
프로젝트 : 크롤한 웹데이터로 만들어보는 웹사이트
Day - 1 (2023. 11. 6.)
첫번째 프로젝트가 시작되었다. 지금까지 배웠던 것들을 사용해 크롤링 기반 웹데이터로 웹사이트를 만들어야 한다.
주말부터 오늘 아침까지 미리 팀원들과 회의를 하면서 주제를 선정하고 역할 분담을 마쳤다. 나는 웹 크롤링 파트를 맡았다.
주제로는 채용 사이트 이용한 기술 스택 (순위) 보여주는 웹 사이트를 만들기로 선정했다.
코드너리 사이트에서 관련 데이터들을 크롤하기로 결정했다. 처음에는 로그인이 필요한 듯 보여 Selenium 사용을 고려했으나 창이 열렸을 때 모달창이 나오는 것을 해결하지 못해서 막혔다.
꽤 난감했으나 시험삼아 몇 페이지를 크롤링한 결과 로그인이 없어도 원하는 정보를 얻는데 애로사항이 없는 것 같아 BeautifulSoup으로 노선을 변경했다.
성공적으로 원하는 정보를 크롤링하는데 성공했고 이 코드를 토대로 class를 이용해 코드를 작성해보기도 했다.
이후로 다른 사이트, 다른 정보를 크롤할 필요가 있다면 수정될 수도 있겠다.
Day - 2 (2023. 11. 7.)
어제 잘못된 정보를 가져와서 다시 해야한다. 어차피 코드너리의 공고들이 원티드 채용공고로 연결되기에 원티드에서 작업을 하기로 했다. 둘러보니 selenium을 써야할 것 같다. 필요한 건 회사명, 근무지역, 기술스택, 직무정도이다.
사이트에서 스크롤을 내리다가 발견한 건데 스크롤을 내리면서 새로운 공고들이 다시 생기더라. 혹시나 해서 개발자 도구로 확인하니 원래는 없던 태그들이 스크롤을 내리면서 새로 생기는 것을 확인했다. 아무래도 모든 정보를 긁어오려면 스크롤을 아래까지 먼저 내릴 필요가 있어보였다. 그래서 해당 코드를 추가하고 진행했다.
근무지역을 가져오는 작업 도중 에러가 발생했다. NoSuchElementException, 요소가 없다고 한다. 분명히 있는 걸 확인하고 접근했는데 없다는게 웬말인가? 구글링하면서 찾아도 해결방법이 보이지 않는다.
그렇게 몇시간을 잡고 있었을까. 불현듯 하나의 생각이 스쳤다. 아까 스크롤을 내리면서 새로운 공고가 생기면서 그에 따라 새로운 태그들이 생기는 것. 혹시나 해서 찾아보았다. 역시나 처음 웹페이지에 들어갔을 때 해당 태그가 없었다. 그래서 에러가 났던 것.
이제 스크롤을 내릴 코드를 추가하면 된다. 근데 이번에는 끝까지 내린다고 해당 태그가 나타나지 않는다. 근처 위치까지 내려야한다. 채용공고의 길이가 모두 달라 정량적으로 내리면 에러가 난다. 기준이 필요하다. 그 기준을 어떻게 정해야 하나?
이 방법 저 방법 다 써보다가 하나를 발견했다.

바로 이 구분선, 어느 채용 공고던 결국 근무지역은 이 선 아래에 있다. 이 선의 높이를 알아내 접근하는 코드를 추가했다.
드디어 성공했다. 이제 내일 코드 갈무리하고 데이터를 추출하면 될거같다.
Day - 3 (2023. 11. 8.)
어제 코드를 마무리해서 추출할 수 있도록 작성하고 추출을 시작했다.
그런데 에러가 나서 확인해보니 근무 위치를 공고에 명시하지 않은 회사들도 있었다. 또한 우리는 신입을 타겟으로 하기 때문에 신입을 대상으로 하는 공고들만 살펴보는데 신입을 대상으로 하는 공고가 없는 직무도 있었다. try except를 이용해 예외사항들은 모두 걸러주었다.
추출한 데이터를 데이터프레임 형태로 만들고 csv파일로 저장했다. 추출을 끝나고 보니 한글이 깨져있었다. UTF-8로 인코딩하면 깨진다고 한다. encoding='cp949'로 해주었다. 자꾸 수정하다보니 몇 번째 추출하는건지..
추출이 끝난 후 수정해야할 부분 수정 후에 팀원에게 넘겼다.
Day - 4 (2023. 11. 9.)
어제 만든 데이터를 토대로 시각화를 진행했다. 처음에는 직군별, 지역별, 스택 분류별로 나누어서 시각화를 진행하려 했으나 너무 세분화 되어서 데이터가 적어져 지역별은 빼기로 했다.
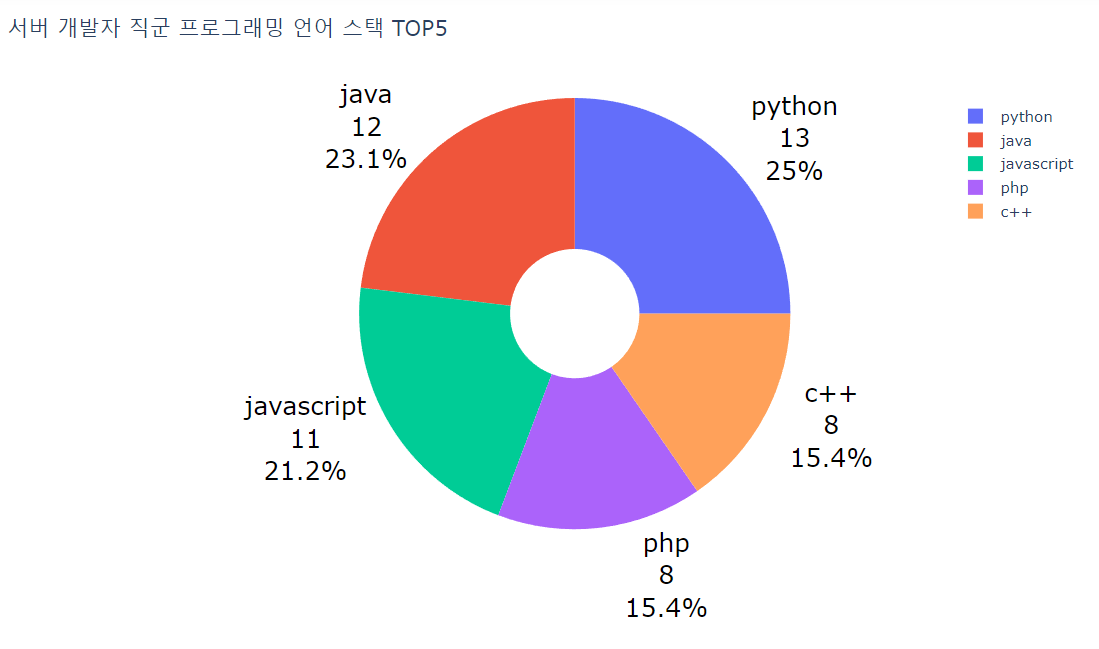
Day - 5 (2023. 11. 10.)
벌써 마지막날 이제 어느정도 마무리가 되어가고 보고서 준비단게로 넘어간다.

안녕하세요! 데브코스 관련해서 궁금한게 있는데 질문 드려도 될까요??