맛 보기
- 데이터 분석 19일차 포스팅에 적혀있는대로 자연어 처리 맛보기 부분을 여기에 정리하도록 하겠다
형태소 토큰화
- 형태소에 대해 간단히 이야기 하자면
- 크게 자립/의존 형태소로 나뉜다
- 자립 : 명사, 대명사, 수사, 관형사, 부사, 감탄사 등
- 의존 : 접사, 조사 등
konlpy
- 한국어 텍스트 분석을 위해 만들어진 라이브러리
- 파이썬 프로그래밍 언어로 쓰일 수 있도록 만들어졌다는 특징 존재
- pip install konlpy를 통해 설치 가능
코드
- 형태소 분석
from konlpy.tag import Okt
okt = Okt()
token = okt.morphs('꿈의 거처') # morphs - 형태소 분석
token- morphs() : 형태소를 분석해주는 기능

- 형태소 분석 + 품사 정보
from konlpy.tag import Okt
okt = Okt()
token = okt.pos('달이 참 예쁘다고') # pos - 품사의 정보 추가해줌
print(token)
token = okt.pos('달이 참 예쁘다고',join=True)
print(token)-pos() : 품사 정보를 추가해주는 기능

3. 문장의 한 구절만 출력하기
from konlpy.tag import Okt
okt = Okt()
sentence = okt.phrases('달이 참 예쁘다고') # phrases - 한 구절 출력
sentence- phrases() : 한 구절을 출력해주는 기능

- 문장 입력받아 형태소 & 품사 정보 출력
from konlpy.tag import Okt
okt = Okt()
text = input()
sentence_tag = okt.pos(text)
print(sentence_tag)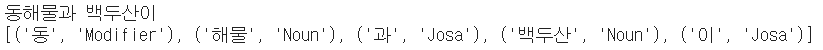
5. 문장을 입력받아 명사와 형용사의 빈도를 계산하여 가장 빈도가 높은 단어들을 찾기
import collections # 동일한 값이 몇개인지 표현해주는 모듈
text = '서기가 영원해도 난 마지막 나야 난 나라는 시대의 처음과 끝이야 난 나라는 인류의 기원과 종말이야 넌 나라는 마음의 유일한 무덤이야 넌 나라는 시계의 마지막 시침이야 난 나라는 우주의 빅뱅과 블랙홀이야 난 나라는 신화의 실체와 허구야 난 너의 이름을 닮은 집을 지을 거야'
sentece_tag=okt.pos(text)
adj_list=[]
for word,tag in sentece_tag:
if tag in ['Noun','Adjective']: # 품사 중에서 명사, 형용사인 것만 추출하기
adj_list.append(word)
counts=collections.Counter(adj_list) # 개수 세어줌
tag=counts.most_common(10) # 가장 많이 나온 순서대로 n개
print(tag)- collections.Counter() : 리스트나 문자열 등 이터러블한 객체나 이터러블 객체의 집합을 받아서 값이 같은 것끼리 묶고, 그 갯수가 몇개인지를 키로 받아서 딕셔너리 형태로 리턴해주는 역할
- most_common(n) : 가장 많이 나온 순서대로 n개 반환

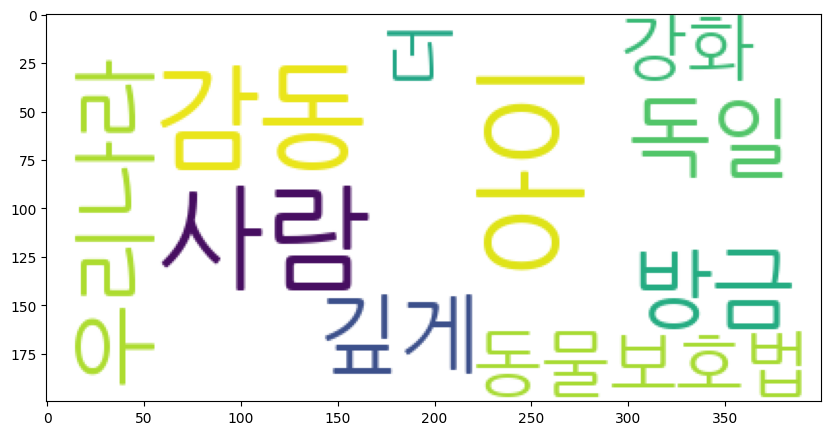
Word Cloud
- tag cloud 혹은 word cloud로 사용되며 데이터에서 얻어진 태그들을 분석해 중요도나 인기도 등을 고려해 시각적으로 늘어놓아 표시한 것
- 중요도(인기도)에 따라 글자의 색상이나 굵기 등의 형태가 달라짐
- Ex)

