 반복하여 최적의 구번선을 도출
- 즉, input에 대해서 ouput까지 Layer를 거치돼, input Layer 다음에 W랑 b가 있어서 Wx+b를 거치게 되고 hidden layer1 에서는 활성화 함수가 존재
- 그 후 다시 Wx + b를 거치고 활성화 함수를 거친 후, output layer가 분류일 경우 마지막에는 softmax를 activation function(활성화 함수)을 활용
- DNN을 활용한 여러 알고리즘 중 RNN과 CNN에 대해서 알아볼 예정
- RNN(LSTM) : 시계열을 다루는 분야(NLP, 자연어 처리)
- CNN : vision쪽(이미지, 동영상) 데이터를 다루는 분야
- 우선, CNN에 대해서 알아보자!
CNN(Convolution Neural Network)
- 합성곱 신경망으로 인간의 시신경 구조를 모방한 기술이다
- 특징 맵(featrue map)을 생성하는 필터까지 학습이 가능해 vision 분야에서의 성능이 우수함
- 이미지의 공간 정보를 유지한 채 학습을 하게하는 모델
Image의 기본
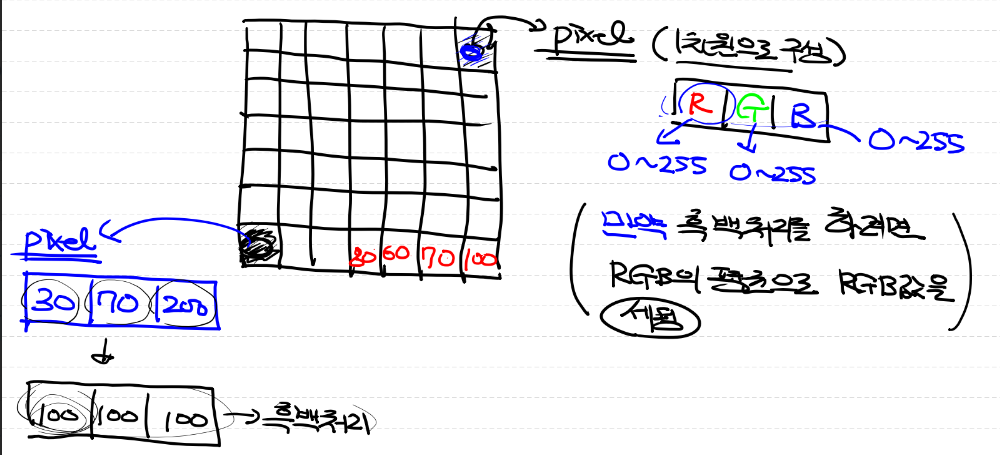
- 이미지를 구상하는 가장 작은 단위는 pixel(픽셀)
- 하나의 픽셀은 기본적으로 3개의 값으로 구성되어 있다
- R,G,B(24 bit)
- 1개의 값이 추가될 수도 있다(투명도, alpha)
- 이미지 좌표의 경우 일반적인 경우와 다르게 (높이, 너비)의 형태이다
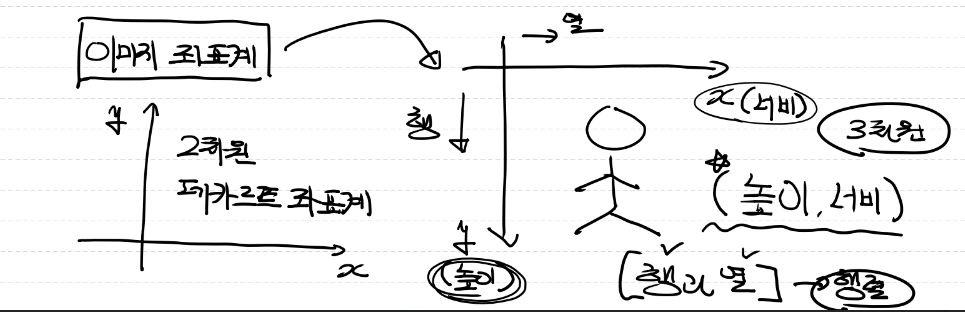
- pillow library를 사용해서 이미지를 pixel data 형태로 쉽게 변환이 가능하다
- 즉, 모든 이미지는 3차원의 ndarray 형태로 구성되어 있다.
