수어지교는 기존의 영상과 같은 단방향 매체밖에 존재하지 않는 수어 학습 솔루
션을 개선하고자 개발한 '실시간 상호작용'이 가능한 수어 학습용 웹 서비스입니다.
개요
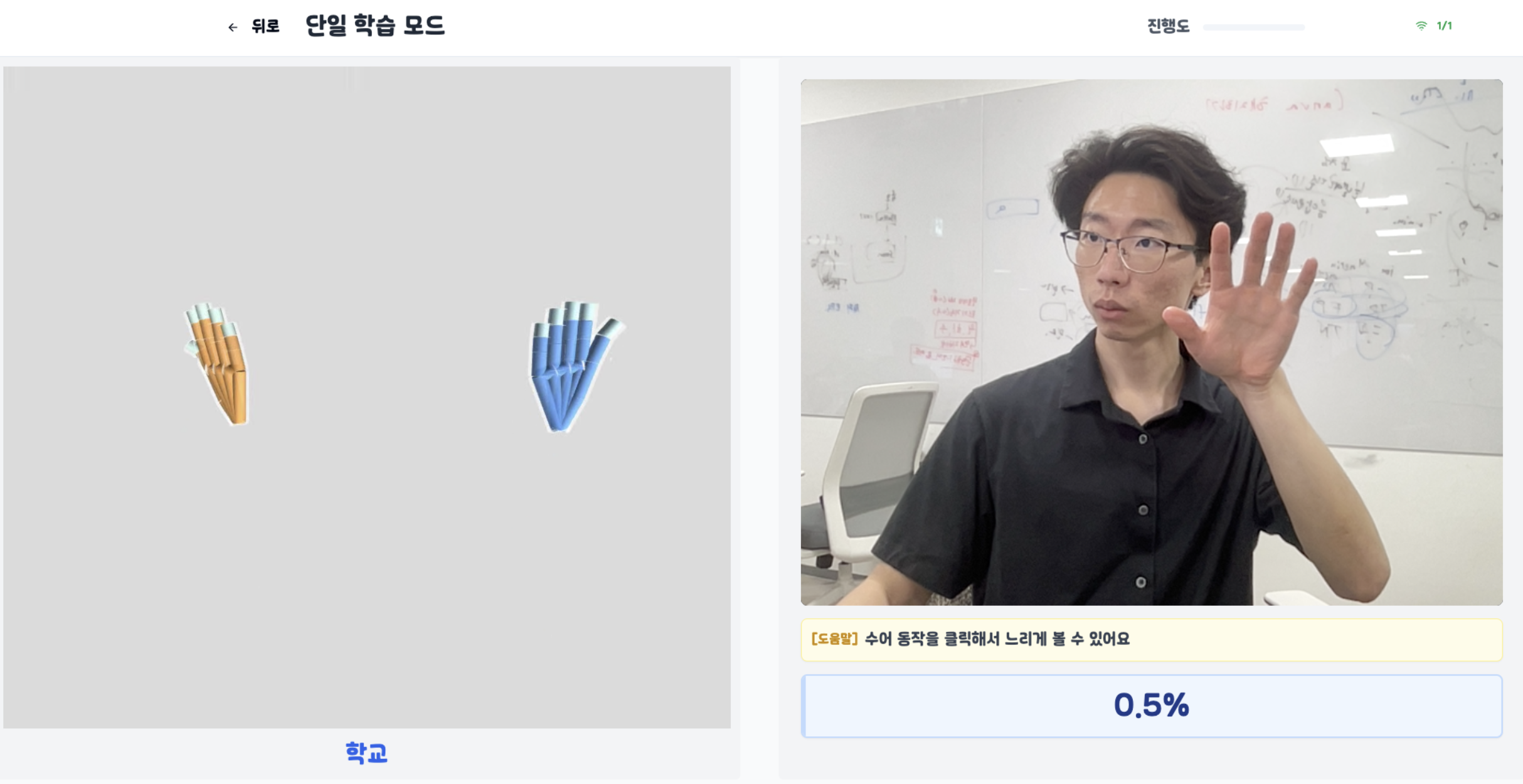
실시간으로 수어 동작에 피드백을 제공하는 방법
수어 학습 서비스를 개발하기로 결정하면서, 팀은 기본적으로 두 가지 접근법을 동시 차용하기로 했습니다.
