15일차
- 오늘도 역시 CNN에 대해서 진행
Image 학습
- 데이터셋(이미지의 개수)가 많이 필요
- 공간데이터의 유실 문제 발생!
- 기본 machine learning -> DNN -> CNN
- 이미지의 특징을 추출해 그 특징을 학습!
- convolution = 이미지 특징을 추출하기 위한 연산
Dropout
- 학습에 참여하는 node수를 제한하는 방법으로, overfitting을 방지하기 위한 기법 중 하나이다.
- 드롭아웃은 훈련량에 따라 적용할 비율을 정하며, 많은 경우 0.5로 설정합니다. 즉, 훈련할 때 모든 뉴런의 50%가 "끄는" 것처럼 동작.
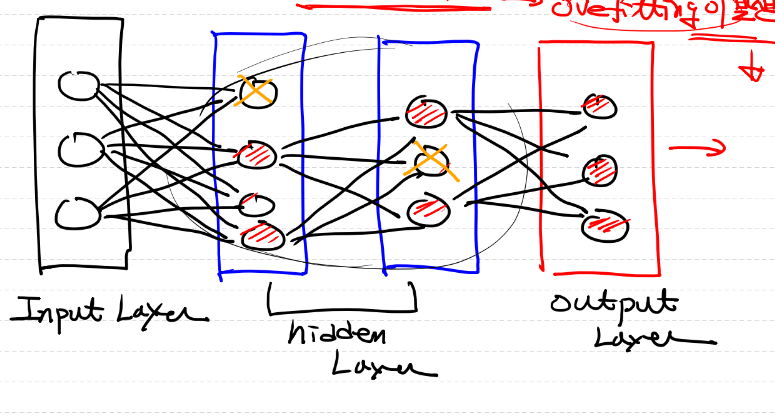
- 장점
- 과적합(overfitting) 방지
- 앙상블 효과
- 학습할 때마다 랜덤하게 선택된 뉴런을 사용하므로, 여러 모델을 합친 효과와 유사하게 동작
- 계산 효율성
- 연산량이 감소하고, 학습 속도가 빨라진다
- 단점
- 추가적인 계산이 필요하기 때문에, 학습 시간이 늘어날 수 있다
- 최적화 알고리즘을 사용하여 극복 가능
- 모델에 적합한 드롭아웃 비율을 찾기 위해 여러 실험을 진행하고 튜닝을 해야할 수도 있다
- 추가적인 계산이 필요하기 때문에, 학습 시간이 늘어날 수 있다
Augumentation(증강)
- 원본 이미지에 약간의 변화를 주어 새로운 이미지를 만들어 내는 기법
-> 이렇게 만들어진 이미지는 학습에 도움이 된다! - Augumentaition의 종류
- 회전(rotation)
- 이미지 이동(상,하,좌,우)
- 확대, 축소
- flip(상하 반전, 좌우 반전) 등이 있다.

- ImageDataGenerator를 사용해서 위 기법들을 사용할 수 있다
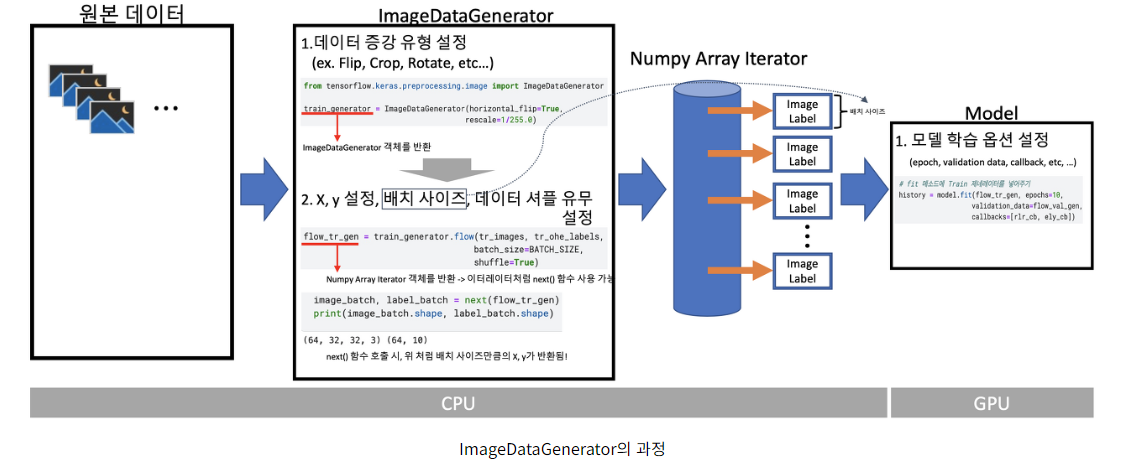
- 위 그림은 ImageDataGenerator의 과정을 나타낸 것이다
- ImageDataGenerator를 사용 시, ImageDataGenerator 객체를 생성한 뒤, batch_size, shuffle 유무 등을 인자로 넣어주어야 한다.