이미지 학습의 문제점
- DNN의 경우 입력 데이터가 2차원(1차원 데이터가 여러 개)
- 우리의 이미지 데이터는 데이터 자체가 2차원 or 3차원!
- 입력으로 사용하기 위해 이미지를 1차원으로 변경하면 데이터 유실이 발생한다!!
- pixel로 변형해서 학습하므로 이로 인해서도 문제 발생

-> 이런 문제점을 개선한 것이 바로 CNN!!
CNN의 개념
- 사람이 이미지를 인식하는 방법과 유사하게 학습을 진행하자!
- 이미지의 pixel을 학습하는 대신 해당 이미지의 특징적인 부분 잘라내고
- 특징들을 여러개 만들어 pixel로 변환 후 학습
- 즉, 특성을 추출해서 학습
CNN의 구조
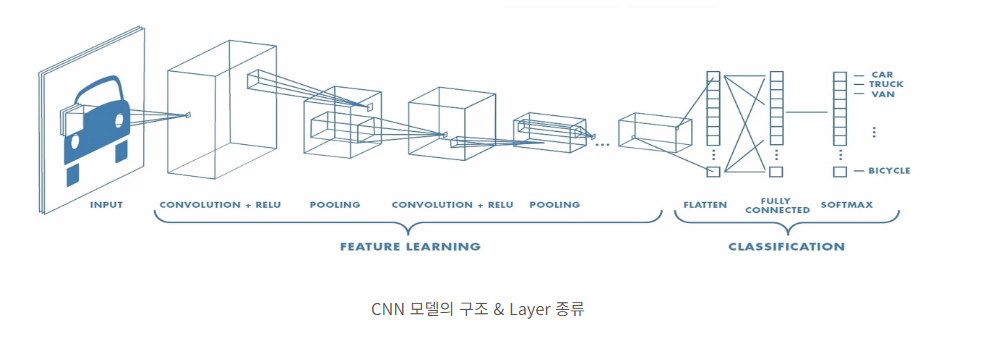
- 크게 특성을 추출하는 feature extraction과 분류기(classifier)로 구성
- Feature Extraction
- 학습할 이미지의 특징을 추출하는 작업
- convolution layer와 pooling layer가 번갈아 나오며 특징을 추출!
- Classifier
- DNN 수행을 통해 예측값을 도출해내는 부분
- loss를 계산하고 optimizer를 이용해서 학습하는 과정은 동일
Convolution(합성곱) 연산
- 하나의 conv layer에는 입력 이미지의 채널 수만큼 필터가 존재
- 각 채널에 할당된 필터를 적용함으로써 합성곱 계층의 출력 이미지 생성
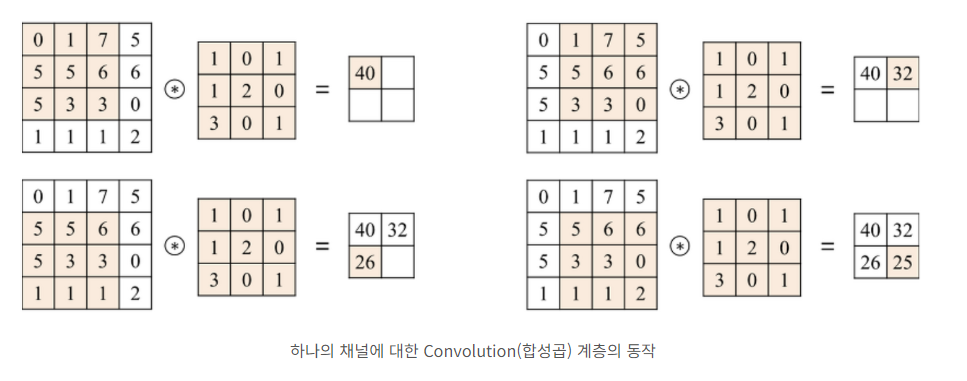
- 위와 같은 과정을 거쳐 feature map이 생성
- 오른쪽 필터와 같은 위치에 있는 것끼리 곱해서 전부 더하면 된다
- filter는 일반적으로 3x3 사용