상호작용의 두 가지 방식: 규칙 vs 딥러닝
규칙 기반 수어 피드백 서비스의 가능성과 한계
첫 번째 방안은 규칙 기반으로 수어 동작에 대한 정답 여부를 알려주는 것입니다. 카메라로 인식한 손의 관절 포인트가 실제 수어 동작의 관절 배치와 동일하면 정답, 아니면 무시하는 식으로 꽤나 ‘수동적인’ 피드백 시스템을 개발할 수 있습니다.
이렇게 규칙 기반으로 서비스를 구현할 때도 ML을 사용하지 않은 것은 아닌데요, 구글의 영상 분류 프레임워크인 미디어파이프 랜드마크를 활용해서 인식된 신체의 관절의 3차원 값을 예측하여 이 3차원 값에 수어 동작의 규칙을 적용할 수 있었습니다.
미디어파이프 랜드마크 예시 자료

여기서 수어 도메인의 특징을 생각해야 하는데요, 자/모음과 같은 ‘지화’는 정지된 손동작으로 표현할 수 있습니다. 반대로 나머지 단어들은 모두 연속된 손동작으로 표현됩니다. 이 말인 즉슨, 규칙 기반의 피드백 시스템은 지화에만 적용될 수 있다는 사실이죠.
물론 연속된 동작도 규칙 기반으로 처리를 할 수는 있겠습니다만, 양 손 각 21개의 관절 포인트와 얼굴과 다른 신체부의의 모든 3차원 좌표 값에 시계열 정보까지 변수의 입력으로 처리해야 하므로 이런 방식으로 수어 학습 서비스를 구현하는 건 비현실적이겠죠. 그래서 딥러닝을 활용했습니다.
딥러닝을 활용한 수어 학습 서비스
딥러닝 모델을 적용하면 위에서 보았던 가장 결정적인 제약 사항(입력값이 너무 많음)을 극복할 수 있습니다. 이제부터 수어 피드백 서비스의 입력을 ‘미디어파이프 랜드마크 시퀸스’로 정의하겠습니다. 미디어파이프 랜드마크는 단순 영상에서 특징점을 추출한 값들이고, 이것이 연속된 동작을 표현하는 시퀸스 형태로 주어지기 때문입니다. (자세한 훈련 및 분류 과정에 대해서는 아래에서 살펴보겠습니다.)
구체적으로 랜드마크 시퀸스의 형상은 아래와 같습니다.
(675, 60)
- 양 손 각 21개의 랜드마크 포인트 x 3개의 x, y, z좌표값
- 얼굴과 팔 등 신체의 대략적인 형상을 표현하는 33개 랜드마크 포인트 * 3개의 좌표값
이를 취합하면 (21 + 21 + 33) * 3 = 225
이때 각 단순 좌표값 외에도 각 지점에 대한 속도와 가속도 값들이 추가되어 총 225 x 3 = 675개의 특징점 데이터가 있습니다. 이때 각 순간의 데이터가 30 FPS 기준으로 2초 길이로 입력으로 주어지기 때문에 60층으로 675개의 데이터가 주어집니다.
‘분류’ 문제와 ‘피드백’의 관계
이 미디어파이프 랜드마크 시퀸스를 통해 사용자의 동작에 피드백을 제공하기 위해서는 몇 가지 방법이 있겠지만, 저희는 가장 직관적인 ‘분류’ 문제로 피드백 서비스를 치환시켰습니다.
어떻게 ‘분류’가 피드백이 될 수 있을까요? 분류 모델의 출력 레이어는 출력 층에서 소프트맥스 레이어를 통해 늘 ‘확률’을 출력합니다. 모델 입장에서는 ‘이 동작은 0.9% 확률로 A클래스, 0.1% 확률로 B 클래스에 속하는군’이라고 분류하지만, 수어를 학습하는 사용자 입장에서는 ‘B클래스를 따라한 내 동작이 0.1%만큼 정확하군’이라는 피드백을 받을 수 있죠.
