토비의 스프링 스터디를 진행하며 작성한 글 입니다. 대부분 토비의 스프링을 참조하고 있습니다.
1.1 초난감 DAO
DAO(Data Access Object) : DB 를 사용해 데이터를 조회하거나 조작하는 기능을 전담하도록 만든 오브젝트
오브젝트와 의존관계에 대해 알아보기 위해 초난감 DAO 라는 예시를 만들어 보겠습니다. 초난감 DAO 는 실무에서는 쓰이지 않을 문제가 많은 코드인데요, 이를 구현하기 위한 코드들은 아래와 같습니다.
먼저 사용자 정보(id, name, password)를 저장할 User 클래스를 만듭니다.
public class User {
String id;
String name;
String password;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}그리고 실제로 User 오브젝트의 정보를 담을 수 있는 DB 테이블을 생성합니다.
create table users (
id varchar(10) primary key,
name varchar(20) not null,
password varchar(10) not null
);
이번에는 사용자 정보를 DB에 넣고 관리할 수 있는 UserDao를 만들어보겠습니다.
DB에 값을 저장하거나 조회하려면 아래와 같은 프로세스를 거쳐야합니다.
- 드라이버 로드
- Connection 가져오기
- SQL을 담은 statement 작성
- 만들어진 statement 실행
- 조회의 경우 불러온 값을 저장할 오브젝트에 담아 전달
- Connection, Statement, ResultSet 같은 리소스는 작업을 마친 후 닫아주기
- 예외 처리
이렇게 하면 안된다는걸 알지만 초난감 DAO를 만들기 위해 하나의 DAO 안에 이 프로세스를 모두 담아보겠습니다.
public class UserDao {
public void add(User user) throws ClassNotFoundException, SQLException {
Class.forName("org.mariadb.jdbc.Driver");
Connection c = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test",
"testId",
"password"
);
PreparedStatement ps = c.prepareStatement(
"insert into users(id, name, password) values(?,?,?)"
);
ps.setString(1, user.getId());
ps.setString(2, user.getName());
ps.setString(3, user.getPassword());
ps.executeUpdate();
ps.close();
c.close();
}
public User get(String id) throws SQLException, ClassNotFoundException {
Class.forName("org.mariadb.jdbc.Driver");
Connection c = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test",
"testId",
"password"
);
PreparedStatement ps = c.prepareStatement(
"select * from users where id = ?"
);
ps.setString(1, id);
ResultSet rs = ps.executeQuery();
rs.next();
User user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
rs.close();
ps.close();
c.close();
return user;
}
}코드를 작성하고 보니 중복도 많고, UserDao의 책임이 아닌 것처럼 보이는 것들도 많이 담아져 있습니다.
일단 작성한 코드가 정상적으로 작동하는지 확인해보겠습니다.
간단히 테스트를 위한 클래스를 만들고 main()을 통해 기능이 잘 작동하는지 확인해봤습니다.
public class TestMain {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
UserDao dao = new UserDao();
User user = new User();
user.setId("testId");
user.setName("테스트아이디");
user.setPassword("password");
dao.add(user);
System.out.println(user.getId() + " 등록 성공");
User user2 = dao.get(user.getId());
System.out.println(user2.getName());
System.out.println(user2.getPassword());
System.out.println(user2.getId() + " 조회 성공");
}
}
원하는대로 등록도 잘되고 조회도 잘 되었습니다.
하지만 기능만 잘된다고 끝이 아니겠죠. 이제 이 초난감 DAO 를 조금씩 개선시켜 보겠습니다.
testId 등록 성공
테스트아이디
password
testId 조회 성공
Process finished with exit code 01.2 DAO의 분리
모든 것은 변합니다. 코드도 마찬가지죠.
한 번 작성하고 잘 작동하면 끝날 것 같지만 코드의 구조가 변할 수도 요구사항이 변할 수도 있습니다.
객체지향 기술은 변화에 효과적으로 대처할 수 있다는 특징 때문에 초기 설계에 시간을 많이 쏟아야하는데요. 어떻게 하면 미래의 변화에 효과적으로 대처할 수 있게 설계를 할 수 있을까요?
분리와 확장을 고려한 설계가 답 입니다.
프로그래밍의 기초 개념 중 관심사의 분리라는게 있는데, 이를 객체지향에 적용해보면 관심이 같은 것끼리는 하나의 객체 또는 친한 객체로 모이게 하고, 관심이 다른 것은 가능한 떨어뜨려 서로 영향을 주지 않도록 분리하는 것이라고 생각할 수 있습니다.
커넥션 만들기 추출
UserDao의 관심사항
지금 만들어져 있는 UserDao를 보면 아주 바빠보입니다. DB Connection도 만들어야하고, 쿼리도 만들어서 DB에 날려줘야하고, 결과 값을 가공해서 요청한 클라이언트에게 전달도 해줘야합니다.
개중에 또 문제가 되는 부분은 DB Connection을 연결하는 부분을 add와 get 메서드가 모두 사용하면서 중복이 일어나고 있다는 점 입니다.
지금처럼 코드가 많지 않으면 그나마 낫지만 실무에서는 수십 수백군데에서 사용할 수 있는 로직인데요, 모두 중복으로 사용하다가 코드에 수정이라도 생긴다고 생각하면... 끔찍합니다.
이걸 보듯이 하나의 관심사(DB Connection)가 여러군데에서 중복되어 있고 다른 관심의 대상과 얽혀있으면, 변경이 일어날 때 끔찍한 일이 발생할 수 있습니다.
중복 코드의 메소드 추출
중복되어 사용되고 있는 DB Connection 로직을 메소드로 추출해서 관심사를 집중 시켜 보겠습니다.
public class UserDao {
public void add(User user) throws ClassNotFoundException, SQLException {
Connection c = getConnection();
...
}
public User get(String id) throws SQLException, ClassNotFoundException {
Connection c = getConnection();
...
}
private static Connection getConnection() throws ClassNotFoundException, SQLException {
Class.forName("org.mariadb.jdbc.Driver");
return DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test",
"testId",
"password"
);
}
}로직을 DB Connection에 집중한 관심사로 모아 새로운 메소드를 만들고, 기존 로직에 넣었습니다. 이제 DB Connection의 관심에 대한 변화가 생기면 다른 코드에는 영향을 주지 않고 관심이 집중된 코드만 수정하면 됩니다. 관심이 독립적으로 독립하면서 변화에 대응하기 쉬운 코드가 되었습니다.
변경사항에 대한 검증
이렇게 리팩토링을 한 후에 main()을 통해 검증을 해보면 잘 작동하는걸 볼 수 있습니다. 방금 한 작업은 기능상에는 어떠한 영향도 주지 않았지만 변화에 좀 더 손쉽게 대응할 수 있는 보다 더 깔끔한 코드가 되었습니다.
커넥션 만들기의 독립
이번에는 이런 상황을 가정해보겠습니다. UserDao의 인기가 너무 많아져서 다른 곳에서도 UserDao를 가져다 쓰고 싶어하고 있습니다. 그런데 DB Connection 로직만은 외부에 공개하고 싶지가 않은거죠.