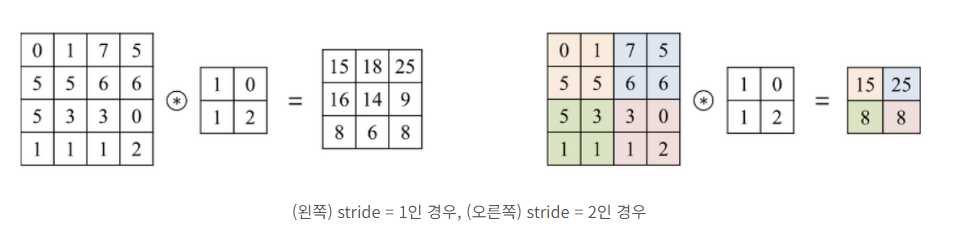
Stride
- convolution 연산 시, 필터가 이동하는 거리를 의미
- 일반적으로 1을 적용
- 아래 그림 동일한 채널에 대해서 stride를 다르게 적용해 feature map을 생성하는 과정이다
Padding
- 위 그림에서 볼 수 있듯이 합성곱 연산을 진행하면 출력 이미지의 크기가 작아지는 현상 발생!
- 합성곱 연산을 진행할 수록 이미지의 크기가 작아지고 가장자리 픽셀들의 정보가 사라지는 문제가 생긴다
- 이를 해결하기 위한 방법이 바로 padding이다
- CNN에서 주로 사용되는 padding 기법은 zero-padding 기법이다
- zero-padding
- 이미지의 가장자리에 0의 값을 가지는 pixel 추가하는 방법
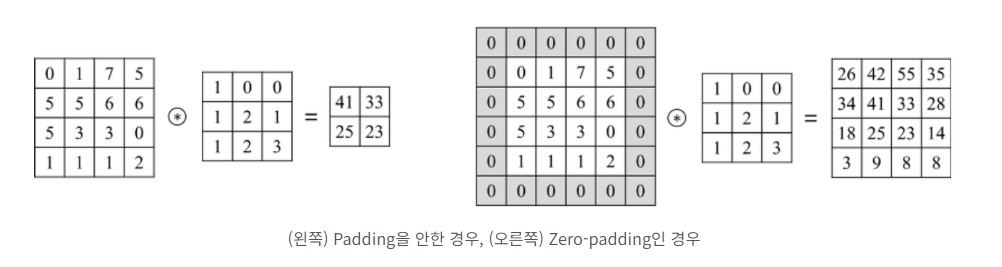
- zero-padding
- 코드 작성 시, padding = 'valid'라는 옵션을 사용하면 padding을 사용하지 않는다는 의미이다
Pooling
- 이미지의 크기도 적당히 줄이며, 특징(feature)를 강조하는 역할을 하는 부분
- 방식으로는 3가지가 존재
- Max Pooling
- Average Pooling
- Min Pooling
- 위 방법 중 CNN에서는 Max Pooling 방식을 사용
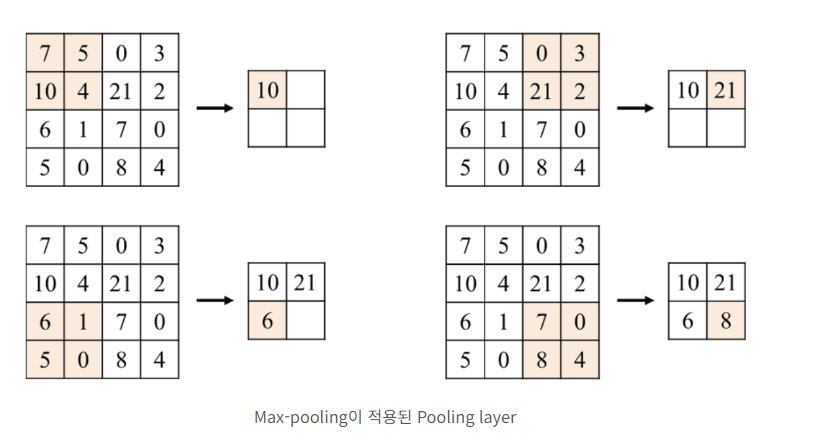
- 위 그림은 max pooling을 그림으로 나타낸 것으로, 쉽게 말해 각 filter 크기의 칸 내부에서 가장 큰 수를 찾는 과정
- pooling을 사용하여 얻을 수 있는 장점은??