예상 못한 장점: One Vs Rest
분류 모델을 이렇게 적용한데서 예상 외의 장점도 있었습니다. 모델의 정확도를 올리는 방법 중 하나로 One Vs Rest라는 전략이 있는데요, 이는 이진 분류 모델 여럿을 학습시켜 하나의 다중 분류 모델로 쓰는 전략입니다. 아래처럼 말이죠.
model 1: A vs B, C, D
model 2: B vs A, C, D
model 3: C vs A, B, D
model 4: D vs A, B, C
이를 통해 단 하나의 분류를 굉장히 잘 하는 모델 여럿을 모아서 하나의 다중 분류 모델처럼 쓰는 것이 전통적인 One Vs Rest 방식인데요, 이를 ‘하나의 수어를 학습하는 사용자 입장에서는 다중 분류 모델이 이진 분류 모델처럼 작동한다’는 사실에 착안해봅시다. 아래처럼 말이죠.
model 5: 얼굴 vs 윗집, 남편, 안녕하세요, None(동작 아님)
이 경우에서 저희는 모델을 5가지 라벨을 분류할 수 있는 다중 분류 모델로 학습시켰지만, 사용자가 학습을 하는 순간에는 ‘얼굴’을 잘 분류하는 전문가 모델로 쓸 수 있었습니다. 이를 수학적으로 계산해보겠습니다.
아래와 같이 각 분류 모델의 성능(f1 score)이 측정됐다고 가정해 보겠습니다.
얼굴: 0.7
윗집: 0.8
남편: 0.7
안녕하세요: 0.9
None: 0.9
이때 모델의 전체 f1 score 평균은 0.8입니다. 하지만 이진 분류 모델’처럼’ 활용한다고 생각했을 때 이 분류 모델의 정확도는 얼마일까요? 아래와 같이 이진 분류를 한다고 가정하고 각 라벨 별 정확도를 다시 구해볼 수 있습니다.
얼굴: (0.7 + (0.8 + 0.7 + 0.9 + 0.9)/4)/2 = 0.763
윗집: (0.8 + (0.7 + 0.7 + 0.9 + 0.9)/4)/2 = 0.8
남편: (0.7 + (0.8 + 0.7 + 0.9 + 0.9)/4)/2 = 0.763
안녕하세요: (0.9 + (0.7 + 0.8 + 0.7 + 0.9)/4)/2 = 0.838
None: (0.9 + (0.7 + 0.8 + 0.7 + 0.9)/4)/2 = 0.838
전체 f1 score 평균: (0.763 + 0.8 + 0.763 + 0.839 + 0.839)/5 = 0.801
0.7이었던 ‘얼굴’은 0.063 늘었고, 0.9였던 ‘안녕하세요’는 0.062가 줄었군요. 이처럼 상대적으로 f1 score가 높았던 라벨에 대해서는 하향이 있었지만 낮았던 라벨에 대해서는 상향 조정이 있었고, 분포가 줄어든 모습을 볼 수 있습니다.
상대적으로 분류 정확도가 떨어지는 라벨들에 대해 전체적인 모델의 정확도를 ‘양보’해 줄 수 있기 때문에 전반적인 서비스 관점에서 ‘분류 정확도의 표준 편차가 줄어들었다’고 할 수 있겠습니다. 트레이드 오프 관계가 성립하지만, 서비스 관점에서는 들쭉날쭉한 피드백 정확도보다는 이 편이 훨씬 합리적이라고 할 수 있죠.
이야기가 잠깐 다른 길로 샜지만, 이렇게 분류 모델의 특성을 통해 피드백 서비스를 구현할 수 있음을 충분히 살펴본 거 같습니다.
딥러닝 모델 훈련
훈련 개요
이까지 분류 모델을 피드백 시스템에 활용할 수 있는 방법을 알아보았습니다. 이제 실제로 모델 훈련을 수행한 과정을 보도록 하겠습니다.
이 글에서는 (제가 아는 선에서 최대한) 딥러닝 모델 학습의 심층적인 부분까지 살펴보려고 합니다.
데이터 및 전처리 과정
훈련에 사용한 데이터는 AI hub의 수어 데이터셋입니다. 라벨 데이터가 별도의 csv 파일로 주어지고, 그다지 규칙성 없는 폴더에 무작위로 데이터가 저장돼 있습니다. 총 용량은 700GB, 각 영상의 포맷은 .mov, mp4 등 다양하지만 기본적을 30FPS의 영상입니다.
