19일차
전이 학습(Transfer Learing)
- 이미 사전 학습된 모델을 이용해서 문제를 해결하는 방법
- 그럼 왜 사용하는 건가요??
- 학습이 빠르게 수행될 수 있다
- 작은 데이터셋에 대한 overfitting을 방지할 수 있다
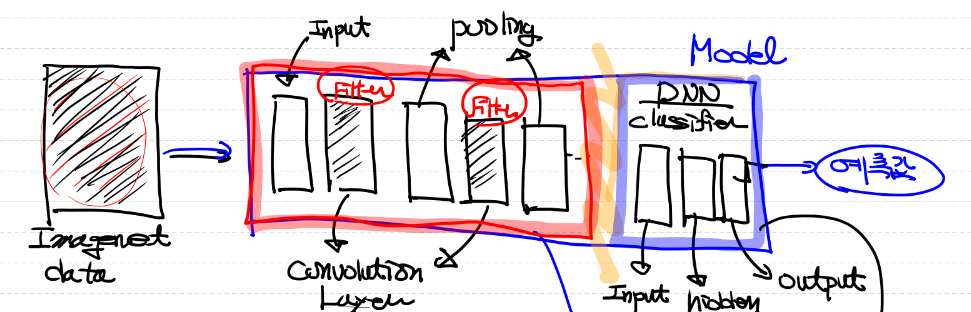
- 위 그림처럼 이미 만들어진 모델을 가져와 마지막 layer만 새로 학습하는 방법
- 또는, convolution layer 부분만 가져와 다른 모델에 붙여 사용하는 방법 등이 존재
- backbone 네트워크
- 다른 task를 해결하는데 사용되는 conv layer로 구성된 네트워크
- ResNet, VGGNet, XCeption, MobileNet 등이 있다
미세 조정(Fine Tuning)
- 사전 학습
- 사전 학습에 사용되는 대표적 Dataset
- ImageNet
- 자동차나 고양이를 포함한 1000개의 클래스, 총 1400만개의 이미지로 구성
- 위 사전 학습된 모델의 일부 가중치를 조절하는 학습 과정을 바로
-> fine tuning(미세 조정)
- 주의!!
- 전이학습은 모델의 효율적 학습을 위한 하나의 방법이며,
- 미세 조정은 전이 학습에서 사용되는 기법 중 하나이다
조건
- 전이 학습이 잘 이루어지기 위한 사전 학습 모델의 조건
- 사전학습에 사용된 데이터와 새로운 데이터가 비슷한 형태를 가지고, 비슷한 특징을 사용할 수 있어야 한다
- 새로운 데이터보다 많은 양의 데이터가 사전 학습되어 있어야 한다
전략
- 이처럼 전이학습이 사용되는 경우는 아래 그림처럼 총 4가지로 나뉜다
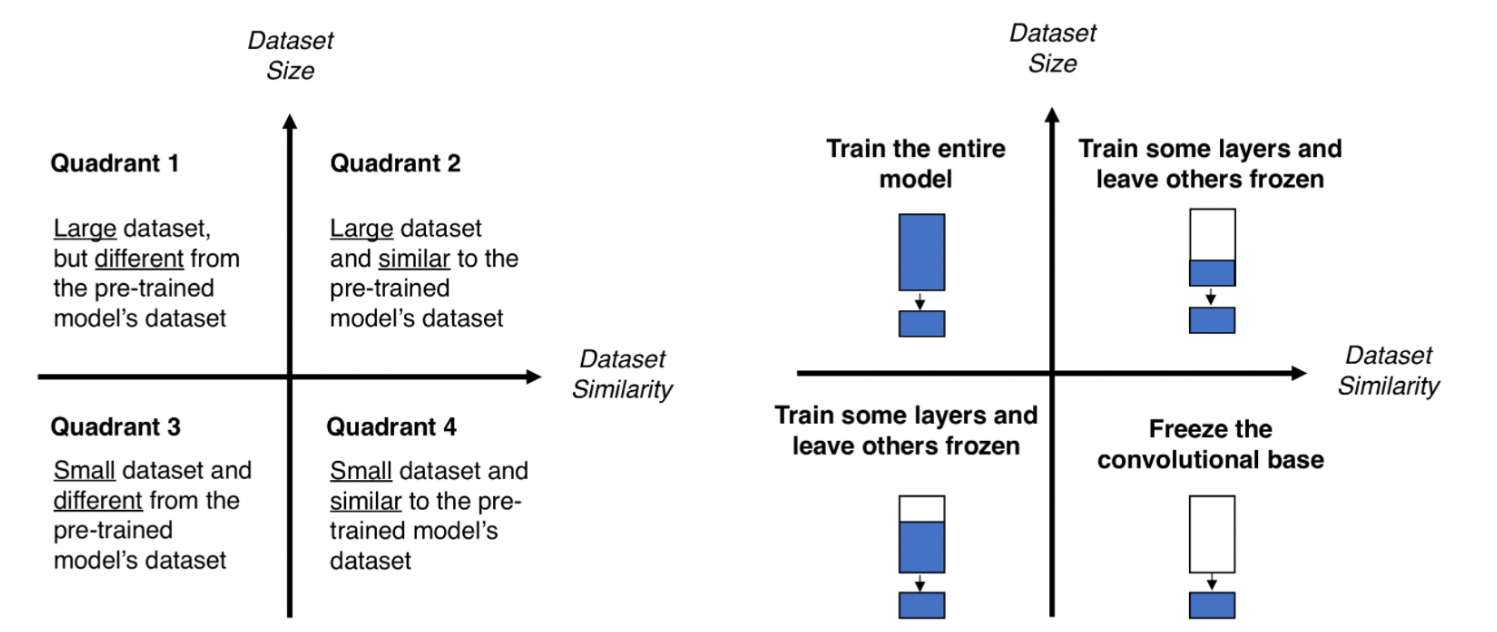
- 1번 케이스
- 데이터의 양은 많지만, 사전학습 모델의 데이터와 다른 경우
-> 모델 전체를 학습
- 2번 케이스
- 데이터의 양도 많고, 사전학습 모델의 데이터와 유사한 경우
-> 일부 layer만 학습하고 나머지는 동결
- 3번 케이스
- 데이터의 양도 적고, 사전학습 모델의 데이터와 다른 경우
-> 일부 layer만 학습하고 나머지는 동결
- 4번 케이스
- 데이터의 양도 적고, 사전학습 모델의 데이터와 유사한 경우
-> convolution layer를 동결시키고 학습
NLP(자연어 처리)
- 방금까지 배운 Vision(이미지 처리)와 함께 Deep Learning의 한 축을 이루고 있는 분야
- RNN, LSTM, GRU 등의 알고리즘 존재
RNN(Recurrent Neural Network)
- sequential data(순서가 존재)를 학습할 때, 사용되는 알고리즘