이런 경우에는 UserDao를 추상 클래스로 만들고 getConnection을 추상 메소드로 선언해서, 외부에서 UserDao를 상속받게 한 뒤 각자 입맛에 맞게 getConnection을 구현하도록 하는 방법을 사용할 수 있습니다. 아예 데이터베이스 연결이라는 관심사 자체를 외부(추상 클래스를 상속한 서브클래스)로 독립시켜버리는거죠.
public abstract class UserDao {
public void add(User user) throws ClassNotFoundException, SQLException {
Connection c = getConnection();
...
}
public User get(String id) throws SQLException, ClassNotFoundException {
Connection c = getConnection();
...
}
public abstract Connection getConnection() throws ClassNotFoundException, SQLException;
}
추상 클래스인 UserDao를 상속 받아서 getConnection만 독립적으로 구현했습니다. 이 방식을 이용하면 UserDao에서 코드를 수정할 필요가 없어지고, 새로운 DB Connection 방식이 필요하다면 손쉽게 상속 받아서 새롭게 확장하여 구현하면 됩니다.
public class NUserDao extends UserDao {
@Override
public Connection getConnection() throws ClassNotFoundException, SQLException {
// 독립된 DB Connection 구현
System.out.println("독립적으로 구현!!!");
Class.forName("org.mariadb.jdbc.Driver");
return DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test",
"testId",
"password"
);
}
}
이렇게 슈퍼클래스에 기본적인 로직의 흐름을 짜두고, 기능의 일부를 추상 메소드나 오버라이딩이 가능한 메소드 등으로 만든 뒤 서브 클래스에서 필요에 맞게 구현하도록 하는 디자인 패턴을 템플릿 메소드 패턴 이라고 합니다.
그리고 서브 클래스의 getConnection 처럼 어떤 클래스의 오브젝트를 어떻게 생성할지에 대한 방법을 결정하게 하는 디자인 패턴을 팩토리 메소드 패턴 이라고 합니다.
이런 방식으로 서브 클래스에게 구현을 넘기게 되면 UserDao는 DB Connection에 대해 Connection 인터페이스 타입의 오브젝트라는 것 외에는 관심을 두지 않고, 그저 Connection 인터페이스에 정의된 메소드를 사용할 뿐 입니다.
그리고 각 서브 클래스는 Connection 을 어떤식으로 제공하는지에 관심을 가지고 있는거죠.
이렇게 관심사를 좀 더 분리해봤습니다.
보다 더 깔끔해졌지만 이 방식에도 단점이 있습니다. 우리는 상속을 사용하면서 관심사를 분리했는데, 자바의 클래스는 다중상속을 허용하지 않습니다. 이미 다른 슈퍼클래스를 상속했을 수도 있고 추후에 상속할 가능성도 없지 않은데, 단지 Connection을 구현하기 위해 상속을 써먹기에는 아쉬움이 많습니다.
뿐만 아니라 상속관계라는건 어쩔 수 없이 긴밀한 관계를 유지할 수 밖에 없는데요, 서브 클래스는 슈퍼 클래스의 기능을 직접 사용할 수 있기 때문에 슈퍼 클래스에서 변경이 생기면 서브 클래스에도 영향을 끼칠 수 있습니다. 서브 클래스가 많다면 각각의 서브 클래스들을 다 변경해줘야 할 수도 있고... 어디서 많이 본 상황이 펼쳐지죠?
그리고 새로 만든 DB Connection 기능을 다른데서 사용할 수 없는 것도 문제가 됩니다. 각자의 방식대로 구헌은 했다지만 동일한 방식으로 DB Connection 을 사용할 경우 이를 갖다쓰지 못하고 계속 새로 구현해야하는 경우도 생길 수 있습니다.
1.3 DAO의 확장
여러모로 단점이 많이 보이는 상속을 제쳐두고 관심사를 좀 더 확실히 분리해보도록 하겠습니다.
클래스의 분리
우리는 DB Connection이라는 관심사를 UserDao의 다른 관심사와 분리하기 위해서 처음에는 독립된 메소드를 만들었고, 그 다음에는 상속 관계를 가진 클래스로 분리했습니다.
이번에는 좀 더 독립성을 보장하고자 아예 다른 클래스로 만들어 관심사를 분리하겠습니다. SimpleConnectionMaker 라는 DB Connection 에 대한 관심을 두는 클래스를 만들고, UserDao 에서는 새로 만든 클래스를 이용하게 됩니다. 참 쉽죠?
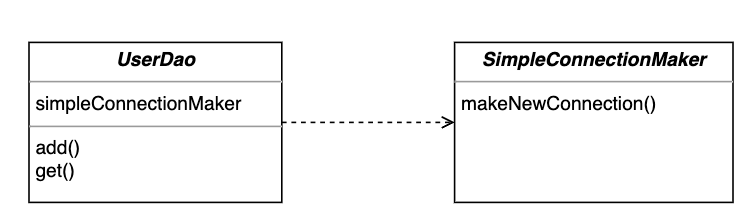
코드를 작성해보겠습니다.
DB Connection 기능을 가지는 SimpleConnectionMaker 라는 클래스를 생성합니다. 이제 어디서 이걸 상속할 일은 없으니 추상클래스 등으로 만들 필요는 없습니다.
public class SimpleConnectionMaker {
public Connection makeNewConnection() throws ClassNotFoundException, SQLException {
Class.forName("org.mariadb.jdbc.Driver");
return DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test",
"testId",
"password"
);
}
}
그리고 UserDao 의 생성자에 SimpleConnectionMaker 의 오브젝트를 만들어두고 각각의 메소드에서 필요할 때 가져다 쓰면 됩니다.
public class UserDao {
private SimpleConnectionMaker simpleConnectionMaker;
public UserDao() {
simpleConnectionMaker = new SimpleConnectionMaker();
}
public void add(User user) throws ClassNotFoundException, SQLException {
Connection c = simpleConnectionMaker.makeNewConnection();
...
}
public User get(String id) throws SQLException, ClassNotFoundException {
Connection c = simpleConnectionMaker.makeNewConnection();
...
}
}이렇게 함으로써 상속으로부터 벗어나기는 했는데 아직도 문제가 있습니다.
기존에 상속을 사용했을 때는 각자의 입맛에 맞게 getConnection() 을 확장해서 사용할 수 있었지만 이제는 UserDao 의 코드를 바꾸지 않으면 DB 연결 기능을 변경할 수가 없습니다. 변경하기 위해서는 simpleConnectionMaker = new SimpleConnectionMaker(); 를 바꿔야합니다. 이렇게 되면 다른 곳에서 UserDao 를 쓰려고 할 때 DB Connection 정보를 알 수 밖에 없습니다.
클래스 분리 후에도 자유롭게 확장 가능하게 하려면 두 가지 문제를 해결해야하는데요, 첫 번째는 메소드가 문제가 됩니다. 지금은 가져다 쓰는 곳이 몇 군데 되지 않아서 괜찮지만 만약 기능을 구현한 SimpleConnection의 메소드 이름이 makeNewConnection 에서 createNewConnection 등으로 바뀌게 된다면, 이 메소드를 사용한 모든 곳을 찾아가서 다 바꿔줘야합니다.
