Abstract
이 논문은 YOLO를 이용하여 도로에서 다양한 파손된 부분을 검출하는 방법을 설명한다. YOLOv5x 모델은 가볍고 빠르지만 좋은 정확도까지 가지고 있다. TTA를 사용한 앙상블 모델로 F1 score 0.58을 얻었다.
1. Introduction
본 대회에서, 데이터 셋은 스마트폰 베이스 방법으로 수집 되었다.
2. Related work
A. Road Damage Dataset
데이터 개수, 해상도
| Country | # of data | Resolution |
|---|---|---|
| Czech | 3,595 | 720 x 720 |
| India | 9,892 | 720 x 720 |
| Japan | 13,133 | 600 x 600 |
| Total | 26,620 |
- data format: JPEG
Damage type
| Damage type | Detail Information | Class name |
|---|---|---|
| Crack(longitude) | Wheel-marked part | D00 |
| Crack(Transverse) | Equal interval | D01 |
| Crack(Alligator) | Partial / Overall pavement | D20 |
| Other Damage | Pathole | D40 |
3. Experiments
-
Model: YOLOv5 사용
당시의 YOLO 중 SOTA model 이었다. YOLO v5는 CSPNet 기반의 모델이고, SPP(Spatial Pyramid Pooling layer)를 사용한다. -
V100 GPU 2대를 사용하였고, COCO dataset 대상으로 pretrained 된 weight을 fine-tuning해서 사용하였다.
-
Japan 데이터셋 중에 대회에서 사용 되지 않는 class들이 포함되어 있어서 제거 했다.
-
Preprocessing 한 후 데이터 셋
| Country | # of data | Resolution |
|---|---|---|
| Czech | 1,072 | 720 x 720 |
| India | 3,223 | 720 x 720 |
| Japan | 7,900 | 600 x 600 |
| Total | 12,195 |
-
training: 80%, validation: 20%
-
Data augmetation option: hue, saturation, value for HSV, image translation, image scale, mosaic, etc
-
default hyperparamenter
| hyper-parameters | value |
|---|---|
| Optimizer | SGD |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| weight decay | 0.0005 |
| epochs | 50 |
| batch size | 32 |
| confidence threshold | 0.4 |
| NMS with the IoU | 0.5 |
-
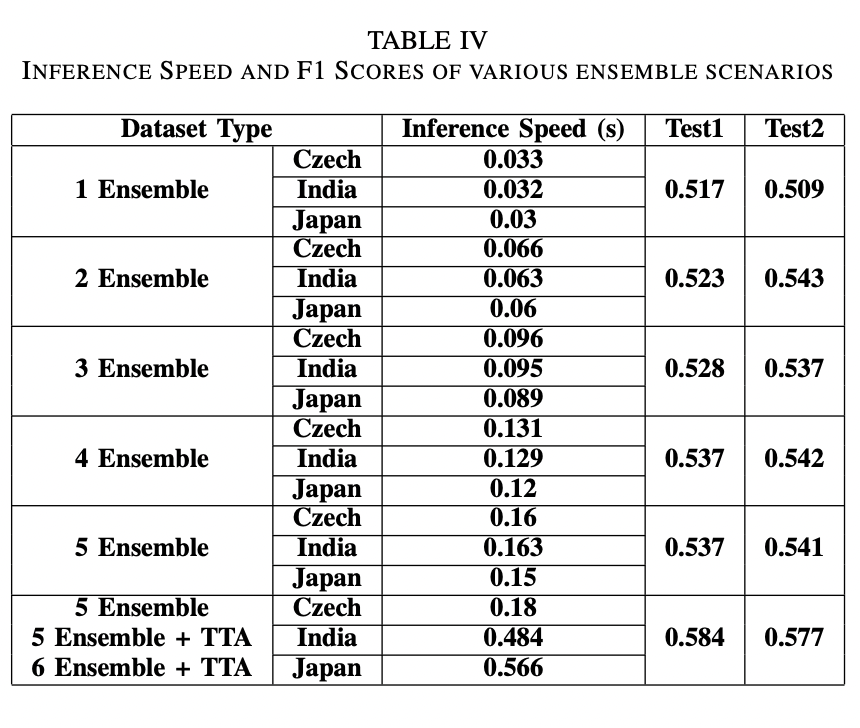
Japan 과 Czech 이미지 데이터셋을 함께 validation set으로 사용 하는 것은 Czech나 India dataset을 single로 사용 했을 때 보다 성능이 좋았다.
