array, tuple
Data Structure (자료구조)
자료구조의 의의
- 사전적인 의미는 자료(data)의 집합으로 각 원소(element)들이 논리적으로 정의된 규칙에 의해 나열되어 자료에 대한 처리를 효율적으로 할 수 있도록 자료를 구분하여 표현한 것을 의미한다.
- 데이터에 편리하게 접근하고 조작하기 위한 데이터 조직/저장방법
- 자료구조는 언어별로 지원하는 양상이 다르다.
- 여러가지 방법이 있으나 상황에 맞게 올바른 자료구조를 선택하는 것이 중요하다. (효율성의 문제) => 전체 개발 시스템에 큰 영향을 끼친다.(실행시간의 단축이나 메모리 절약)
자료구조의 선택 기준
- 자료의 처리 시간
- 자료의 크기
- 자료의 활용 빈도
- 자료의 갱신 정도
- 프로그램의 용이성
자료구조의 분류
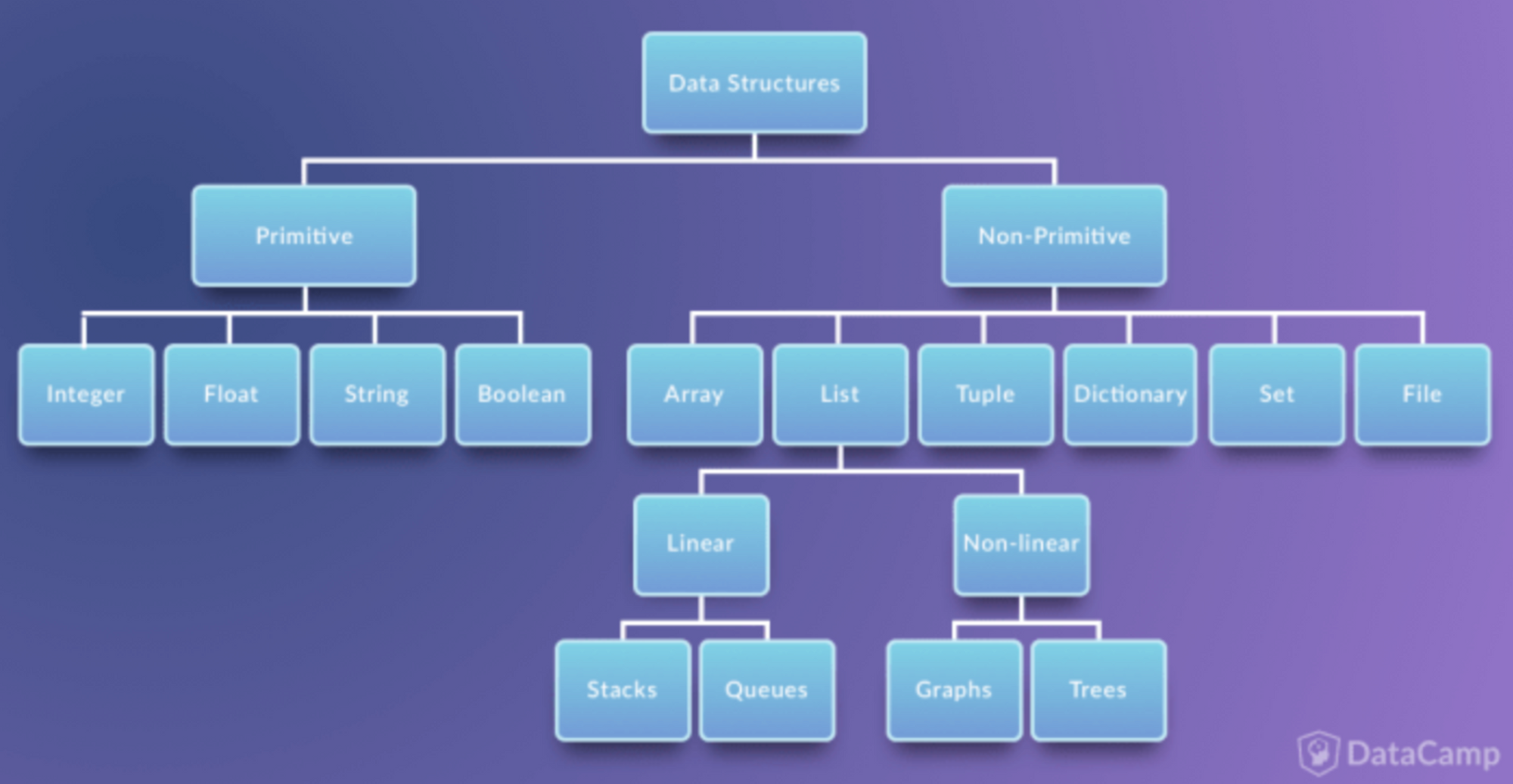
크게 선형과 비선형 자료구조로 나뉜다.
<선형구조 : 저장되는 자료의 전후 관계가 1:1 >
- 배열(array)
- 리스트(list)
- 스택(stack)
- 큐(queue)
<비선형구조 : 데이터 항목 사이의 관계가 1:n 또는 n:m >
- 트리(tree)
- 그래프(graph)
가장 자주 사용되는 2가지의 자료 구조인 list 와 tuple 에 대해 정리해 보겠다.
Array (배열)
Array 의 정의
- Javascript 에서는 Array, Python 에서는 List
- 연관된 데이터를 하나의 변수에 그룹핑 하여 관리하기 위한 방법
- 하나의 변수에 여러 정보를 담을 수 있고, 반복문과 결합하면 많은 정보를 효율적으로 처리할 수 있다.