Connection c = simpleConnectionMaker.makeNewConnection();
-> simpleConnectionMaker.createNewConnection();
그리고 두 번째 문제는 UserDao가 DB Connection 을 해주는 클래스가 어떤 것인지 구체적으로 알고 있어야 한다는 것 입니다. 알고 있어야 한다는 이야기는 기능을 구현한 클래스가 다른 클래스로 바뀌게 되면 그 변화에 맞춰 UserDao에도 수정할게 생긴다는 이야기 입니다.
이 문제들의 근본적인 원인은 UserDao가 DB Connection 에 대한 정보를 너무 많이 알고 있기 때문인데요, 이 문제를 해결하기 위해 인터페이스를 도입해 보겠습니다.
인터페이스의 도입
인터페이스는 두 개의 클래스를 보다 더 추상적으로 연결시켜 줍니다. makeConnection 이라는 기능을 추상화시킨 ConnectionMaker 라는 인터페이스를 중간에 두게 되면 UserDao는 그 뒤의 구현이 어떻게 되든 모르고 있어도 됩니다. 그저 ConnectionMaker.makeConnection이 DB connection 의 역할을 해준다는 것만 알고 있으면 되죠.
그리고 구현하는 입장에서는 각자의 입맛에 맞게 makeConnection을 구현해 놓기만 하면 됩니다.
이렇게 인터페이스가 중간에 껴주면 각자의 세부 구현에 변화가 생겨도 UserDao는 영향을 받지 않게 됩니다.
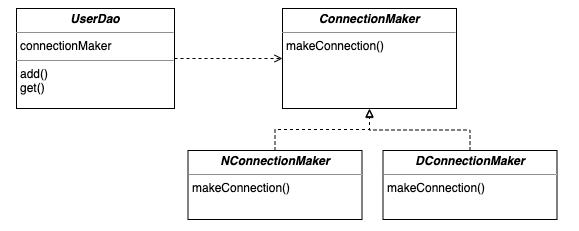
코드로 한 번 살펴보죠.
먼저 DB 연결 기능을 구현할 메소드인 makeConnection 을 설정해줍니다.
public interface ConnectionMaker {
Connection makeConnection() throws ClassNotFoundException, SQLException;
}
그리고 나서 ConnectionMaker 인터페이스를 구현한 DconnectionMaker 를 만듭니다. DconnectionMaker는 자신만의 makeConnection 을 만들어 클라이언트에게 제공할 수 있게 되었습니다.
public class DConnectionMaker implements ConnectionMaker{
@Override
public Connection makeConnection() throws ClassNotFoundException, SQLException {
// 입맛대로 DB Connection 기능을 구현
return null;
}
}
UserDao는 이제 DB 연결 기능을 사용하기 위해 직접 구현체에 붙어서 메소드를 사용하지 않아도 됩니다. 연결 기능을 제공해주는 인터페이스인 ConnectionMaker에만 붙어서 add 메소드에서 사용하고 있습니다.
public class UserDao {
private ConnectionMaker connectionMaker;
public UserDao() {
connectionMaker = new NConnectionMaker();
}
public void add(User user) throws ClassNotFoundException, SQLException {
Connection c = connectionMaker.makeConnection();
...
}
이제 구현체 메소드의 세부 구현 내용까지는 몰라도 되게 되었는데, 아직 남아있는게 있습니다. 초기에 어떤 클래스의 오브젝트를 사용할지 결정하는 생성자에 어떤 구현체를 사용할지 설정하는 부분이 남아있네요.
이렇게 되면 결국은 UserDao가 ConnectionMaker 의 어떤 구현체를 사용해야하는지 알아야하기 때문에 두 클래스가 완전히 분리되었다고 말할 수 없겠네요.
그렇다면 어떻게 해야할까요?
public UserDao() {
connectionMaker = new NConnectionMaker();
}관계설정 책임의 분리
짧은 코드지만 아래의 코드 또한 관계설정이라는 뚜렷한 관심사를 가지고 있습니다. 이 관심사도 다른 관심사들과 분리를 해야할 것 같네요.
connectionMaker = new NConnectionMaker();기존의 관계를 보면 UserDao는 ConnectionMaker만 알고 이를 구현한 메소드를 사용해야할 것 같지만 실제로는 NconnectionMaker를 알고 있게 되었는데요, 이젠 알고 싶어도 모르게 책임을 넘기려고 합니다.
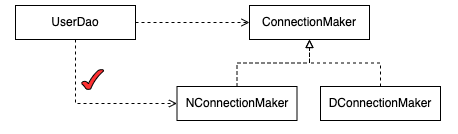
그럼 이 관계설정의 책임은 누가 가져가는게 좋을까요?
아무래도 UserDao를 사용하는 클라이언트가 설정하는게 좋을 것 같습니다.
이제 UserDao가 ConnectionMaker의 어떤 구현 클래스를 사용하게 될지 결정을 해줘야하는데요, 이는 UserDao 오브젝트와 ConnectionMaker를 구현한 특정 클래스로부터 만들어진 오브젝트 사이의 관계를 맺어주는걸 의미합니다.
두 클래스 간의 관계가 아닌 두 오브젝트 간의 관계라는걸 이해하는게 중요합니다. 클래스 사이의 관계라는건 코드 안에서 이루어지는 사용과 같은 관계라면 오브젝트 간의 관계라는건 런타임 시 동적으로 맺어진 관계 입니다.
코드에서는 서로를 알지 못했지만 특정 클래스를 구현한 인터페이스를 사용했다면 런타임 시 그 클래스의 오브젝트를 받아서 사용할 수 있게 되죠. 이건 객체지향 프로그램의 다형성이라는 특징 때문에 가능하게 됩니다.
코드로 한 번 살펴보죠.
먼저 UserDao의 생성자에 변화를 주겠습니다. 기존에는 생성자가 어떤 ConnectionMaker의 구현체를 사용할지 결정하는 책임까지 졌다면, 수정된 생성자에서는 외부에서 결정된 구현체를 받아서 생성자를 생성하고 있습니다.
인터페이스 구현체는 인터페이스로 받아서 사용할 수 있기 때문에 이런 방식이 가능합니다.
// 기존 생성자
public UserDao() {
connectionMaker = new DConnectionMaker();
}// 수정된 생성자
public UserDao(ConnectionMaker connectionMaker) {
this.connectionMaker = connectionMaker;
}
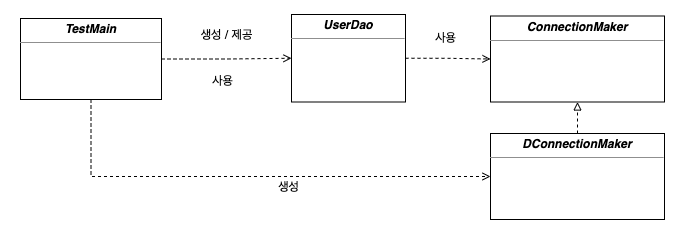
그리고 관계설정 책임은 UserDao를 사용하는 TestMain에게 넘겼습니다.
