
6일차
- 오늘은 Logistic Regression에 대한 실습을 진행할 예정
- Wisconsin Breast Cancer 데이터를 이용
- Titanic 데이터(kaggle에 제출해서 모델 정확도 평가까지)
- 위 데이터들 이외, iris(붓꽃), 보스턴 집값 등 대표적인 머신러닝 예제 데이터
Wisconsin Breast Cancer
- module 호출 및 데이터 전처리
# Logistic Regression 구현
# Wisconsin Breast Cancer Data
# 필요한 module import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
# Raw Data Loading
cancer = load_breast_cancer()
# x_data(feature), t_data(0, 1), 데이터의 설명, .....
# x_data => cancer.data
# t_data => cancer.target
print(cancer.data.shape, cancer.target.shape)
# (569, 30) => x_data는 총 569개의 행으로 구성, 컬럼(feature)은 30개
# (569,) => t_data 역시 총 569개 있어요. 0과 1로 구성되어 있어요!
print(np.unique(cancer.target, return_counts=True))
# (array([0, 1]), array([212, 357]))
# 0.37, 0.63
# 0은 악성종양(나쁜거), 1은 양성종양(괜찮은거)
# 약간의 데이터 불균형이 존재.(imbalanced data)
# 데이터셋 저장
x_data = cancer.data
t_data = cancer.target
# boxplot을 이용해서 이상치와 데이터 분포를 간단하게 확인!
# plt.boxplot(x_data)
# plt.show()
# 데이터 정규화가 필요해요!
# 원래 정규화는 당연히 이상치를 제거하고 진행하는게 맞아요!
# 실제적인 이상치는 존재하지 않는다고 가정하고 진행!
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# 데이터를 분리해야 해요! 학습용과 평가용으로 분리
# train data와 test data로 분리(데이터를 섞어서 분리)
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
stratify=t_data, # 데이터의 비율에 맞춰서 나누라는 의미, 여기서는 t_data
test_size=0.2, # default값은 0.25
random_state=3)
# 섞어서 분리했기 때문에 데이터의 편향이 없을거라 생각되는데
# 확인은 해야 겠죠.
np.unique(t_data_test, return_counts=True )
# (array([0, 1]), array([42, 75])) # 35% , 65%- sklearn 구현
# sklearn model 구현
sklearn_model = linear_model.LogisticRegression()
# 학습하기 전에 cross validation을 한번 수행해 볼꺼예요!
# train data를 가지고 수행해요!
score = cross_val_score(sklearn_model,
x_data_train_norm,
t_data_train,
cv=5)
print(score)
# [0.97802198 0.94505495 0.95604396 0.98901099 0.94505495]
print(f'sklearn의 평균 validation accuracy : {np.mean(score)}')
# 0.9626373626373625
# 학습진행
sklearn_model.fit(x_data_train_norm,
t_data_train)
# 모델최종평가
test_score = sklearn_model.score(x_data_test_norm,
t_data_test)
print(f'모델의 최종 score : {test_score}') # 0.9649-
sklearn 구현 결과

-
tensorflow 구현
# Tensorflow 구현
keras_model = Sequential()
keras_model.add(Flatten(input_shape=(30,)))
keras_model.add(Dense(units=1,
activation='sigmoid'))
# 학습할 때 매 epoch마다 validation을 수행하고
# validation의 평가 기준은 accuracy를 사용하겠어요!
keras_model.compile(optimizer=Adam(learning_rate=1e-1),
loss='binary_crossentropy',
metrics=['acc'])
keras_model.fit(x_data_train_norm,
t_data_train,
epochs=300, # 학습 횟수
verbose=1,
validation_split=0.2) # 매 epoch마다 20%를 검증데이터로 사용 - tensorflow 구현 결과

# training data로 학습한 후
# training data로 평가 vs. validation data로 평가
# loss : training data로 학습한 후 training data를 이용해서 계산한 loss
# val_loss : validation data로 계산한 loss- tensorflow 평가
# 학습이 다 끝났어요!
# Evaluation(평가)
result = keras_model.evaluate(x_data_test_norm,
t_data_test)
print(result)
Titanic.csv from Kaggle
- Kaggle 사이트에서 데이터를 받아 모델 학습 후 자체 평가(validation)진행
- 모델을 이용해 예측값을 추출(test.csv)
- 예측된 결과를 Kaggle에 업로드해서 우리 모델의 성능 검증
- 특이점 : train, test 데이터가 미리 분리 되어있다.
- 데이터 전처리 코드
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/AI스쿨 파일/train.csv')
df
# 데이터 전처리!(feature engineering)
train = df
# 사용하는 컬럼만 추출, 사용되는 않는/불필요 컬럼은 제거
train.columns
# 필요없는 컬럼은(종속변수에 영향을 주지 않거나 의미상 중복 컬럼)
train.drop(['PassengerId','Ticket', 'Name', 'Fare', 'Cabin'],axis=1,inplace=True)
df
# 성별 처리(male:0, female:1)
# map함수 이용하면 쉽게 값 대체 가능
gender_mapping = {'male':0,
'female':1}
train['Sex'] = train['Sex'].map(gender_mapping)
df
train['Family'] = train['SibSp'] + train['Parch']
df
train.drop(['SibSp','Parch'],axis=1,inplace=True)
# df.info()
# Embarked의 결측치를 처리해 보아요!
train['Embarked'] = train['Embarked'].fillna('Q')
# Embarked 처리(숫자)
Embarked_mapping = {'S':0,
'C':1,
'Q':2}
train['Embarked'] = train['Embarked'].map(Embarked_mapping)