딥러닝을 직접 수행한 첫 프로젝트여서 데이터를 기본적으로 라벨 이름의 디렉토리 안에 나누어 저장해야 편하다는 사실을 모른 채로, 80개 가량의 데이터를 라벨 별로 모든 디렉토리에서 확인하고 로드하는 과정을 파이썬 스크립트로 자동화했지만, 이는 좋지 않은 선택이었습니다. 왜냐면 딥러닝 프로젝트에서는 캐싱을 적극적으로 사용해야 하고, 원전 데이터에서 특징점을 추출하는 과정은 파라메터 튜닝 과정에 포함되지 않는, 일종의 공통 과정이기에 캐시 로드 시도 실패 시 원천 데이터로부터 특징점 추출이 자연스럽게 이루어지도록 해야 하는데, 파일 경로를 미리 정리해놓지 않으면 이 과정이 지나치게 복잡해집니다.
학습 스크립트에서는 Early Stopping을 적용했고, 모델의 파라메터가 데이터보다 많은 축이었기에 학습 에폭은 그렇게 길지 않았습니다(30에폭 정도). 그래서 대부분의 시간은 전처리 과정이 차지했는데요, 이 프로젝트에서 전처리 과정은 아래와 같습니다.
우선 미디어파이프 랜드마크 시퀸스를 영상에서 추출합니다. cv2 라이브러리를 사용하여 RGB 채널값의 영상으로부터 holistic.process 함수를 사용하여 미디어파이프 랜드마크 값을 추출하고 그 결과에서 'pose', 'left_hand', 'right_hand'만을 선택하여 최종 결과에 추가합니다.
def extract_landmarks_with_holistic(video_path, holistic):
"""전달받은 MediaPipe 객체를 사용하여 랜드마크를 추출합니다."""
try:
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"⚠️ 비디오 파일을 열 수 없음: {video_path}")
return None
# 비디오 정보 확인
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fps = cap.get(cv2.CAP_PROP_FPS)
print(f" 📊 비디오 정보: {total_frames}프레임, {fps:.1f}fps")
landmarks_list = []
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 프레임 처리
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = holistic.process(rgb_frame)
frame_data = {
"pose": results.pose_landmarks,
"left_hand": results.left_hand_landmarks,
"right_hand": results.right_hand_landmarks,
}
landmarks_list.append(frame_data)
frame_count += 1
cap.release()
print(f" ✅ 랜드마크 추출 완료: {len(landmarks_list)}프레임")
return landmarks_list다음으로 target_length로 시퀸스 길이를 정규화합니다. 각 시퀸스의 길이가 일정하지 않을 경우 모델 정확도를 떠나서 형상이 불일치하기 때문에 길이 정규화는 필수입니다.
def normalize_sequence_length(sequence, target_length):
"""시퀀스 길이를 정규화합니다."""
current_length = len(sequence)
if current_length == target_length:
return sequence
x_old = np.linspace(0, 1, current_length)
x_new = np.linspace(0, 1, target_length)
normalized_sequence = []
for i in range(sequence.shape[1]):
f = interp1d(
x_old,
sequence[:, i],
kind="linear",
bounds_error=False,
fill_value="extrapolate",
)
normalized_sequence.append(f(x_new))
return np.array(normalized_sequence).T
마지막으로 각 랜드마크의 절대 좌표를 어깨 기준의 상대 좌표값으로 변경합니다. 랜드마크 값은 기본적으로 절대 좌표계 스케일로 표현되므로, 각 영상마다 그 상대적인 관절 위치들이 다 다를 겁니다. 이런 노이즈가 그대로 입력 데이터에 반영되면 특징점 추출의 장점을 전혀 살릴 수 없겠죠. 몸의 어떤 중심을 기준으로 손이 어떻게 움직이는지 알아야 하므로, 양 어깨를 기준으로 모든 좌표값을 상대좌표값으로 변환하여 '신체의 움직임'이라는 특징을 잘 살릴 수 있었습니다. 이를 특징점 엔지니어링(feature engineering)이라고 합니다.
def convert_to_relative_coordinates(landmarks_list):
"""절대 좌표를 어깨 중심 상대 좌표계로 변환합니다."""