TestMain은 ConnectionMaker의 구현체로 DconnectionMaker를 사용할 것을 결정했고, 이 구현체로 만들어진 오브젝트를 UserDao에게 전달합니다.
public class TestMain {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
ConnectionMaker connectionMaker = new DConnectionMaker();
UserDao dao = new UserDao(connectionMaker);
...
}
}
TestMain이 관계설정 책임을 맡아준 덕분에 UserDao는 코드 상에서는 DConnectionMaker를 알지 못했지만 런타임에서는 DconnectionMaker와 관계를 맺고 구현된 부분을 사용할 수 있게 되었습니다.

이 관계를 관계도로 살펴보면 아래처럼 표현할 수 있습니다. TestMain은 DconnectionMaker를 생성했고, 이를 UserDao에 제공하면서 UserDao를 생성했고, 그러면서 생성된 UserDao를 사용합니다. 그리고 UserDao는 DConnectionMaker는 모른채 ConnectionMaker를 사용하면서 실제로는 구현된 기능을 온전히 누리게 됩니다.
원칙과 패턴
지금까지 살펴봤던 내용과 관련된 원칙과 패턴에 대해 잠깐 알아보겠습니다.
개방 폐쇄 원칙(Open-Closed Principle)
OCP 원칙은 클래스나 모듈은 확장에는 열려있고 변경에는 닫혀 있어야한다 라는 원칙인데요, 지금까지 해왔던 리팩토링을 설명하기에 딱 알맞은 원칙 입니다. 인터페이스와 클라이언트를 통해 UserDao - ConnectionMaker와의 관계를 설정하면서 UserDao는 ConnectionMaker 의 다양한 구현체들을 사용할 수 있게 되었고(확장), 그러면서도 UserDao 에는 변경이 일어나지 않게 하였습니다.
반대로 우리가 처음 만났던 초난감 DAO는 UserDao는 관심도 없는 DB Connection의 구현이 변할 때마다 끊임없이 영향을 받으며 고통 받았습니다.
잘 설계된 구조의 결과물이 느껴지시나요?
높은 응집도와 낮은 결합도
높은 응집도
응집도가 높다는 건 하나의 모듈, 클래스가 하나의 책임, 관심사에 집중하고 있다는 걸 의미합니다. 그리고 응집도가 높은 만큼 변화가 일어날 때 해당 모듈에서 변하는 부분이 크다는 걸 의미하기도 합니다.
예를 들어 처음의 초난감 DAO에서는 DB를 연결하는 기능에 수정이 생겼다고 하면 그와 관련된 다른 기능들에 어떤 영향을 끼치는지 쉽게 확인하기 어렵습니다.
반면 관계설정까지 마친 마지막 리팩토링 코드에서 DB 연결 기능이 수정된다고 하면 그냥 TestMain에서 변경된 ConnectionMaker의 구현체로 교체만하고, 구현체의 이상 유무만 파악하면 됩니다.
DB 연결에 대한 기능은 해당 구현체에만 속해있기 때문이죠. 객체지향의 원리 중 하나인 단일책임원칙(SRP)과도 비슷한 맥락입니다.
낮은 결합도
결합도라는건 하나의 오브젝트가 변했을 때 다른 오브젝트에 미치는 영향의 정도라고 볼 수 있는데 설계가 잘 되었다면 낮은 결합도가 유지되어야 합니다.
DB 연결 기능에 변화가 생겨도 UserDao 에는 큰 영향을 끼치지 않으니 결합도가 낮다고 볼 수 있죠. 중간에 인터페이스가 껴있기 때문에 이 낮은 결합도가 가능해졌습니다.
높은 응집도와 낮은 결합도 이 둘을 유지한다면 객체지향의 원칙을 잘 지켜가고 있다고 볼 수 있습니다.
전략 패턴
전략 패턴은 자신의 기능 컨택스트에서 변경이 필요한 기능을 인터페이스를 통해 외부로 분리시키고, 필요에 따라 구체적인 기능을 적용해서 사용할 수 있게 하는 디자인패턴 입니다.
DB 연결 기능 같은 기능을 DConnectionMaker나 NConnectionMaker처럼 대체가능한 전략으로 두고 필요에 따라 사용합니다.
그리고 TestMain과 같은 클라이언트에 대한 역할도 설명하고 있는데 컨텍스트를 사용하는 클라이언트는 컨텍스트가 사용할 전략을 생성자 등을 통해 제공하는게 일반적 입니다.
리팩토링 결과를 보면 높은 응집도와 낮은 결합도를 가지고 있으며 전략패턴을 사용해서 완벽한 코드가 된 것 같네요.
근데 과연 완벽할까요?
제어의 역전(IoC)
오브젝트 팩토리
이전 리팩토링에서 조금 마음에 걸렸던게 있는데요, 바로 TestMain이 관계설정이라는 역할까지 하고 있다는 점 입니다. 각자의 관심사에 맞게 응집도를 높이고 결합도를 낮춰야한다고 했는데, TestMain은 그저 테스트를 위해 만들어놓은 친구였는데 관계설정의 부담까지 가지게 되었습니다.
이제 이 부담을 덜어주려고 합니다.
팩토리
팩토리라는 개념은 객체의 생성 방법을 결정하고, 이에 따라 만들어진 오브젝트를 리턴해주는 클래스를 말하는데요, 이 팩토리 개념을 사용해서 관계설정이라는 기능을 분리시켜 보겠습니다.
먼저 UserDao의 관계를 설정해줄 DaoFactory 클래스를 만들어줍니다.
정말 딱 UserDao와 ConnectionMaker와의 관계만을 설정하고, 이 관계로 만들어진 오브젝트를 리턴해줍니다. 깔끔하고 간결하죠?
public class DaoFactory {
public UserDao userDao() {
ConnectionMaker connectionMaker = new DConnectionMaker();
return new UserDao(connectionMaker);
}
}TestMain 도 바꿔봅니다. 기존에는 관계설정까지 모두 해줬었지만 이제는 DaoFactory 에서 설정한대로 만들어진 UserDao를 데려와 사용합니다.
// 기존
public static void main(String[] args) throws SQLException, ClassNotFoundException {
ConnectionMaker connectionMaker = new DConnectionMaker();
UserDao dao = new UserDao(connectionMaker);// 수정
public static void main(String[] args) throws SQLException, ClassNotFoundException {
UserDao dao = new DaoFactory().userDao();
설계도로서의 팩토리
팩토리가 적용된 관계도는 아래와 같습니다. UserDao와 ConnectionMaker는 실질적인 로직을 담당하고 있고, DaoFactory는 관계설정과 같은 설계도의 역할을 해주고 있습니다.