코드
- word cloud 설치하기
!pip install wordcloud- word cloud로 만들 예시 문장 입력 받아 형태소 분석
import wordcloud
import matplotlib.pyplot as plt
text1 = input()
sentence_tag = okt.pos(text1)
adj_list1 = []
for word, tag in sentence_tag:
if tag in ['Noun', 'Adjective']:
adj_list1.append(word)
print(adj_list1)
3. 형태소 개수 Count
import collections
counts = collections.Counter(adj_list1)
tag = counts.most_common(10)
print(tag)
4. word cloud로 시각화
from wordcloud import WordCloud
wc = WordCloud(font_path='NanumGothic', background_color='white', max_font_size=60)
cloud = wc.generate_from_frequencies(dict(tag)) # 항상 dict형태로 해야함
cloud
plt.figure(figsize=(10,8))
plt.imshow(cloud)- background : 배경색 지정
- max_font_size : 글자 최대 크기 지정
- generate_from_frequencies()
- 단어와 빈도수의 딕셔너리를 받아 word cloud 생성
- () 안에는 반드시 dictionary 형태로 넣어줘야 한다

Word Cloud 2
- 간단한 워드 클라우드를 만드는 법을 알아봤으니
- 이번에는 영화 리뷰 txt 파일을 이용해서 만들어 보자
- 데이터 불러오기
import pandas as pd
import matplotlib.pyplot as plt
from konlpy.tag import Okt
from wordcloud import WordCloud
okt = Okt()
df = pd.read_table('/content/drive/MyDrive/AI스쿨 파일/ratings_train.txt')
df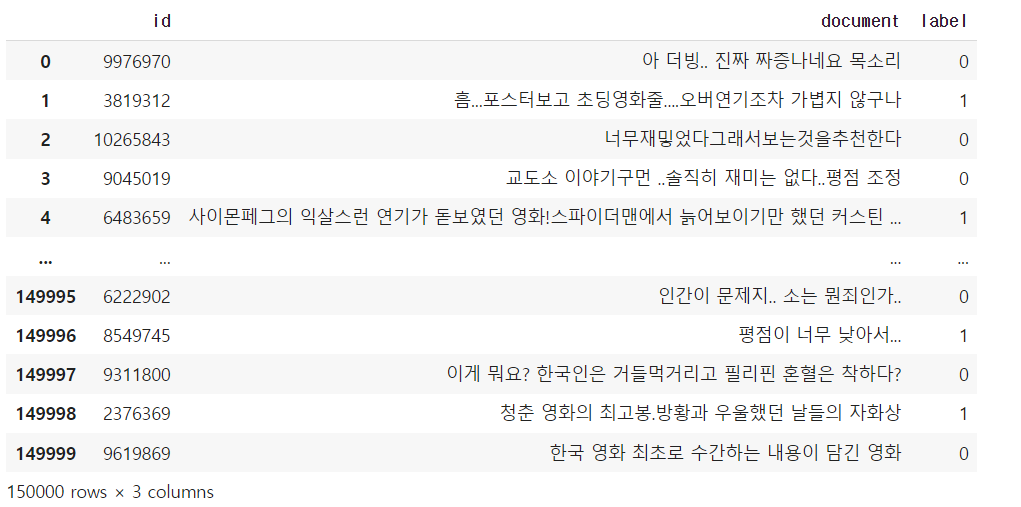
2. 중복, 결측치 확인
# 중복값, 결측치 확인(id 기준)
print(df['id'].nunique())
print(df.isnull().sum())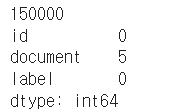
3. 결측치 제거
# 결측치 제거
df = df.dropna(how = 'any') # Null 값이 존재하는 행 제거
print(df.isnull().values.any()) # Null 값이 존재하는지 확인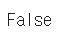
- 결과가 False라는 것은 결측치가 없다는 의미
- 불용어 제거
- 여기서 불용어란 한글의 범주에 속하지 않는 단어들을 의미
- 이번 실습에서는 한글과 공백을 제외한 나머지를 모두 불용어로 보고 제거
df['document'] = df['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")- 불용어 처리는 정규표현식을 사용
- "[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","" : 한글과 공백이 아닌 것을 ""로 대체하라