코드 부분
- 위 개념들을 실제 코드에 적용된 것을 보며 어떻게 활용되는지 알아보도록 하자
- 비교를 위해 augumentation 적용 전후 코드 작성
Image Augumentation 적용 전
- 우선, ImageDataGenerator 생성
# 데이터를 가져오기 위해서
# (우리에게 제공된 이미지 파일로부터 pixel데이터를 추출하기위해)
# Keras가 제공하는 ImageDataGenerator를 사용할꺼예요!
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# 학습하기위해서는 train data와 validation data가 필요해요!
# 지금까지는 학습할때 train data 중 일부(30%)를 띄어서 validation에 사용했어요
# validation_split=0.3 <- 이런식의 option을 이용해서 처리했었어요!
# 이렇게 해도 되지만 아예 validation data를 별도로 사용할 수 있어요!
train_dir = '/content/drive/MyDrive/[AI_SCHOOL_9기]/data/cat_dog_small/train'
validation_dir = '/content/drive/MyDrive/[AI_SCHOOL_9기]/data/cat_dog_small/validation'
# ImageDataGenerator 객체를 생성해요!
# pixel값(RGB)은 각각 0~255사이의 값을 가져요!
# 정규화처리를 한 pixel 데이터를 가져오기 위해서 rescale을 사용해요!
train_data_gen = ImageDataGenerator(rescale=1/255)
validation_data_gen = ImageDataGenerator(rescale=1/255)
train_generator = train_data_gen.flow_from_directory(
train_dir, # 어떤폴더에서 이미지를 가져올지 설정
classes=[ 'cats', 'dogs'], # 폴더명을 명시해요!
# cats 폴더에서 가져온 픽셀데이터의 label을 0으로
# dogs 폴더에서 가져온 픽셀데이터의 label을 1로
target_size=(150,150), # 이미지 size를 똑같이 resize
batch_size=20, # 한번에 20개의 이미지를 가져와서 pixel데이터로
# 변환해요. 조심할거는..label에 상관없이 가져와요!
# 멍멍이 10개, 고양이 10개 이렇게 가져오는게
# 아니라.. 둘 합쳐서 20개 가져와요!
class_mode = 'binary' # 이진분류인 경우 bianry
# 다중분류인 경우 categorical
)
validation_generator = validation_data_gen.flow_from_directory(
validation_dir, # 어떤폴더에서 이미지를 가져올지 설정
classes=[ 'cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode = 'binary'
)
# generator를 만들었으니 실제로 한번 동작시켜서 데이터를 잘 추출하는지
# 확인해 보아요!
# x_data는 당연히 이미지의 pixel data
# t_data는 이미지의 label(0(고양이) 혹은 1(멍멍이))
for x_data, t_data in train_generator:
print(f'x_data의 shape : {x_data.shape}') # (20,150,150,3)
print(f't_data의 shape : {t_data.shape}') # (20,)
break;