-
Table 2에서 Dataset의 의미는 학습데이터셋을 의미하고 model name의 의미는 데이터셋을 나누는 버전에 따라 이름을 지엇다. 예를들어 Japan1K_Czech_1은 1000개의 Japan이미지와 Czech road image version 1을 의미하고 Czech road image type을 예측한 모델이다.
4. Results
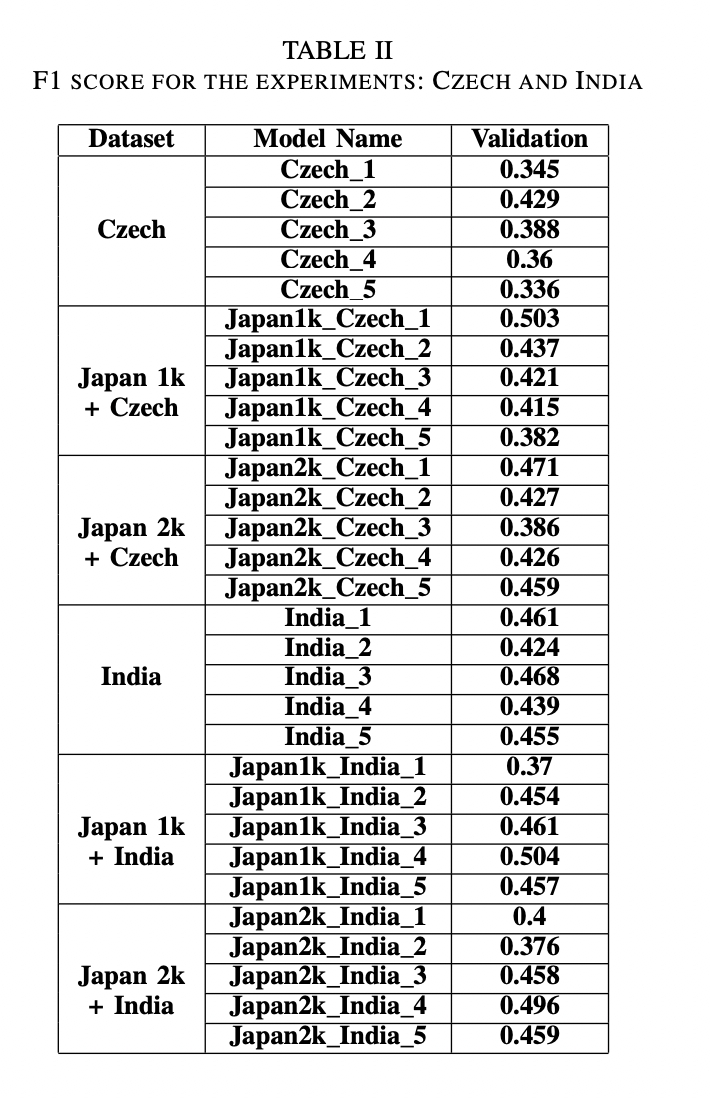
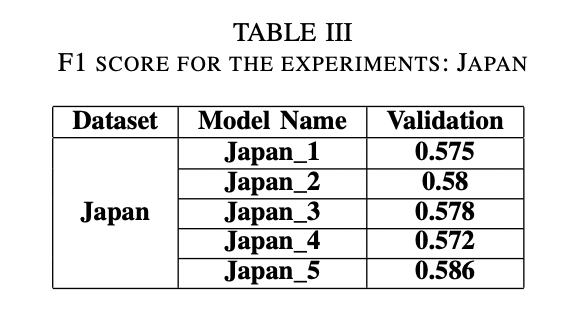
multi-country dataset으로 앙상블 모델을 사용하였다. confidence threshold는 0.4, NMS with IoU는 0.5이다. TTA(Test-Time Augmentation)을 적용하였지만 효과는 없었다. test1 dataset에 대해서 F1 score 0.568, test2 dataset에 대해서 F1 score 0.571을 얻었다.