- ^ 기호는 not을 의미
- 가장 많이 나온 단어 50개 확인
from konlpy.tag import Okt
okt=Okt()
temp_list=[]
for sentence in df['document']:
s_list=okt.pos(sentence)
for word,tag in s_list:
if tag in ['Noun','Adjective']:
temp_list.append(word)
counts=collections.Counter(temp_list)
tag=counts.most_common(50)
tag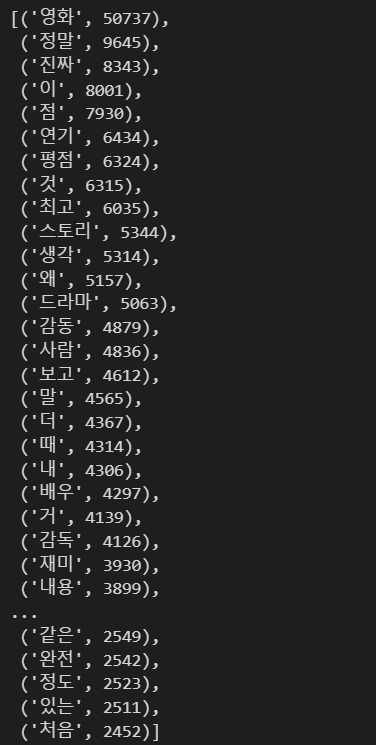
6. word cloud 생성
from wordcloud import WordCloud
#wc=WordCloud(font_path=font_path,background_color='skyblue', max_font_size=60)
wc=WordCloud(font_path='malgun',background_color='skyblue', max_font_size=60)
cloud=wc.generate_from_frequencies(dict(tag))
import matplotlib.pyplot as plt
plt.figure(figsize=(10,8))
plt.imshow(cloud)
Word Cloud 3
- 이번에는 영화 리뷰 데이터 중 rank가 가장 높은 영화의 리뷰 word cloud 표시
- 데이터 읽어오기
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/AI스쿨 파일/comment_rank.csv')
df.head()
2. 중복 & 결측치 확인
# 중복 & 결측치 확인
df['movie'].nunique()
df.isnull().sum()
# 제거
df = df.dropna(how = 'any') # Null 값이 존재하는 행 제거
df.isnull().sum()
3. movie 컬럼을 기준으로 그룹화 한 뒤 rank의 총합 계산
data = df.groupby('movie')['rank'].sum()
data.nlargest(5)
4. 고양이 집사 영화 코멘트 중 가장 많이 쓰인 단어 10개 word cloud
data = df[df.movie=='고양이 집사']
data['comment'] = data['comment'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
temp_list = []
for sentence in data['comment']:
s_list = okt.pos(sentence)
for word, tag in s_list:
if tag in ['Noun', 'Adjective']:
temp_list.append(word)
counts = collections.Counter(temp_list)
tag = counts.most_common(10)
tag
wc = WordCloud(font_path='NanumGothic', background_color='white', max_font_size=70)
cloud = wc.generate_from_frequencies(dict(tag))
plt.figure(figsize=(10,8))
plt.imshow(cloud)