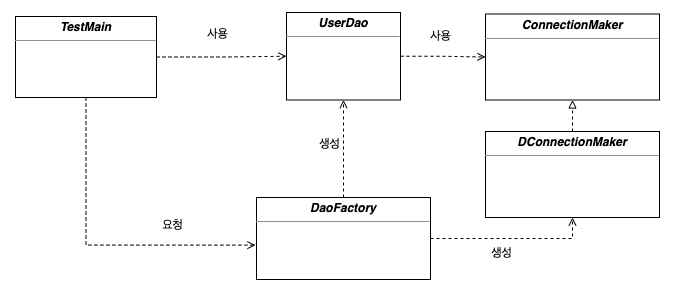
각자의 역할을 잘 하면서 깔끔하게 분리게 되었습니다.
오브젝트 팩토리의 활용
이전까지는 UserDao 하나를 사용할 때만 봤었는데요, 실무에서는 더 많은 Dao 들이 생겨나겠죠. AccountDao라는 Dao 가 새로 생겼다고 해보겠습니다.
AccountDao에도 똑같이 DConnectionMaker를 사용하고 싶은데요, 벌써부터 중복이 눈에 띄죠? 지금은 둘이지만 나중에 더 많은 Dao 들이 생겨난다면... 거기에 NConnectionMaker로 바꿀 니즈까지 생긴다면... 하나하나 모두 찾아서 바꿔야하는 불상사가 생깁니다.
public class DaoFactory {
public UserDao userDao() {
return new UserDao(new DConnectionMaker());
}
public AccountDao accountDao() {
return new AccountDao(new DConnectionMaker());
}
}이 문제는 초난감 DAO 초창기에 풀었던 방식인 메소드 추출로 해결할 수 있습니다.
공통된 new DeconnectionMaker를 반환해주는 메소드를 정의하고 각 Dao 설정 시점에 메소드를 불러 관계를 설정해줍니다. 이제 수정이 생겨도 connectionMaker() 만 수정하면 되겠죠?
public class DaoFactory {
public UserDao userDao() {
return new UserDao(connectionMaker());
}
public AccountDao accountDao() {
return new AccountDao(connectionMaker());
}
private ConnectionMaker connectionMaker() {
return new DConnectionMaker();
}
}
제어권의 이전을 통한 제어관계 역전
제어의 역전이라는 개념은 말 그대로 프로그램에 대한 제어의 흐름이 반대로 이루어진다는 의미입니다.
기존의 초난감 DAO를 보면 모든 제어의 흐름을 UserDao가 가지고 있습니다. 자신이 사용할 DB 연결 구현체를 자신이 결정하고, 사용하는 시점도 자신이 결정합니다.
반면에 리팩토링이 된 코드에서는 어떤 구현체를 사용할지 자신이 결정하지 않고 DaoFactory 라는 외부 클래스에게 제어권을 넘깁니다. 자신 또한 언제 생성될지 알 수 없고 제어권을 가진 대상에 의해 결정되고 만들어집니다.
프레임워크도 제어의 역전이 적용된 대표적인 기술이라고 볼 수 있습니다. 한 때 라이브러리와 프레임워크의 개념을 처음 접할 때 라이브러리는 내가 코드에서 능동적으로 사용하고, 코드 안에 라이브러리가 있다 이런 식으로 이해했고, 프레임워크는 프레임워크 안에 내 코드가 있어서 프레임워크에 의해 수동적으로 움직이게 된다 라고 이해했는데요.
프레임워크에 의해 수동적으로 움직이게 된다 라는 부분이 제어권이 자신(코드)에게 있지 않고 프레임워크에게 있다는걸 의미합니다. DaoFactory도 이런 의미에서 일종의 IoC 컨테이너, 프레임워크의 역할을 하고 있던거죠.
이렇듯 IoC의 개념을 사용하는 이유는 IoC를 적용하게 되면 설계가 깔끔해지고 유연성이 높아지고 이에 따른 확장성도 높아지기 때문입니다.
이런 설계가 가능해지려면 DaoFactory와 같은 설계도의 존재가 필요한데, 작은 수준이라면 DaoFactory로도 충분하겠지만 본격적으로 사용하고자 하면 스프링과 같은 IoC 프레임워크의 도움이 절실합니다.
스프링의 IoC
오브젝트 팩토리를 이용한 스프링 IoC
애플리케이션 컨텍스트와 설정정보
스프링에서는 스프링이 제어권을 가지고 통제하는 오브젝트를 빈(bean)이라고 부릅니다. 이 빈들에는 제어의 역전 개념이 적용되었다고 볼 수 있죠.
그리고 DaoFactory와 같이 빈의 생성과 관계설정을 해주는 오브젝트를 빈 팩토리라고 부릅니다. 보통은 빈 팩토리를 더 확장한 어플리케이션 컨텍스트(Application Context)를 주로 사용합니다.
빈 팩토리는 기본적인 빈의 생성과 관계설정을 하는 정도의 기능이 담겨 있고, 어플리케이션 컨텍스트에는 어플리케이션 전반에 대한 제어 작업을 할 수 있도록 기능이 확장되어 있습니다.
DaoFactory를 사용하는 애플리케이션 컨텍스트
기존에는 DaoFactory 가 설정 정보를 가지고 있으면서 생성과 관계설정까지 다 했다면 이제는 애플리케이션 컨텍스트라 DaoFactory의 설정 정보를 가져가서 IoC 엔진 역할을 해보도록 하겠습니다.
먼저 DaoFactory를 설정정보 역할을 할 수 있게 설정해줘야하는데요, 클래스에 @Configuration 어노테이션을 달아줍니다.
@Configuration
public class DaoFactory {
...
}@Configuration 에 들어가보면 요렇게 써있는데요.
Indicates that a class declares one or more @Bean methods and may be processed by the Spring container to generate bean definitions and service requests for those beans at runtime.
클래스가 하나 이상의 @Bean 메소드를 선언하고 런타임에 해당 빈에 대한 빈 정의 및 서비스 요청을 생성하기 위해 Spring 컨테이너에 의해 처리될 수 있음을 나타냅니다.thx to google
한마디로 스프링 컨테이너가 여기에 설정된 빈 메소드들을 가져다가 설정을 진행한단 말입니다.
참고로 @Configuration 안에 들어가면 @Component도 어노테이션에 포함되어있는걸 볼 수 있는데, 이 설정정보 자체도 빈으로 등록되어 스프링 컨테이너에 의해 관리됩니다.
그리고 나서 각각의 팩토리 메소드에 @Bean 어노테이션을 달아줍니다. 이제 각각의 메소드들은 빈으로 등록되어 스프링의 제어를 받을 준비가 되었습니다.
@Configuration
public class DaoFactory {
@Bean
public UserDao userDao() {
return new UserDao(connectionMaker());
}
@Bean
public AccountDao accountDao() {
return new AccountDao(connectionMaker());
}
@Bean
public ConnectionMaker connectionMaker() {
return new DConnectionMaker();
}
}
이제 설정 정보를 어플리케이션 컨텍스트에 등록해서 사용해보겠습니다.
기존에는 DaoFactory의 설정정보를 그대로 불러와서 사용했습니다.