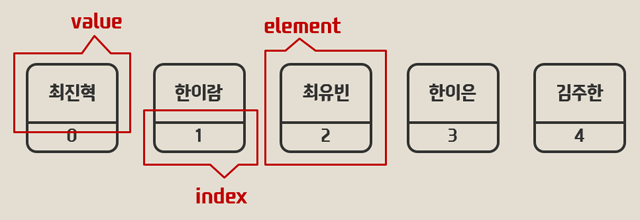
위 자료에서 최진혁이라는 value는 배열에 저장된 값이며 0은 값을 식별하는 인덱스이다. 이 인덱스를 이용해서 value 를 가져올 수 있다.
배열을 프로그래밍적으로 학급으로 표현할 때, 학생의 이름은 배열의 값,학번은 인덱스로 기능한다.
학생들의 이름을 기억하는 것이 어려우므로 번호를 부여하고 이 번호는 학년이 바뀔 때까지 절대 바뀌지 않는다.
전학을 가면 그 번호는 결번이 되고, 전학을 오면 마지막 번호에 추가가 된다.
만약 한이은 학생의 데이터를 가져오고 싶다면 다음과 같이 호출한다.
console.log(student[3]);
또한 여러 정보가 저장되어 있으므로 다수의 정보를 처리하기 위해 반복문을 사용한다면 아래와 같이 작성할 수 있다.
for(i = 0; i < student.length; i++){ console.log(student[i]);
Array 의 특징
- 순차적으로 데이터를 저장한다.
- 순서가 상관 없더라도 서로 연결된 데이터를 저장할 때 사용한다.
- 수정이 가능하다(mutable)
- multi-dementional array(다중차원배열)이 가능하다. 즉 array의 요소가 array 가 될 수 있다.
언제 array를 사용하는가?
- 순차열적인 데이터를 저장할 때(ex.주식 가격:날짜에 따라 값이 다름)
- 다차원 데이터를 다룰 때
- 특정요소를 빠르게 읽어야 할 때 (index)
- 데이터의 사이즈가 급변하지 않을 때
-요소가 자주 삭제되거나 추가되지 않을 때
Array Resizing
-
pre-allocation : 배열이 생성될 때 어느정도의 메모리를 미리 할당
-
따라서 새로 추가되는 요소들이 순차적으로 메모리에 저장
-
처음 할당한 메모리를 초과할 경우 resizing 이 필요(추가 메모리 할당)
-
추가적으로 할당된 메모리 또한 순차적이어야 하므로 메모리 리사이징의 시간이 오래 걸린다. 그 순서는 이러하다.
ex) 100개의 메모리가 다 차서 100개를 추가할 경우
1. 200개 메모리를 새로 생성
2. 기존 100개를 복사
3. 101번 부터 데이터가 순차적으로 추가됨=> 결론적으로 array는 사이즈 예측이 어려운 데이터를 다루기에 적합하지 않다. 사이즈가 급격하게 늘어날 확률이 있는 데이터는 다른 자료구조를 선택해야 한다.
배열의 한계
만약 위의 예에서 한이은 학생이 전학을 갔다고 할 때 데이터를 호출하면 이런 결과가 나온다.
(null 은 값이 없다는 의미)
console.log(student[3]) = null;
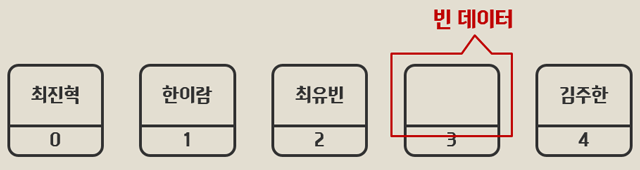
따라서 삭제한 자리를 뒤에 위치한 엘리먼트로 바꾸는 것이 데이터 처리에 좋은데 이러한 자료구조를 list 라 한다.
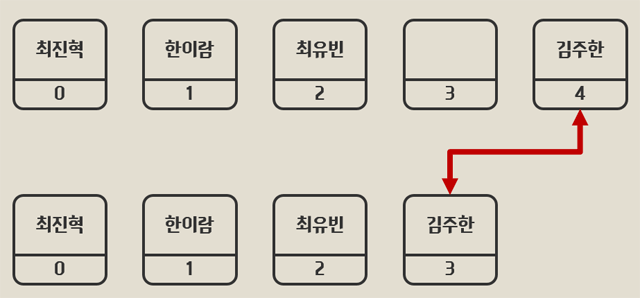
하지만 이 또한 이전의 데이터인 4를 이용해 김주한의 값을 가져로는 프로그램이 있다면 문제가 생기게 된다.
따라서 어떤 구조를 선택할 것인가에 대한 것은 프로그래머의 선택에 달렸다. 인덱스가 중요한 경우는 배열을 사용하고(null을 제외할 경우에는 조건문을 사용) 인덱스가 중요하지 않은 경우에는 리스트를 사용한다.
Tuple
Tuple 의 의의
- list 와 마찬가지로 데이터를 순차적으로 저장할 수 있다.(인덱스 사용 가능)
- list 와 달리 한번 정의되면 수정할 수 없다.(immutable)
=> 원소를 수정,삭제,추가할 수 없다는 점만 빼면 기본적으로 list 와 동일하다. - 2-3개 정도의 적은 수의 소규모 데이터를 저장할 때 많이 사용한다.
- 함수에서 리턴값을 한 개 이상 리턴하고 싶을 때 자주 쓰인다.
- Tuple은 python 에만 있는 언어로서 javascript에서는 제공하지 않는다.
Tuple 의 한계
- 데이터가 무슨 의미인지 명확하지 않다.(데이터의 의미를 문맥을 보고 가정해야 한다.)