df
# 나이를 처리해야 해요! 나이에는 결측치가 많아요!
# 전체 평균 나이로 대체
train['Age'] = train['Age'].fillna(train['Age'].mean())
df
# 나이에 대해서는 Binning 처리를 해요!
train.loc[train['Age'] < 8, 'Age'] = 0
train.loc[(train['Age'] >= 8) &(train['Age'] < 20), 'Age'] = 1
train.loc[(train['Age'] >= 20) & (train['Age'] < 65), 'Age'] = 2
train.loc[train['Age'] >= 65, 'Age'] = 3
df
x_data = train.drop('Survived',axis=1,inplace=False).values
t_data = train['Survived'].values.reshape(-1,1)
# 정규화!
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)-
위 전처리 과정에서 train_test_split 하지 않는 이유!
-> kaggle에서 제공한 test 데이터를 이용한 예측 결과값을 파일로 만들어서 kaggle에 제출하는 것이기 때문에 test data가 필요 없어요! -
Tensorflow Keras 구현
# keras model을 만들어 보아요!
keras_model = Sequential()
keras_model.add(Flatten(input_shape=(5,)))
keras_model.add(Dense(units=1,
activation='sigmoid'))
keras_model.compile(optimizer=Adam(learning_rate = 1e-2),
loss='binary_crossentropy',
metrics=['acc']) # validation 작업을 위해 추가한 코드
# 학습하기
keras_model.fit(x_data_norm,
t_data,
epochs=300,
verbose=1,
validation_split=0.2)
# loss: 0.4536 - acc: 0.8006 - val_loss: 0.3918 - val_acc: 0.8324
# loss, acc는 학습 데이터를 가지고 한거라 중요하지 않음!
# 중요한건, validation data를 가지고 나온 val_loss, val_acc!!- Kaggle 제출용 파일 생성
# 학습이 끝났으니, 제출파일을 생성해야 해요!
# 모델이 만들어 졌으니 test 데이터로 예측된 결과를 csv 파일로
# 만들어서 kaggle에 제출하고 그 결과를 확인해 보아요!
test = pd.read_csv('/content/drive/MyDrive/AI스쿨 파일/test.csv')
submission = pd.read_csv('/content/drive/MyDrive/AI스쿨 파일/gender_submission.csv')
# test 데이터 전처리
test.drop(['PassengerId','Ticket', 'Name', 'Fare', 'Cabin'],axis=1,inplace=True)
# 성별 처리(male:0, female:1)
# map함수 이용하면 쉽게 값 대체 가능
gender_mapping = {'male':0,
'female':1}
test['Sex'] = test['Sex'].map(gender_mapping)
test['Family'] = test['SibSp'] + test['Parch']
test.drop(['SibSp','Parch'],axis=1,inplace=True)
# df.info()
# Embarked의 결측치를 처리해 보아요!
test['Embarked'] = test['Embarked'].fillna('Q')
# Embarked 처리(숫자)
Embarked_mapping = {'S':0,
'C':1,
'Q':2}
test['Embarked'] = test['Embarked'].map(Embarked_mapping)
df
# 나이를 처리해야 해요! 나이에는 결측치가 많아요!
# 전체 평균 나이로 대체
test['Age'] = test['Age'].fillna(test['Age'].mean())
df
# 나이에 대해서는 Binning 처리를 해요!
test.loc[test['Age'] < 8, 'Age'] = 0
test.loc[(test['Age'] >= 8) &(test['Age'] < 20), 'Age'] = 1
test.loc[(test['Age'] >= 20) & (test['Age'] < 65), 'Age'] = 2
test.loc[test['Age'] >= 65, 'Age'] = 3
test
x_data_test_norm = scaler.transform(test.values)
predict = keras_model.predict(x_data_test_norm)
predict
submission['Survived'] = predict
submission['Survived'] = np.where((submission['Survived']>=0.5),1,0)
submission
# csv로 저장
submission.to_csv('./sub.csv',index=False) # index=False로 해야 0,1,2,같은 인덱스 저장 안됨- 제출 후, 결과
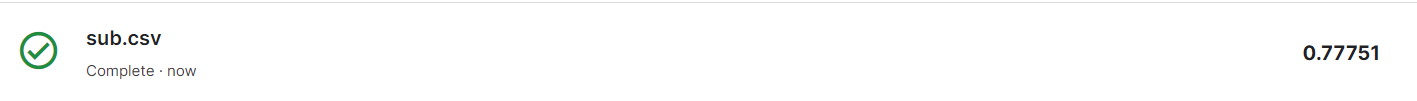
6일차 회고
- 오늘은 로지스틱 회귀에 대해 집중연습을 한 날
- 이전처럼 코랩 내에서만 결과를 확인할 줄 알았는데
- Kaggle에 결과를 제출해서 정확도를 검증받는 방법이 색달랐다.
- 평소, Kaggle에서 데이터를 받기만 했었는데 앞으로는 이런 부분도 찾아서 종종 연습삼아 해봐야겠다.