- RNN에서는 layer(node)를 cell로 표시
- cell은 이전 값을 기억하려고 하는 일정의 메모리 역할을 수행하므로 메모리 셀 이라고도 부른다
- RNN에서는 은닉층의 메모리 셀에서 나온 값이 다음 은닉층의 메모리 셀에 입력된다
-> 은닉 상태
RNN의 구조
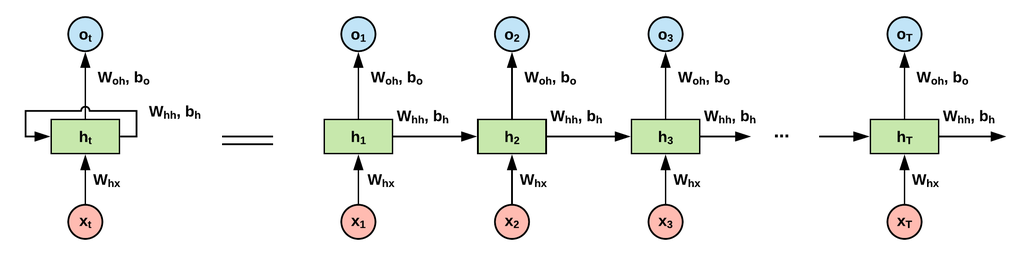
- 위 그림은 RNN의 구조를 나타낸 것으로, 왼쪽 그림을 보면
- 입력 벡터가 은닉층에 들어가는 화살표
- 은닉층으로부터 출력 벡터가 생성되는 화살표
- 은닉층에서 나와 다시 은닉층으로 입력되는 화살표
- 이렇게 구성되어 있다
RNN의 유형
- RNN에는 다양한 유형이 존재
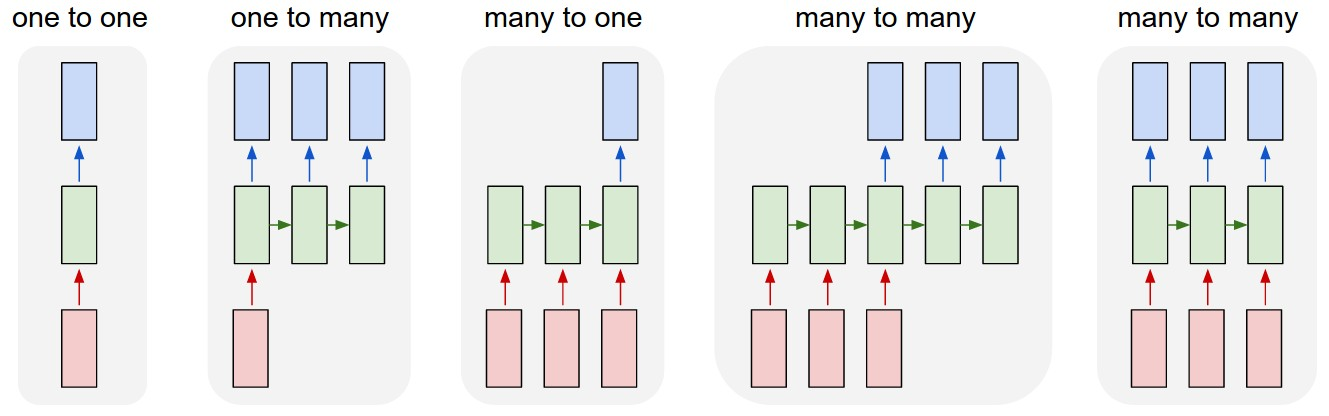
- one to one (일대일)
- one to many
- 1개의 벡터를 입력 받아 sequential 벡터를 반환
- 이미지를 입력받아 이를 설명하는 문장을 만들어내는 이미지 캡셔닝(Image Captioning)에 사용됨
- many to one
- sequential 벡터를 입력 받아 1개의 벡터 반환
- 문장이 긍정인지 부정인지 판단하는 감성 분석(sentiment analysis)에 사용
- many to many
- sequential한 벡터를 받아 모두 입력한 뒤 sequential한 벡터를 출력
- 번역할 문장을 입력받아 번역된 문장을 내놓는 기계 번역(Machine translation)에 사용
- many to many
- sequential 벡터를 입력받는 즉시 sequential 벡터를 출력
- 비디오를 프레임별로 분류(video classification per frame)하는 곳에 사용
코드
전이학습 구현
- pretrained model로는 VGG16을 사용
- 필요 라이브러리 호출
# 전이학습(Transfer Learning)을 구현해 보아요!
# 사용하는 Pretrained Network(Model)은 VGG16을 이용할꺼예요!
# 데이터는 개와 고양이 이진분류 예제를 사용할꺼고
# 이미지의 pixel 데이터 추출할때는 ImageDataGenerator를 이용할꺼예요!
# Augmentation(증식)까지 포함해서 구현해 보아요!
# 필요한 module import
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
train_dir = '/content/drive/MyDrive/AI스쿨 파일/ML/cat_dog_small/train'
validation_dir = '/content/drive/MyDrive/AI스쿨 파일/ML/cat_dog_small/validation'
