
📖 학습주제
ETL, ELT, Redshift, 데이터 분석/처리용 고급SQL, BI대시보드 (2)
Redshift 특징 소개
Redshift의 특징
- AWS에서 지원하는 데이터 웨어하우스 서비스
- 2 PB의 데이타까지 처리 가능
- 최소 160GB로 시작해서 점진적으로 용량 증감 가능
- Still OLAP : 큰 데이터를 처리는데 최적화
- 응답속도가 빠르지 않기 때문에 프로덕션 데이터베이스로 사용불가
- 컬럼 기반 스토리지
- 레코드 별로 저장하는 것이 아니라 컬럼별로 저장함
- 컬럼별 압축이 가능하며 컬럼을 추가하거나 삭제하는 것이 아주 빠름
- 벌크 업데이트 지원(모든 데이터 웨어하우스가 가지는 특징)
- 레코드가 들어있는 파일을 S3로 복사 후 COPY 커맨드로 Redshift로 일괄 복사
- 고정 용량/비용 SQL 엔진
- 최근 가변 비용 옵션도 제공 (Redshift Serverless)
- 데이터 공유 기능 (Datashare):
- 다른 AWS 계정과 특정 데이터 공유 가능. Snowflake의 기능을 따라함
- 다른 데이터 웨어하우스처럼 primary key uniqueness를 보장하지 않음
- 프로덕션 데이터베이스들은 보장함
- SQL 기반 관계형 데이터베이스
- Postgresql 8.x와 SQL이 호환됨(하지만 Postgresql 8.x의 모든 기능을 지원하지는 않음)- Postgresql 8.x를 지원하는 툴이나 라이브러리로 액세스 가능(JDBC/ODBC)
- 다시 한번 SQL이 메인 언어라는 점 명심(모든 데이터 웨어하우스 공통)
그래서 데이터 모델링(테이블 디자인)이 아주 중요
Redshift의 스케일링 방식
- 일반적으로 용량이 부족해질 때마다 새로운 노드를 추가하는 방식으로 스케일링(Scale Out)
- Scale Out 방식과 Scale Up 방식
e.g.) dc2.large가 하나면 최대 0.16TB까지의 용량을 갖게됨
공간이 부족해지면
- dc2.large 한대를 더 추가 -> 총 0.32TB (Scale Out)
- 아니면 사양을 더 좋은 것으로 업그레이드 -> dc2.8xlarge 한대로 교체 (Scale Up) - 이를 Resizing이라 부르며 Auto Scaling 옵션을 설정하면 자동으로 이뤄짐
-> Snowflake나 BigQuery의 방식과는 굉장히 다름
여기서는 특별히 용량이 정해져있지 않고 쿼리를 처리하기 위해 사용한 리소스에 해당하는 비용 지불
- 즉, Snowflake와 BigQuery가 훨씬 더 스케일하는 데이터베이스 기술이라 볼 수 있음
- 장단점 존재 -> 비용의 예측이 불가능하다는 단점 존재
Redshift 최적화
- Redshift 최적화는 굉장히 복잡
- Redshift가 두 대 이상의 노드로 구성되면 한 테이블의 레코드들이 다수의 노드로 어떻게 분배가 될 것인지 개발자가 지정해야 함
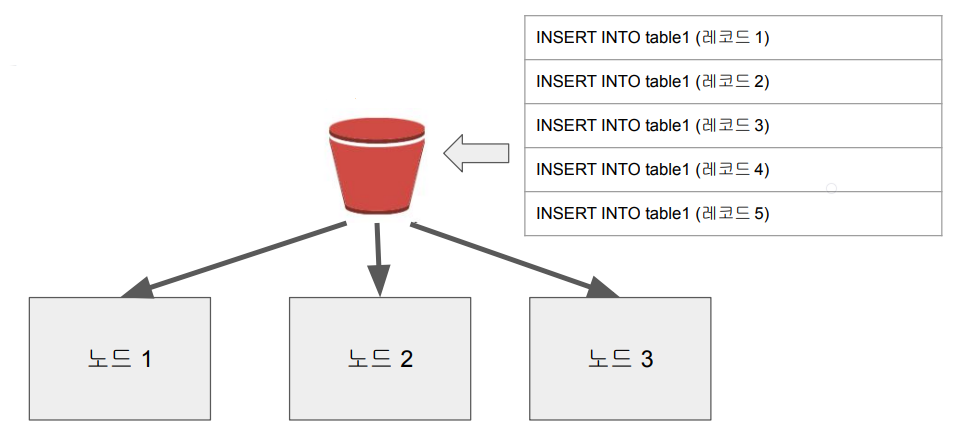
Redshift의 레코드 분배와 저장 방식
- Redshift가 두 대 이상의 노드로 구성되면 그 시점부터 테이블 최적화가 중요
- 한 테이블의 레코드들을 어떻게 다수의 노드로 분배할 것이냐?