relative_landmarks = []
for frame in landmarks_list:
if not frame["pose"]:
relative_landmarks.append(frame)
continue
pose_landmarks = frame["pose"].landmark
left_shoulder = pose_landmarks[11]
right_shoulder = pose_landmarks[12]
shoulder_center_x = (left_shoulder.x + right_shoulder.x) / 2
shoulder_center_y = (left_shoulder.y + right_shoulder.y) / 2
shoulder_center_z = (left_shoulder.z + right_shoulder.z) / 2
shoulder_width = abs(right_shoulder.x - left_shoulder.x)
if shoulder_width == 0:
shoulder_width = 1.0
new_frame = {}
if frame["pose"]:
relative_pose = []
for landmark in pose_landmarks:
rel_x = (landmark.x - shoulder_center_x) / shoulder_width
rel_y = (landmark.y - shoulder_center_y) / shoulder_width
rel_z = (landmark.z - shoulder_center_z) / shoulder_width
relative_pose.append([rel_x, rel_y, rel_z])
new_frame["pose"] = relative_pose
for hand_key in ["left_hand", "right_hand"]:
if frame[hand_key]:
relative_hand = []
for landmark in frame[hand_key].landmark:
rel_x = (landmark.x - shoulder_center_x) / shoulder_width
rel_y = (landmark.y - shoulder_center_y) / shoulder_width
rel_z = (landmark.z - shoulder_center_z) / shoulder_width
relative_hand.append([rel_x, rel_y, rel_z])
new_frame[hand_key] = relative_hand
else:
new_frame[hand_key] = None
relative_landmarks.append(new_frame)
return relative_landmarks
이렇게 전처리를 거친 벡터 시퀸스를 가지고 라벨 데이터와 함께 지도 학습을 진행합니다. (지도 학습의 세부적인 사항은 다루지 않겠습니다.)
모델 학습
def create_simple_model(input_shape, num_classes):
"""간단하고 효과적인 모델을 생성합니다."""
inputs = Input(shape=input_shape)
# 1D CNN
x = Conv1D(64, kernel_size=3, activation="relu", padding="same")(inputs)
x = MaxPooling1D(pool_size=2)(x)
x = Dropout(0.3)(x)
x = Conv1D(128, kernel_size=3, activation="relu", padding="same")(x)
x = MaxPooling1D(pool_size=2)(x)
x = Dropout(0.3)(x)
# LSTM
x = Bidirectional(LSTM(64, return_sequences=True))(x)
x = Dropout(0.3)(x)
x = Bidirectional(LSTM(32))(x)
x = Dropout(0.3)(x)
# Dense layers
x = Dense(64, activation="relu")(x)
x = Dropout(0.3)(x)
x = Dense(32, activation="relu")(x)
x = Dropout(0.3)(x)
outputs = Dense(num_classes, activation="softmax")(x)
model = Model(inputs=inputs, outputs=outputs)
return model
앞서 입력값인 미디어파이프 랜드마크 시퀸스에 대해 보았습니다. 형상이 (675, 60)으로 단순한 편이지만 두 번째 요소인 시간 축을 무조건 구별해서 판단해야 하기 때문에 다양한 형상을 입력으로 받을 수 있는 CNN을 사용했고, 이미지 특징을 추출 후 그 값을 시게열 데이터 분류에 뛰어난 LSTM 레이어에 통과시켰습니다. 최종적으로는 Dense 레이어를 적용하여 출력을 내보냈습니다. 모델은 TensorFlow 프레임워크의 기본 신경망들을 가지고 왔습니다.
과적합 문제
대응
짧았던 프로젝트 기간으로 인해 하이퍼파라미터 튜닝을 할 시간이 없었고, 대신 주목했던 부분은 과적합 문제를 해결하는 것이었습니다. 과적합은 역전파를 통한 파라미터 갱신 과정에 파라미터 값들이 과도하게 훈련 데이터에 맞춰져서 일반화 능력이 떨어지는 현상을 의미하죠. 데이터는 80개 가량이었고 파라미터는 모든 신경망을 합쳐서 300000개 가량 있는 상황이기에 이상적인 파라미터:데이터 비율인 100:1에 한참 못 미쳤고, 과적합이 발생할 수 밖에 없었습니다.
여기에 대한 가장 효과적인 해결책은 사실 전이학습입니다. 기존 학습 가중치를 가져와서 학습시키고자 하는 데이터로 다시 학습시키는 방법이죠. 하지만 수어 학습 서비스에서 전이학습에 실패한 결정적인 이유가 있습니다. 입력값의 특수성입니다. 대부분의 미디어파이프 랜드마크를 분류하는 모델은 ‘프레임’ 하나를 분류하는데 초점이 맞춰져 있지, 연속적인 시퀸스를 분류하는 모델은 찾기 쉽지 않았습니다.