// 기존
public class TestMain {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
UserDao dao = new DaoFactory().userDao();
}
}하지만 이제는 어플리케이션 컨텍스트 오브젝트를 만들고 여기에 DaoFactory를 주입해서 사용합니다.
주입을 완료하면 getBean 메소드로 설정정보에 등록되어 있는 빈 메소드를 불러와서 사용하면 됩니다.
// 수정
public class TestMain {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
ApplicationContext context = new AnnotationConfigApplicationContext(DaoFactory.class);
UserDao dao = context.getBean("userDao", UserDao.class);
}
}
기본적으로 getBean은 Object를 리턴하게 되어있어서 두 번째 인자로 타입을 명시해줘야 원하는 타입으로 리턴을 해줍니다.
Object getBean(String name) throws BeansException;
<T> T getBean(String name, Class<T> requiredType) throws BeansException;참고로 getBean을 할 때 빈 메소드의 이름을 기준으로 빈을 찾아오는데, 타입이 아닌 이름으로 하는 이유는 userDao()외에도 다른 설정을 적용한 다른 UserDao.class를 불러 올 수도 있기 때문입니다. 예를 들어 userDaoWithXConnection() 이런 식으로요!
그리고 테스트 실행 시 보여지는 창에도 변화가 생기는데요, 기존에는 sout 으로 찍은 실행 결과만 나왔다면 이제는 스프링이 각각의 빈을 생성해서 인스턴스를 초기화하는 프로세스까지 출력됩니다.
이제 뭔가 스프링을 쓰는 것 같네요!
[main] DEBUG org.springframework.context.annotation.AnnotationConfigApplicationContext - Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@704921a5
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'org.springframework.context.annotation.internalConfigurationAnnotationProcessor'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'org.springframework.context.event.internalEventListenerProcessor'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'org.springframework.context.event.internalEventListenerFactory'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'org.springframework.context.annotation.internalAutowiredAnnotationProcessor'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'org.springframework.context.annotation.internalCommonAnnotationProcessor'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'org.springframework.context.annotation.internalPersistenceAnnotationProcessor'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'daoFactory'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'userDao'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'connectionMaker'
[main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'accountDao'
testId 등록 성공
테스트아이디
password
testId 조회 성공애플리케이션 컨텍스트의 동작방식
어플리케이션 컨텍스트(이하 AC)는 빈 팩토리를 구현한 인터페이스를 상속했으니 일종의 빈 팩토리라고 볼 수 있습니다. 그 외에도 AC는 IoC 컨테이너, 스프링 컨테이너 등의 이름으로 불립니다.
AC의 동작방식을 도식화 해보면 아래와 같습니다.
- DaoFactory에 빈 메소드 설정정보를 담고 이 정보를 AC에 등록
- AC 는 이 설정보를 토대로 빈 목록을 만들어 놓고 있음
- client 에서 userDao를 요청하면 AC는 getBean으로 빈 목록을 조회함
- 조회된 빈을 생성하도록 DaoFactory에 요청
- 요청을 받은 DaoFactory는 빈을 생성하고, client는 생성된 userDao 빈을 사용
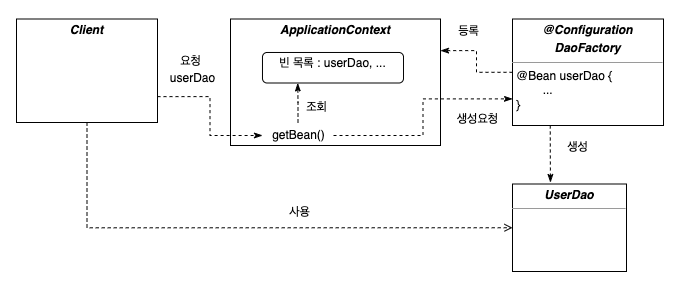
뭔가 DaoFactory 만으로 설정 정보를 활용했을 때보다 복잡해진 느낌인데요, 어떤 점들이 더 좋아서 AC를 사용하는걸까요?
먼저 클라이언트는 DaoFactory 같은 구체적은 팩토리 클래스를 알 필요가 없습니다. 모든 빈 정보가 DaoFactory에 들어있지 않은 이상 AC 가 없다면 매번 필요한 팩토리를 찾아서 오브젝트 정보를 찾아와야 합니다. AC를 사용하면 처음에 등록만 해놓고 일관된 방식으로 사용하면 됩니다.
그리고 AC 는 관계설정 외에 다른 기능들도 제공합니다. 오브젝트가 만들어지는 방식이나 시점부터 오브젝트에 대한 후처리 등등 종합 서비스를 제공합니다. 빈 검색 방식도 빈의 이름을 사용하는 것 외에 타입으로 검색하는 등 여러 방식을 제공합니다. 책의 뒤에서 다양한 예제를 더 살펴보겠습니다.
싱글톤 레지스트리와 오브젝트 스코프
아직까지는 DaoFactory 와 AC 방식의 차이를 느끼기 어렵지만 이들로 인해 생성되는 오브젝트를 보면 차이점을 확연이 느낄 수 있습니다.
각자의 방식으로 UserDao를 호출해서 그 값을 확인해 보겠습니다.
// 동일한 오브젝트인지 확인
UserDao dao1 = context.getBean("userDao", UserDao.class);
UserDao dao2 = context.getBean("userDao", UserDao.class);
System.out.println("dao1 = " + dao1);
System.out.println("dao2 = " + dao2);
System.out.println("dao1 == dao2 = " + (dao1 == dao2));
DaoFactoryBeforeVersion daoFactory = new DaoFactoryBeforeVersion();
UserDao userDao1 = daoFactory.userDao();
UserDao userDao2 = daoFactory.userDao();
System.out.println("userDao1 = " + userDao1);
System.out.println("userDao2 = " + userDao2);
System.out.println("userDao1 == userDao2 = " + (userDao1 == userDao2));차이점이 보이시나요? AC 로 만들어진 `UserDao`는 동일하지만 `DaoFactory`로 만들어진 오브젝트는 동일하지 않습니다. 왜 AC 는 같은 값을 가진 오브젝트가 만들어질까요?
이제 싱글톤에 대해 알아볼 때가 되었습니다.
// application context 사용
dao1 = UserDao@6c4906d3
dao2 = UserDao@6c4906d3
dao1 == dao2 = true
// 기존 DaoFactory 사용
userDao1 = UserDao@3081f72c
userDao2 = UserDao@3148f668
userDao1 == userDao2 = false싱글톤 레지스트리로서의 애플리케이션 컨텍스트
AC는 IoC 컨테이너기도 하면서 싱글톤을 저장하고 관리하는 싱글톤 레지스트리이기도 합니다.
스프링에서 별다른 설정을 하지 않으면 내부에서 생성되는 모든 빈 오브젝트는 싱글톤으로 만들어지는데요, 스프링이 사용하는 싱글톤과 일반적으로 말하는 싱글톤 패턴과는 구현 방식에서 차이가 좀 있습니다.
서버 애플리케이션과 싱글톤
왜 스프링은 빈을 싱글톤으로 만들까요?