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# validation data는 평가용이므로 증식 X
validation_datagen = ImageDataGenerator(rescale=1/255)
# ImageDataGenerator 설정
train_generator = train_datagen.flow_from_directory(
train_dir,
classes=['cats', 'dogs'],
target_size=(224,224),
batch_size=20,
class_mode='binary'
)
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
classes=['cats', 'dogs'],
target_size=(224,224),
batch_size=20,
class_mode='binary'
)
# 데이터 준비가 끝났으면 이제 Model을 생성해야 해요!
# 우리는 CNN모델을 처음부터 끝까지 만드는게 아니예요!
# Feature Extraction부분은 VGG16을 이용해서 사용하구요!
# 뒤쪽에 classifier부분만 우리가 직접 구현할꺼예요!
# Pretrained Network
model_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(224,224,3))
model_base.trainable = False # Convolution Layer 동결!
# model_base.summary()
# input_1 (InputLayer) [(None, 224, 224, 3)] 0
# 이 모델은 입력으로 (224,224,3) 형태를 받아요!
# 이미지 1장이 결국 (7, 7, 512) 형태로 변환되요!
# 기본적으로는 classifier가 포함되어 있어요!
# classifier는 사용할 수 없으니 제거해야 해요!
# Total params: 14714688 (56.13 MB) => 전체 파라미터의 수
# Trainable params: 14714688 (56.13 MB) => 학습할때 갱신되는 파라미터의 수
# ==> epoch이 진행될때 자동으로 update되는 파라미터의 수
# ==> 이렇게 두면 안되요.. 학습이 안되도록 처리해야 해요!
# ==> 이렇게 되야 해요! Non-trainable params: 14714688 (56.13 MB)
# 모델을 완성하면 되요!
model = Sequential()
model.add(model_base) # 우리 모델의 앞부분에 pretrained network을 삽입!