# 가져온 pixel data가 진짜 이미지의 pixel data인지 확인해보아요!
# pixel데이터를 이용해서 그림을 그려보면 되겠죠!
fig = plt.figure()
axs = [] # subplot들이 저장되는 list
for i in range(20):
axs.append(fig.add_subplot(4,5,i+1))
for x_data, t_data in train_generator:
# (20, 150, 150, 3)
for idx, img_data in enumerate(x_data):
axs[idx].imshow(img_data)
break;
plt.tight_layout()
plt.show()
- 모델 생성
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.optimizers import Adam
model = Sequential()
# CNN을 구현할꺼니까..처음에는 Feature Extraction부분이 나와요!
model.add(Conv2D(filters=32,
kernel_size=(3,3),
strides=(1,1),
activation='relu',
input_shape=(150,150,3)))
# filter의 shape => (3,3,3,32) 필터의 channel은 입력 데이터의 channel과 동일
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
strides=(1,1),
activation='relu'))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
strides=(1,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
strides=(1,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
# model.summary()
# FC Layer(DNN 학습) - input, hidden, output 부분
model.add(Flatten()) # 4차원을 펴준다는 의미
# hidden layer(선택사항)
# 1개만 넣어도 되고 여러개 넣어도 되고 안넣어도 됨!!
model.add(Dense(units=512,
activation='relu'))
# output layer
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
model.summary()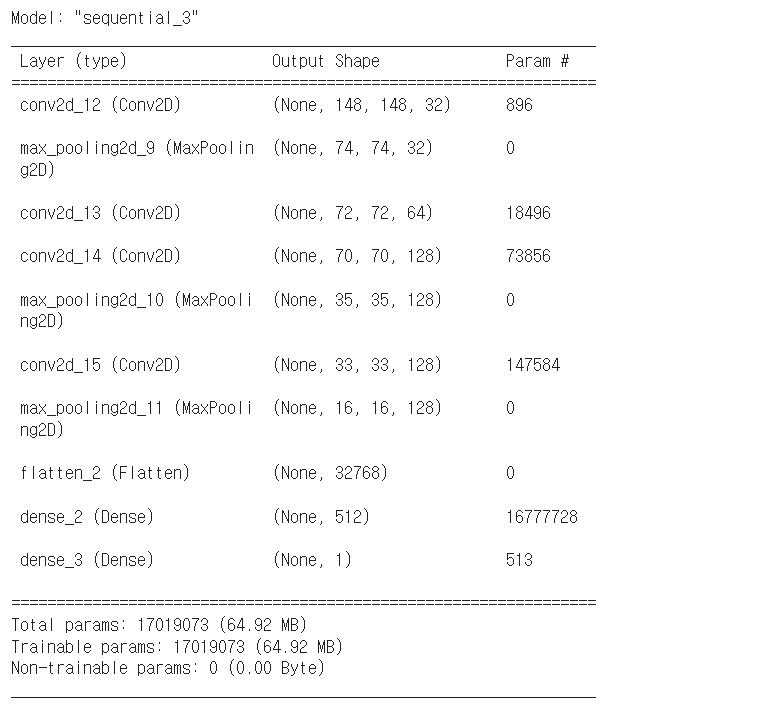
- 모델 학습
# 우선, 조기종료 설정
from tensorflow.keras.callbacks import EarlyStopping
es_cb = EarlyStopping(monitor='val_loss',
patience=5,
restore_best_weights=True)
# 학습 데이터와 val 데이터는 각각 generator 안에 있음
# 학습 데이터의 경우 한번에 20개 불러옴 but 한 epoch당 총 개수인 2000개 학습 필요
# 20*100 = 2000이므로 steps_per_epoch = 100
# validation_steps 역시 위와 동일, val 데이터는 총 1000개
# 따라서 20*50 = 1000이므로 validation_step = 50
model.fit(train_generator,
steps_per_epoch=100, # 한 epoch 당 generator를 몇 번 실행할 것인지
epochs=50,
validation_data = validation_generator,
validation_steps = 50,
callbacks=[es_cb],
verbose=1
)
# Epoch 12/50
# 100/100 [==============================] - 9s 89ms/step - loss: 0.1033 - acc: 0.9660 - val_loss: 0.9144 - val_acc: 0.7080