- Distkey, Diststyle, Sortkey 세 개의 키워드를 알아야함
- Diststyle은 레코드 분배가 어떻게 이뤄지는지를 결정(디폴트는 “even”)
all : 모든 레코드들이 모든 노드에 복제
even : 노드별로 돌아가면서 레코드를 저장
key : 특정 컬럼의 값(보통 PK)을 기준으로 레코드들이 다수의 노드로 분배
- Distkey는 레코드가 어떤 컬럼을 기준으로 배포되는지 나타냄 (diststyle이 key인 경우)
- Sortkey는 레코드가 한 노드내에서 어떤 컬럼을 기준으로 정렬되는지 나타냄(이는 보통 타임스탬프 필드가 됨)
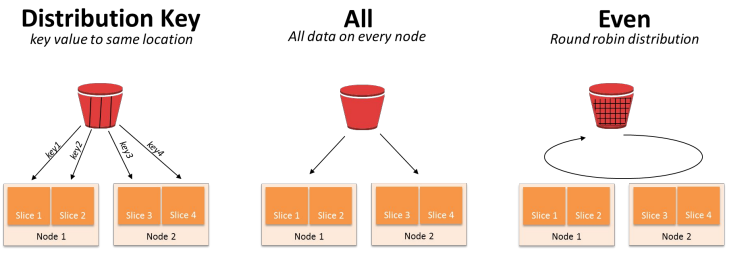
Diststyle이 key인 경우 컬럼 선택이 잘못되면?
레코드 분포에 Skew가 발생 -> 분산처리의 효율성이 사라짐
BigQuery나 Snowflake에서는 이런 속성을 개발자가 지정할 필요가 없음 (시스템이 알아서 선택)
e.g.)
CREATE TABLE my_table (
column1 INT,
column2 VARCHAR(50),
column3 TIMESTAMP,
column4 DECIMAL(18,2)
) DISTSTYLE KEY DISTKEY(column1) SORTKEY(column3);-> my_table의 레코드들은 column1의 값을 기준으로 분배되고 같은 노드(슬라이스)안에서는 column3의 값을 기준으로 소팅이 됨
Redshift의 벌크 업데이트 방식 - COPY SQL
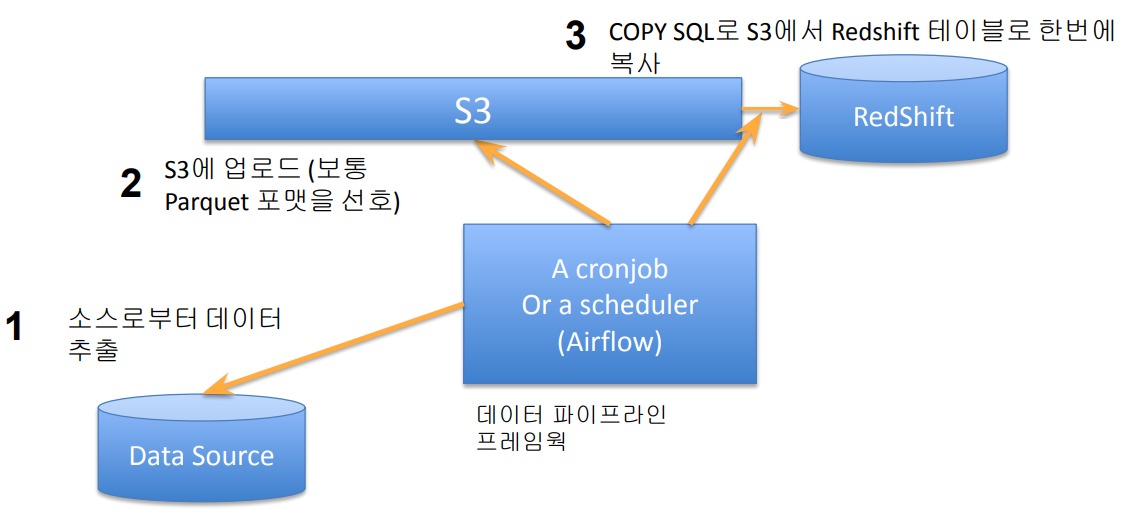
Snowflake나 BigQuery 등도 비슷한 방식을 취함
INSERT INTO : record by record로 데이터를 적재해 동시에 다수의 데이터를 적재하는 데에는 한계가 있음
Redshift의 데이터 타입
기본 데이터 타입
- SMALLINT (INT2)
- INTEGER (INT, INT4)
- BIGINT (INT8)
- DECIMAL (NUMERIC)
- REAL (FLOAT4)
- DOUBLE PRECISION (FLOAT8)
- BOOLEAN (BOOL)
- CHAR (CHARACTER)
- VARCHAR (CHARACTER VARYING)
- TEXT (VARCHAR(256))
- DATE
- TIMESTAMP
고급 데이터 타입
- GEOMETRY
- GEOGRAPHY
- HLLSKETCH
- SUPER
실습
콘솔에 RedShift를 검색해 들어간 후 Free Trial로 생성한다.