그 이유는 스프링은 일반적으로 대용량 트래픽을 처리하는 서버 환경에서 사용되기 때문입니다. 아무리 세상이 좋아지고 컴퓨터 연산 능력이 좋아졌다고 해도, 초당 처리하는 연산의 양은 한계가 있기 마련입니다.
만약 싱글톤으로 오브젝트를 처리하지 않는다면 매 요청마다 새로운 오브젝트가 생성되어 서버가 감당할 수 없는 수준이 될 수도 있습니다.
그래서 스프링은 기본적으로 모든 오브젝트를 싱글톤으로 생성하고 이를 여러 스레드에서 공유해 동시에 사용하게 합니다.
싱글톤 패턴의 한계
일반적으로 자바에서 싱글톤을 구현한다고 하면 아래의 프로세스를 거칩니다.
- 클래스 밖에서 오브젝트를 생성하지 못하도록 생성자를 private 으로 샏성
- 만들어진 싱글톤 오브젝트를 저장할 수 있도록 자신의 static field 생성
- 외부에서 싱글톤 오브젝트를 불러올 수 있도록 스태틱하면서 public 한 생성자 getter 생성
싱글톤이 좋은 점이 있는건 알겠는데 적용하려면 기존 코드가 많이 지저분해집니다.
그리고 이렇게 구현하면서 문제점도 생겼습니다.
먼저 private 생성자를 갖고 있기 때문에 열려있는 다른 생성자를 만들지 않는 이상 다른 클래스가 상속하지 못합니다. 객체지향의 장점인 상속과 다형성을 충분히 이용하지 못하게 되죠.
그리고 만들어지는 방식이 제한적이기 때문에 다양한 주입, 생성 방법을 활용하기 어려워지고 이로 인해 테스트가 어렵거나 불가능해집니다.
또한 서버 환경에서는 싱글톤이 하나만 만들어지는게 보장되지 못합니다. 이부분은 세부 프로세스를 좀 더 확인해봐야 할 것 같습니다.
마지막으로 싱글톤의 사용은 전역 상태를 만들 수 있어 바람직하지 않습니다. 요 부분도 좀 더 확인해야겠습니다.
싱글톤 레지스트리
앞에서 스프링이 사용하는 싱글톤과 일반적으로 말하는 싱글톤 패턴과는 구현 방식에서 차이가 좀 있습니다. 라고 말했었는데요, 스프링은 방금 말한 단점들을 상쇄시켜주는 역할을 해줍니다.
스프링은 싱글톤 레지스트리로서 싱글톤을 관리해주는데요,일단 스태틱 메소드와 privat 생성자를 사용하지 않고도 싱글톤으로 만들어줍니다. 싱글톤으로 만든다기 보다는 싱글톤으로 활용할 수 있도록 관리해준다는 말이 맞는 것 같습니다.
문법상으로는 싱글톤이 아니기 때문에 일부 코드에서 싱글톤으로 사용하지 않고 싶은 경우에는 간단히 새로 오브젝트를 생성해서 사용하면 됩니다.
이로써 스프링에서는 싱글톤으로 만들지 않으면서도 싱글톤 방식을 활용할 수 있고, 싱글톤 패턴과는 달리 스프링이 지향하는 객체지향적인 설계 방식과 원칙을 벗어나지 않으면서도 개발을 할 수 있게 되었습니다.
싱글톤과 오브젝트의 상태
싱글톤은 멀티쓰레드 환경이라면 동시에 접근 가능하기 때문에 무상태(stateless)로 관리해야 합니다. 예를 들어 클래스의 인스턴수 변수를 수정할 수 있게 두면 언제 어느 쓰레드에서 어떤 변화가 생길 지 알 수 없습니다. 데이터가 엉망이 될 수 있는거죠!
물론 읽기전용 변수라면 상관 없습니다.
그럼 상태가 없는 방식으로 관리하려면 어떻게 해야할까요?
메소드 파라미터나 메소드 안에 생성되는 로컬 변수는 매번 값을 저장할 독립적인 공간이 할당 되기 때문에 여러 쓰레드에서 사용하더라도 덮어쓰이지 않습니다. 따라서 읽기 전용 변수가 아니라면 로컬 변수로 쓰는걸 고려해보세요!
코드로 한 번 살펴보겠습니다.
public class UserDao {
private ConnectionMaker connectionMaker; // 읽기전용 인스턴스 변수
private Connection c; // 인스턴스 변수
private User user; // 인스턴스 변수
...
public User get(String id) throws SQLException, ClassNotFoundException {
c = connectionMaker.makeConnection();
...
this.user = new User();
this.user.setId(rs.getString("id"));
this.user.setName(rs.getString("name"));
this.user.setPassword(rs.getString("password"));
...
}
}
기존에 로컬 변수로 선언되었던 Connection c와 User user를 인스턴스 변수로 빼봤습니다. 이렇게 사용하게 되면 멀티쓰레드 환경에서 데이터가 엉킬 수 있습니다. 이렇게 바뀔 수 있는 데이터는 이전처럼 로컬 변수로 사용하는게 좋습니다.
그런데 ConnecionMaker도 인스턴스로 선언되어있는데 왜 안전할까요? ConnectionMaker는 DaoFactory에서 @Bean으로 등록되었고, 그렇기 때문에 스프링에서 싱글톤으로 관리됩니다. 추가 설정을 하지 않았다면 최초 한 개만 만들어지기 때문에 멀티쓰레드 환경에서 사용해도 문제가 되지 않습니다.
읽기전용의 속성을 가진 인스턴스변수라면 사용해도 되지만 단순 읽기 전용 값이라면 static final 이나 final로 변경할 수 없게 만드는 것도 좋습니다.
스프링 빈의 스코프
빈이 생성되고, 존재하고, 적용되는 범위를 빈 스코프라고 합니다. 스프링의 기본 스코프는 싱글톤인데요, 스프링 컨네이너에 한 개의 오브젝트만 만들어져서 컨테이너가 떠 있는 동안에는 존재하는 스코프 입니다.
그 외에 컨테이너에 요청할 때마다 새로운 오브젝트를 만들어주는 프로토타입 스코프와 웹을 통해 새로운 HTTP 요청이 있을 때마다 새롭게 생성되는 요청 스코프가 있고, 웹의 세션과 스코프가 유사한 세션 스코프도 있습니다.
스코프에 대한 자세한 내용은 이후의 장에서 살펴보면 될 것 같습니다!
의존관계 주입(DI)
제어의 역전(IoC)과 의존관계 주입
제어의 역전이라는 개념은 스프링 외에도 많은 소프트웨어에서 사용되는 개념인데요, 그렇기에 스프링을 딱 설명해주는 단어라고 보기는 뭔가 좀 부족합니다.
그래서 사람들이 보다 더 스프링을 표한할 수 있는 말을 찾다가 의존관계 주입이라는 이름으로 스프링을 설명하기 시작했습니다. 스프링을 DI 컨테이너라고 주로 부르기 시작했죠.
스프링이 다른 프레임워크들과 좀 더 차별적으로 의존관계 주입이라는 방식을 제공하기 때문인데요, 이제 이 의존관계 주입에 대해서 알아보겠습니다.