- 선택 영역 내부에서 픽셀들의 이동 및 회전 등에 의해 위치가 변형 되더라도 출력값이 동일
- Overfitting(과적합)의 문제를 어느정도 완화 가능
Fully-Connected Layer
- CNN 구조의 마지막 단계로 분류 작업을 위한 단계
- 이미지 특징을 추출하여 무엇을 의미하는지 데이터를 분류하는 작업
- 2가지의 Layer 존재
- Flatten Layer : 데이터 타입을 변형, 입력 데이터의 shape 변경만 수행
- Softmax Layer : Classification(분류) 수행
최종 정리를 하자면,
CNN은 Convolution과 Pooling을 반복하여 사용해 특징(feature)을 찾아내고, 그 특징을 Fully-Connected Layer로 보내 Classification(분류)를 수행하는 것!!
코드 부분
# 이미지를 pixel로 표현해 보아요!
# 이미지를 표현하기 위해 여러 module을 사용할 수 있어요
# 가장 대표적 이미지 library는 matplotlib library
# 또 다른 module로 Pillow도 많이 사용
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('/content/drive/MyDrive/AI스쿨 파일/ML/justice.jpg')
# plt.imshow(img)
# plt.show()
# 이미지 객체를 ndarray로 표현할 거에요!
# 이미지는 pixel의 집합이에요! 각 pixel은 3개의 값으로 구성
# 따라서 모든 이미지는 흑백, 컬러 상관없이 3차원
pixel = np.array(img)
pixel.shape # (426, 640, 3) - 주의할 점!
# 일반적인 좌표와 다르게 높이, 너비, 색상 순
# 즉, 세로, 가로, 색상!!
# 이렇게 쉽게 pixel 데이터를 얻어낼 수 있고
# 여러가지 이미지 처리도 가능합니다 - 이미지 잘라내기, 크기 변경, 회전 등등
# 이미지 일정부분 추출(crop)
img_crop = img.crop((30,150,150,300)) # (30,150)을 시작점, (150,300)을 종료점으로 영역을 자름 의미
# plt.imshow(img_crop)
# plt.show()
# 이미지 크기 조정
img_resize = img.resize((150,150))
# plt.imshow(img_resize)
# plt.show()
# 이미지 회전
img_rot = img.rotate(180)
plt.imshow(img_rot)
plt.show()
- 컬러 이미지를 흑백으로 변환하는 과정
# 컬러 이미지를 흑백으로
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('/content/drive/MyDrive/AI스쿨 파일/ML/fruits.jpg')
color_pixel = np.array(img)
color_pixel.shape # (426, 640, 3)
# imshow()에 픽셀 정보를 넣어줘도 이미지 출력 가능
# plt.imshow(color_pixel)
# plt.show()
# 컬러 -> 흑백 전환
# 각 픽셀의 RGB 값을 구해서 RGB 평균으로 대체
gray_pixel = color_pixel.copy()
for y in range(gray_pixel.shape[0]):
for x in range(gray_pixel.shape[1]):
gray_pixel[y,x] = int(np.mean(gray_pixel[y,x]))
# plt.imshow(gray_pixel)
# plt.show()
# 3차원 흑백 데이터를 2차원으로 변경
gray_pixel_2d = gray_pixel[:,:,0] # [:,:,0] -> 세로, 가로 정보는 필요하므로 전체 다 가져옴
# 0 -> 색상 정보의 첫번째 값 -> gray_pixel은 색상값이 모두 같기 때문에 1개만 가져옴!
plt.imshow(gray_pixel_2d,cmap='gray') # imshow()는 3차원 배열을 입력받음 but,우리는 2차원 배열을 넣으려고 함!
# 따라서 cmap으로 색상을 정해줘야 한다.
plt.show()