# classifier를 구현
model.add(Flatten())
# Hidden Layer
model.add(Dense(units=512,
activation='relu'))
model.add(Dropout(rate=0.5))
# Output Layer
model.add(Dense(units=1,
activation='sigmoid'))
# model.summary()
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=1)

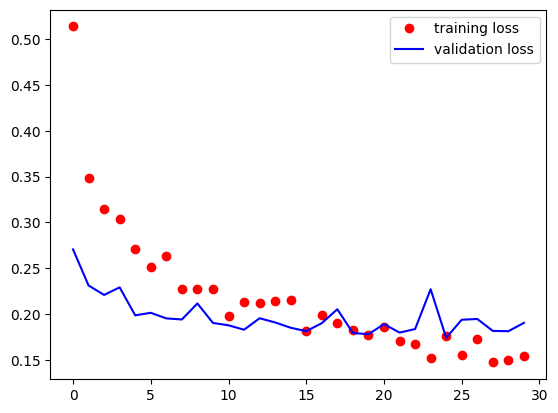
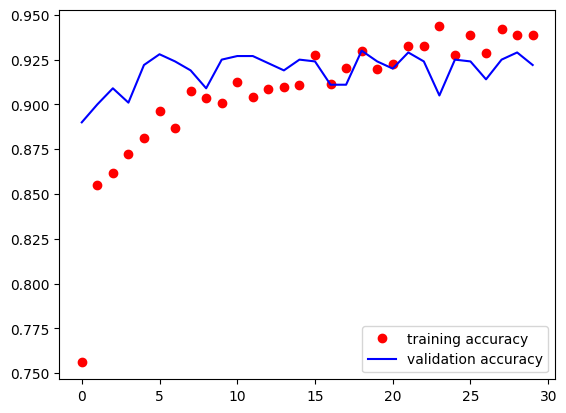
# 학습이 끝난 다음에는 당연히 시각화해서 overfitting이 발생하는지 확인을
# 해야 해요!
# loss와 val_loss, acc와 val_acc를 비교해서 overfitting의 정도를 확인하면 되요!
train_loss = history.history['loss']
valid_loss = history.history['val_loss']
train_acc = history.history['acc']
valid_acc = history.history['val_acc']
plt.plot(train_loss,
'o',
color='r',
label='training loss')
plt.plot(valid_loss,
color='b',
label='validation loss')
plt.legend()
plt.show()
plt.plot(train_acc,
'o',
color='r',
label='training accuracy')
plt.plot(valid_acc,
color='b',
label='validation accuracy')
plt.legend()
plt.show()
model.save('/content/drive/MyDrive/[AI_SCHOOL_9기]/data/cat_dog_small/12.19.CNN_model.h5')
# Fine Tuning
# 이미 위쪽에서 학습이 한번 끝났기 때문에 여기에 추가적으로
# 상위 convolution layer의 동결을 풀고 학습을 한번더 수행하면 되요!
# 먼저 파일로 저장되어 있는 model을 loading해요!
from tensorflow.keras.models import load_model
model = load_model('/content/drive/MyDrive/[AI_SCHOOL_9기]/data/cat_dog_small/12.19.CNN_model.h5')
