
1. 개발 동기
네이버, 구글 등에서 기사를 확인하기 위해서는 언론사 사이트로 Redirect 돼 기사를 읽는 형태이다.
이때 언론사에서 나오는 광고성 배너들이 눈에 거슬렸다. 언론사에서도 돈은 벌어야하니 입장은 이해한다만.. 광고성 배너들을 제거하여 순수히 기사만 읽을 수 있는 앱을 개발해야겠다는 생각으로 프로젝트를 진행하였다.
2. 개발 목표
언론사의 순수한 기사만을 보여주는 안드로이드 앱 개발
3. 개발 환경
CPU : Intel Core i5-6200U @ 2.30GHz
OS : Windows 10 Home 64 bit
Memory : 4096MB
Language : Java
IDE : Android Studio
Android os : Oreo, Nougat
Library: Jsoup, Translayout, HtmlCleaner
4. 동작 과정
앱의 동작 순서는 아래와 같다.
1. 사용자가 1~2개의 언론사를 선택한다.
2. 선택한 언론사의 정보를 MainActivity로 전달하여 MainActivity에 존재하는 ViewPager에 각각의 언론사에 맞는 Fragment를 생성한다.
3. Jsoup을 이용하여 각각의 언론사를 크롤링한다.
4. 크롤링 된 Html을 ArticleFragment의 RecyclerView의 List item의 제목, 이미지, 기사 내용으로 구성하여 Preview를 CardView 형태로 보여준다.
5. 언론사마다 Html Tag의 의미가 다르기 때문에 각각의 언론사에 맞춰서 구현된 파서를 이용하여 동적으로 View를 생성하여 ShowArticleActivity의 레이아웃을 구성한다.5. 개발 과정
개발을 진행하면서 신경을 썼던 부분은 크게 4가지로 나눠진다.
1. Jsoup 이용
2. AsyncTask 이용
3. Json 이용
4. UI 구성5-1. Jsoup의 이용
Jsoup을 이용하려면 인터넷이 필요하고 안드로이드 정책에 따라 퍼미션에 Internet을 넣어야 한다. Internet 퍼미션을 했음에도 파싱이 안되는 언론사가 종종 있는데 이럴 경우, AndroidManifest.xml 내에 android:usesCleartextTraffic="true" 를 추가하면 대부분 해결이 된다.
Jsoup을 이용하여 파싱을 진행하는데 태그의 id 혹은 class의 이름에 빈 칸이 있는 경우가 존재한다.
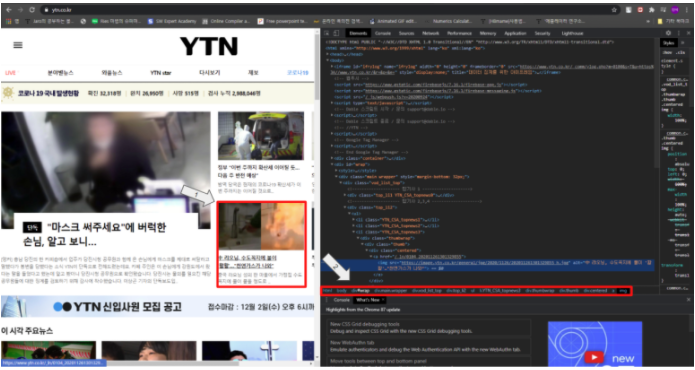 위의 화살표가 가르키는 html 태그 순서로 Jsoup의 크롤링 영역을 지정하면 쉽게 크롤링이 가능하다.
위의 화살표가 가르키는 html 태그 순서로 Jsoup의 크롤링 영역을 지정하면 쉽게 크롤링이 가능하다.
필자는 Jsoup을 요번 프로젝트를 통해 처음 사용해 봤는데 Jsoup의 크롤링 영역을 찾는데 애를 먹었다.
5-2. AsyncTask의 이용
서버 없이 스마트 폰에서 진행이 되므로 안드로이드 정책에 따라 메인 스레드를 사용할 수 없다. 따라서, Thread, Handler, AsyncTask 중 선택하여 크롤링을 진행해야 한다.
필자는 AsyncTask를 이용해서 프로젝트를 진행하였다. 큰 이유는 없고 단순히 AsyncTask를 이용하면서 배워보고 싶었기에 선택하였다.
사용자가 2개의 언론사를 선택할 경우, 병렬적으로 크롤링을 진행하기 위해 AsyncTask의 executeOnExcutor 메소드에 AsyncTask.THREAD_POOL_EXECUTOR 인자 를 이용한다.
5-3. Json의 이용
사용자가 선택한 언론사의 정보에 맞춰 크롤링을 진행해야 하므로 각각의 언론사에 맞춰 Json 파일을 구성한다. 그 후, 사용자가 선택한 언론사에 맞는 Json을 읽어 Jsoup이 크롤링 할 영역을 지정한다.
5-4. UI 구성
UI 구성 부분은 프로젝트의 목표에 영향을 많이 주기 때문에 해당 부분에 많은 시간과 고민을 투자하였다.
결론부터 말하자면 UI를 구성하기 위해 4가지(Brute force, Webview, HtmlSpanner, HtmlCleaner) 시도를 진행하였으며 최종적으로 HtmlCleaner 라이브러리를 이용하여 구성하였다.
1. Brute Force 방법.
크롤링한 Html을 앞에서부터 문자 하나씩 읽어들이면서 태그를 파악하고 해당 태그에 맞게 뷰를 꾸미는 방법이다.
문제점
문자를 읽는 인덱스를 신중히 조절해야 하며 에러가 많이 발생할 수 있기에 다른 방법을 찾아보았다.
2. WebView
기사를 보여 줄 수 있는 방법들 중 가장 쉬운 방법이다.
문제점
핸드폰에 맞게 화면이 구성되지 않았고 화면에 보여지는 반응성이 느려 다른 방법을 택하였다.
3. HtmlSpanner
안드로이드 서드 파티 라이브러리로서 Html를 하나의 긴 SpannerStringBuilder 객체로 만든 후, 태그에 맞게 처리하는 방식이다.
문제점
기사를 구성할 수 있으나 몇몇 언론사(YTN, 중앙일보 등) 기사 내용에 영상 링크를 걸어놓은 기사들이 있어 처리하기에는 어려움이 있어 다른 방법을 택하였다. 뿐만 아니라 Span를 제공하는 Class들의 API가 고 API였기에 사용 자체가 꺼려졌다.
4. HtmlCleaner
해당 라이브러리도 안드로이드 서드 파티 라이브러리이다. HtmlCleaner는 html의 태그들을 TagNode, ContentNode 두 개 클래스로 구성된 트리를 반환해준다.
HtmlCleaner를 이용하여 나온 트리를 이용하여 태그에 맞춰 동적으로 View를 생성하였다.
진행하는 프로젝트에 가장 부합되는 방법이 HtmlCleaner 라이브러리였지 해당 라이브러리가 완벽하다는 것은 아니다.
6. 결과


7. 아쉬운 점
아쉬운 점은 크게 두 가지로 나눠진다.
| 아쉬운 점 | 이유 |
|---|---|
| 에러 처리 | YTN 언론사를 크롤링 할 때, 크롤링 될때와 Error 404가 발생한다. 이렇듯, 통신 에러 처리가 미흡했다는 점이 아쉬움으로 남는다. |
| 미흡한 설계 | 미흡한 설계로 인해 중복되는 코드와 로직들이 발생하였다. |
8. Future Work
1. 서버 구현 후 로직 분할
2. 스포츠, 정치, 예술 등 다양한 분야에 맞는 기사들을 크롤링하여 보여주는 기능 추가