# 정확도가 70% 정도 -> 사용할 수 없는 모델이라는 의미
# 둘 중 하나 고르는건데도 10개 중 7개만 맞는거면 뭐..
Image Augumentation 적용 후
# Image Augmentation(이미지 증식)
# 데이터를 살짝 변형시켜 데이터를 늘려서 학습을 시키는 것
# 주의점!! 살짝 변형시키는 것이지 새로운 데이터를 만들어내는 것은 아님
# 회전, 이미지 이동, 확대/축소, Flip
from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
datagen = ImageDataGenerator(rescale=1/255,
rotation_range=20, # 회전 각도 범위 설정(0~20 사이 값 랜덤하게 실행됨)
width_shift_range = 0.1, # 0.1 = 10%
height_shift_range=0.1,
shear_range = 0.1,
zoom_range=0.1,
horizontal_flip = True,
vertical_flip=True,
fill_mode='nearest'
)
# width_shift_range = 가로 방향 얼만큼 움직일지(왼쪽 or 오른쪽),
img = image.load_img('/content/drive/MyDrive/AI스쿨 파일/ML/cat_dog_small/train/cats/cat.3.jpg',
target_size=(150,150))
x = image.img_to_array(img)
x.shape
# ImageGenerator를 이용해서 이 파일로부터 증식된 이미지를 추출!
# 기본적으로 ImageDataGenerator는 4차원을 사용
# 우리 이미지도 역시 4차원으로 표현해야!
x = x.reshape((1,) + x.shape)
x.shape
# 직접 그려서 확인
fig = plt.figure()
axs = []
for i in range(20):
axs.append(fig.add_subplot(4,5,i+1))
idx=0
for batch in datagen.flow(x,batch_size=1):
axs[idx].imshow(image.array_to_img(batch[0])) # batch[0]는 픽셀 데이터(변형된 이미지)
idx += 1
if idx%20==0:
break
plt.tight_layout()
plt.show()
- 모델 생성 및 학습(dropout 적용)
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_dir = '/content/drive/MyDrive/AI스쿨 파일/ML/cat_dog_small/train'
validation_dir = '/content/drive/MyDrive/AI스쿨 파일/ML/cat_dog_small/validation'
# ImageDataGenerator 생성
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# validation data는 증식을 사용하면 안되요! (평가용 데이터이기 때문)
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
train_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
# model 생성
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
strides=(1,1),
activation='relu',
input_shape=(150,150,3)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
strides=(1,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
strides=(1,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
strides=(1,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
# 여기까지가 Feature Extraction 부분이에요! 이미지의 특징을 추출하는 부분
# 이렇게 이미지의 특징을 추출한 후 2차원으로 변경해서 학습을 진행
model.add(Flatten()) # 4차원데이터를 2차원으로 변경(이미지 3차원을 1차원으로 변경)
model.add(Dropout(rate=0.5))
# hidden layer
model.add(Dense(units=512,
activation='relu'))
# output layer
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
# overfitting 정도를 확인하기 위해 EarlyStopping은 설정하지 않았어요!
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50,
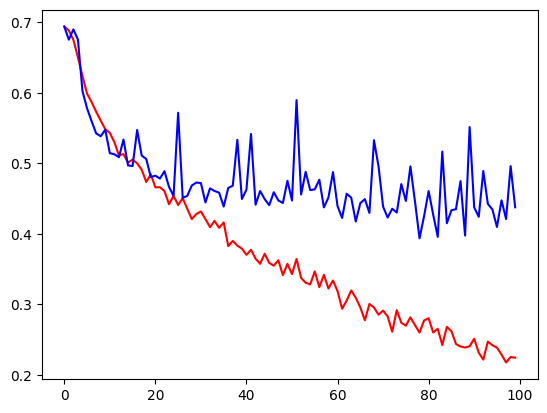
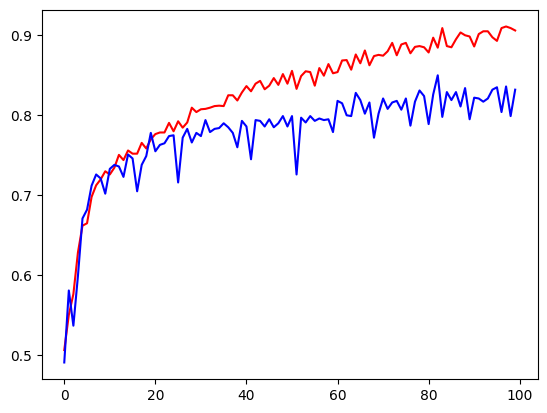
verbose=1)- 시각화
import matplotlib.pyplot as plt
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
train_acc = history.history['acc']
valid_acc = history.history['val_acc']
plt.plot(train_loss, color='r')
plt.plot(valid_loss, color='b')
plt.show()
plt.plot(train_acc, color='r')
plt.plot(valid_acc, color='b')
plt.show()