미디어파이프 랜드마크를 버리고 일반적인 영상 분류 모델을 대신 찾았다면 전이 학습을 수행할 수 있었겠지만, 이 경우 미디어파이프 랜드마크의 뛰어난 특징점 추출 과정을 포기해야 하고, 훨씬 ‘간접적인’ 방식으로, 그러니까 ‘동작’이 아닌 ‘동영상’ 데이터 그대로 분류를 해야 하는 핸디캡이 발생했습니다. 수어 학습 서비스에 있어 동작을 추출하는 특징점 추출은 웬만한 전이학습으로는 포기할 수 없는 이점이라고 생각했습니다.
따라서 부족한 데이터만으로, 과적합을 대응해가며 학습을 하기로 결정했습니다. 과적합 해결을 위해 아래와 같은 방식들을 차용했습니다.
- Weight Decay(L2 Norm)
- Drop out
- Augmentation
각 기법들의 자세한 설명은 이 글을 참조해 주시기 바랍니다.
결과
Feature Extraction, Feature Engineering, 과적합 대응 덕분에 꽤 부족한 데이터에도 불구하고, 일반화 능력이 어느 정도 있는 모델을 학습 시킬 수 있었습니다.
아래는 훈련시킨 모델 중 하나였던 sign_language_model_20250722_165913.keras 모델에 대한 F1 score 테스트 결과입니다. 모델이 많고, 여러 모델의 테스트를 위한 test set 구하기가 쉽지 않아 총 150개 영상을 직접 찍어 이 모델에 대해서만 테스트를 수행했습니다.
"f1_score_weighted": 0.7464781700100468,
"f1_scores_per_class": {
"어린이": 0.9830508474576272,
"어제": 0.6031746031746031,
"어지러움": 0.47761194029850745,
"언니": 0.6792452830188679,
"None": 1.0
}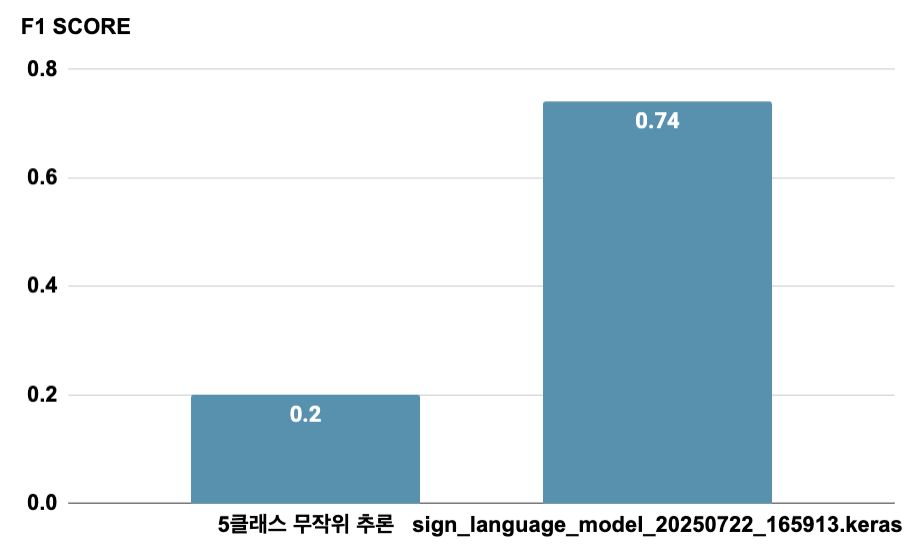
해당 모델은 어지러움, 언니, 어린이, 어제, None을 구별할 수 있는 모델이었고, 각 클래스별로 편차가 있지만 평균은 0.74로 5클래스 분류 모델임을 고려했을 때 유의미하게 구별력이 있음을 수치를 통해 볼 수 있습니다.
시간과 자원이 허락한다면 나머지 모델에 대해서도 더 많은 데이터로 테스트를 진행하고 싶지만, 그나마 제한된 상황 속에서 최소한의 검증을 거칠 수 있어 다행이었습니다.
지금까지 수어 학습 서비스를 위한 딥러닝 모델 훈련 과정, 적용 아이디어를 살펴보았습니다. 다음 글에서는 이 모델로 피드백 서비스의 실시간 신뢰성을 구현한 방안을 살펴보도록 하겠습니다.
감사합니다.