# model.summary()
# 여기까지가 한번 Transfer Learning을 이용해서 학습이 완료된 상태예요!
# 추가적인 작업이 필요한데.. 일부 layer에 대한 동결을 해제해야 해요!
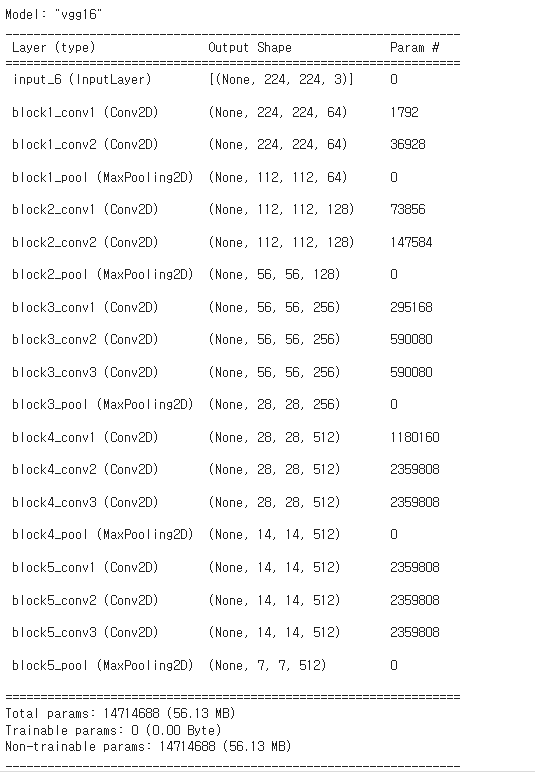
# Pretrained Network
model_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(224,224,3))
model_base.trainable = False # Convolution Layer 동결!
for layer in model_base.layers:
if layer.name in ['block5_conv1', 'block5_conv2', 'block5_conv3']:
layer.trainable = True # 이렇게 하면 해당 layer의 동결이 풀려야 되요!
else:
layer.trainable = False
# 이렇게 모델을 다시 만들고 학습을 한번 더 진행하면 되요!
# => fine tuing! (큰 변화는 아니지만 어느정도 모델의 정확도를 올릴 수 있어요!)
model_base.summary()
RNN
- IMDB Review Dataset을 사용
- 데이터 불러오기
# IMDB Review Data Set을 Loading
# tensorflow keras에는 이미 정수로 변환된 Review 데이터 존재
# 가장 많이 사용하는 단어 500개만 vocabulary로 적재해서 사용
from tensorflow.keras.datasets import imdb
(x_data_train, t_data_train), (x_data_test, t_data_test) = \
imdb.load_data(num_words=500)
# 데이터적재가 다 됬으면 이제 데이터가 어떻게 구성되는지 한번 알아보아요!
print(x_data_train.shape) # x_data_train shape => (25000,)
print(t_data_train.shape) # t_data_train shape => (25000,)
print(x_data_test.shape) # x_data_test shape => (25000,)
print(t_data_test.shape) # t_data_test shape => (25000,)
# 일단 train data : 25,000, test data : 25,000개 있어요!
# t_data_train 내용을 살짝보면
print(t_data_train[:10]) # [1 0 0 1 0 0 1 0 1 0] 0은부정, 1은긍정의 의미
print(x_data_train[0]) # 이 안에 들어있는게 python 리스트예요!
print(type(x_data_train)) # <class 'numpy.ndarray'>
print(type(x_data_train[0])) # <class 'list'>
# 첫번째 review의 길이(첫번째 Review는 몇개의 단어로 구성되어 있나요?)
print(len(x_data_train[0])) # 218
# 두번째 review의 길이(두번째 Review는 몇개의 단어로 구성되어 있나요?)
print(len(x_data_train[1])) # 189
# padding에 대해서 살짝 알아보아요!
# 각 Review의 길이에 대해서 알아보아요!
import numpy as np
import matplotlib.pyplot as plt
lengths = np.array([len(x) for x in x_data_train])
print(lengths[:10])
# [218 189 141 550 147 43 123 562 233 130]
# 모든 Review의 평균길이와 중간값을 출력해보아요!
print(np.mean(lengths)) # 238.71364
print(np.median(lengths)) # 178.0
plt.hist(lengths)
plt.show()
# 평균과 중위값과 히스토그램을 살펴본 결과
# 대부분의 review는 길이가 300 token미만인걸로 파악되요!
# 실제로는 100 token미만인 경우가 아마 대다수일꺼예요!
# 그래서 우리는 모든 Review의 길이를 100에 맞출꺼예요!
# 첫번째 경우는 100보다 리뷰길이가 긴 리뷰는 리뷰가 짤려요!
# 어디를 짜르나요? 앞쪽 데이터를 짤라요!
# 두번째 경우는 100보다 리뷰길이가 짧은 리뷰는 리뷰를 채워줘야해요! => padding
# 패딩을 당연히 앞쪽에 붙여야 겠죠.
# 이 작업을 위해서 keras가 우리에게 함수를 하나 제공해 줘요!
from tensorflow.keras.preprocessing.sequence import pad_sequences
x_data_train_seq = pad_sequences(x_data_train, maxlen=100)
print(type(x_data_train_seq)) # <class 'numpy.ndarray'>
print(x_data_train_seq.shape) # (25000, 100)
# 25,000개의 review. 각 review는 100개의 token으로 재단되었어요!