런타임 의존관계 설정
의존관계
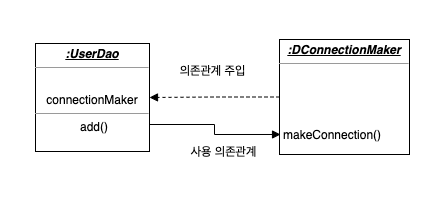
의존관계라는건 방향성이 존재해야합니다. 누가 누구를 의존하고 있다 이런식으로요. UML 모델에서는 의존관계를 아래와 같은 방식으로 표현합니다. 의존 방향으 점선 화살표로 표현하고, 아래의 관계도는 A가 B를 의존하고 있다는걸 의미합니다.
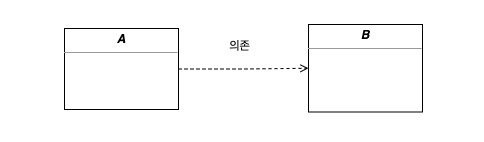
그럼 의존한다는건 어떤 의미일까요? A가 B를 의존한다고 했을 때 B에 변화가 생길 경우 A에 영향을 미친다는 뜻 입니다.
A가 B의 메소드를 쓰고 있다고 하면 이걸 사용에 대한 의존관계가 있다고 표현합니다. 만약 B의 메소드가 변하거나 내부 구현 기능이 변하게 되면 A도 그에 따라 변해야합니다. 그렇기에 A는 B를 알고 있어야하죠.
하지만 반대로 B는 A를 몰라도 됩니다. 즉 B는 A를 의존하고 있지 않습니다.
UserDao의 의존관계
우리가 만들어왔던 UserDao의 의존관계도 살펴보겠습니다.
UserDao는 실제로는 구현체인 DconnectionMaker의 기능을 사용하고 있지만 중간에 인터페이스인 ConnectionMaker를 두면서 구현체와는 느슨한 의존관계를 가지고 있습니다.
구현체에서 실제 기능을 구현하는 로직이 변하더라도 UserDao는 그저 인터페이스를 통해 메소드를 호출해서 사용합니다. 하지만 인터페이스에는 의존하고 있기에 인터페이스마저 변하게 된다면 UserDao도 영향을 받습니다.
그래도 최대한의 영향을 덜 받는 의존관계. 인터페이스를 통하면서 (구현체의) 변경에서 많이 자유로워졌습니다.
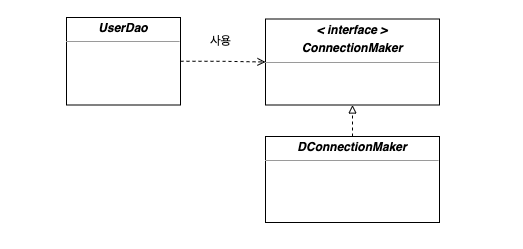
하지만 방금 본 것과 같은 코드 상에서 드러나는 의존관계 말고 런타임 의존관계 라는 것도 존재합니다.
UserDao와 ConnectionMaker는 코드상에서 맺어진 의존관계라면 UserDao와 DConnectionMaker는 런타임 때 맺어지는 런타임 의존관계 입니다.
여기서 의존관계 주입이라는 스프링의 특징이 나타나게 되는데, 스프링은 실제 사용 대상인 의존 오브젝트(DConnectionMaker)를 사용 주체인 클라이언트(UserDao)와 런타임시에 연결해주는 역할을 합니다.
이는 DConnectionMaker가 UserDao와 의존관계를 맺은 ConnectionMaker 인터페이스를 구현했기 때문에 가능한거죠.
정리해보면 의존관계 주입은 아래의 조건을 충족해야합니다.
- 클래스 모델이나 코드에는 런타임시의 의존관계가 드러나지 않으며, 인터페이스에만 의존하고 있어야 함(DaoFactory 와 같은 설정 코드는 제외)
- 런타임 시의 의존관계는 컨테이너나 팩토리 같은 제 3자가 결
- 사용할 오브젝트에 대한 레퍼런스를 외부에서 제공(주입)해줌으로써 만들어짐
여기서 제 3자의 역할이 중요한데 제 3자란 우리가 살펴봤던 어플리케이션 컨텍스트, 빈 팩토리 같은 외부의 오브젝트를 의미합니다.
UserDao의 의존관계 주입
의존관계를 주입하려면 제 3의 존재가 필요하고 그 역할을 DI 컨테이너인 DaoFactory가 하고 있습니다. DI 컨테이너는 UserDao를 생성하는 시점에 생성자 파라미터로 이미 만들어진 DConnectionMaker를 전달합니다. 실제로 오브젝트를 넣어주는건 아니고 레퍼런스를 전달하는거죠.
그리고 레퍼런스를 전달받은 UserDao는 자신의 인스턴스 변수에 저장해둡니다. 이렇게 런타임 의존관계가 만들어졌습니다.
public class UserDao {
private ConnectionMaker connectionMaker;
public UserDao(ConnectionMaker connectionMaker) {
this.connectionMaker = connectionMaker;
}
}아래의 관계도처럼 런타임 시점에 `DConnectionMaker`는 `UserDao`의 인스턴스 변수인 `connectionMaker` 에 주입되고, `UserDao`는 `DConnectionMaker`의 `makeConnection()` 메소드를 사용합니다.
이런 DI는 자신이 사용할 오브젝트에 대한 선택, 생성에 대한 제어권을 외부에 넘기고 자신은 수동적으로 사용한다는 점에서 IoC의 개념과 딱 들어맞습니다.
의존관계 검색과 주입
의존관계를 맺는 방법에는 주입 말고도 검색이라는 방법도 있습니다.
의존관계 검색은 어떤 관계를 맺을지는 외부에서 결정하지만 언제 어떻게 주입할지를 스스로 결정하는 방식 입니다.
아래와 같이 직접 설정 정보인 DaoFactory를 통해 원하는 의존대상을 가져와서 직접 주입 합니다.
public UserDao() {
DaoFactory daoFactory = new DaoFactory();
this.connectionMaker = daoFactory.connectionMaker();
}이전에 봤던 어플리케이션 컨텍스트의 getBean도 의존관계 검색 방식입니다.
ApplicationContext context = new AnnotationConfigApplicationContext(DaoFactory.class);
UserDao dao = context.getBean("userDao", UserDao.class);코드를 보면 의존관계 주입이 좀 더 깔끔해보입니다.
의존관계 검색과 주입의 중요한 차이점은 의존 오브젝트를 사용하는 대상이 빈에 등록되어 있어야하는지 여부입니다. 검색의 경우 자신이 빈이 아니어도 DaoFactory 를 불러와서 의존 오브젝트를 찾아올 수 있지만, 주입의 경우에는 DI 프로세스 자체가 스프링에 등록된 빈들을 대상을 하기에 UserDao도 빈에 등록되어 있어야 합니다.
DI 를 원하는 오브젝트는 무조건 스프링에 빈으로 등록되어있어야 한다는 점을 잊지 마세요!