생성한 RedShift 클러스터에 Colab을 연결할 것이다. 이를 위해 Endpoint, hostname, portname, dbname 등이 필요하다.
아래에서 작업 그룹 아래에 default-workgroup을 클릭한다. 그러면 Endpoint를 확인할 수 있다.

또한 아래의 항목에서 Public Acess가 가능하도록 설정한다.
그리고 VPC 보안 그룹에서 인바운드 규칙에 포트번호 5439를 0.0.0.0/0에
오픈한다.
접속할 수 있는 계정 세팅도 해보자.
이번에는 이전 페이지에서 default-namespace를 클릭해 admin user와 password를 설정한다.
코랩에서 다음과 같이 코드를 작성해서 실행한다.
%sql postgresql://ID:PW@호스트이름:5439/devRedshift 초기 설정
Redshift Schema: 다른 기타 관계형 데이터베이스와 동일한 구조
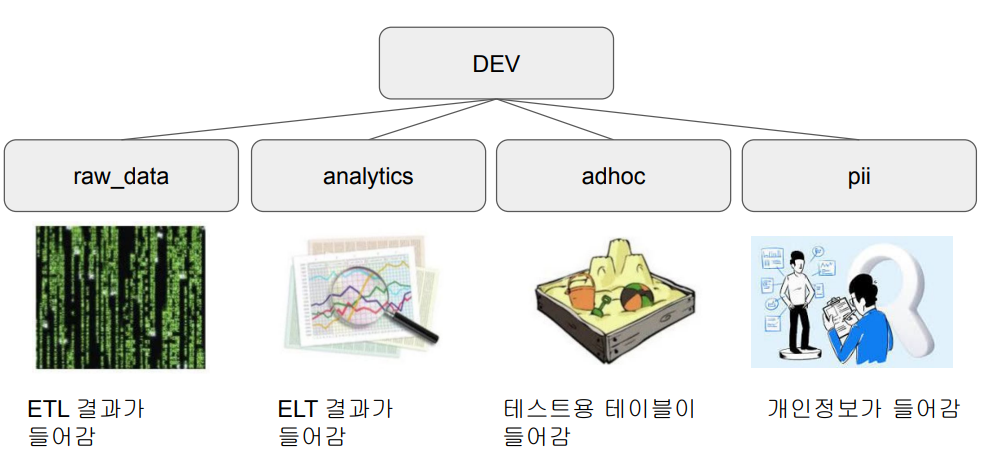
스키마(Schema) 설정
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;
CREATE SCHEMA pii;모든 스키마를 리스트하기 : select * from pg_namespace;
사용자(User) 생성
CREATE USER username PASSWORD '...';모든 사용자를 리스트하기 : select * from pg_user;
그룹(Group) 생성/설정
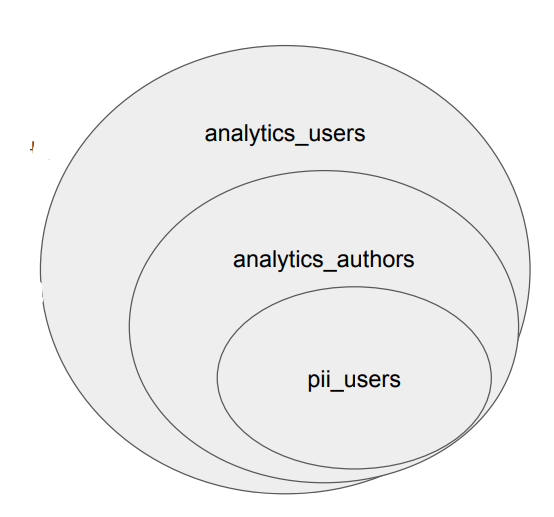
- 한 사용자는 다수의 그룹에 속할 수 있음
- 그룹의 문제는 계승이 안된다는 점
- 즉 너무 많은 그룹을 만들게 되고 관리가 힘들어짐
-
예를 들어 다음과 같은 그룹이 존재
- 어드민을 위한 pii_users
- 데이터 분석가를 위한 analytics_authors
- 데이터 활용을 하는 개인을 위한 analytics_users -
액세스 권한을 사용자별로 주는 것이 아니라 그룹을 만들어 관리해서 효과적으로 관리 할 수 있음
그룹 생성 : CREATE GROUP
그룹에 사용자 추가 : ALTER GROUP 그룹이름 ADD USER 사용자이름
그룹에 스키마/테이블 접근 권한 설정
CREATE GROUP analytics_users;
CREATE GROUP analytics_authors;
CREATE GROUP pii_users;
ALTER GROUP analytics_authors ADD USER username;
ALTER GROUP analytics_users ADD USER username;
ALTER GROUP pii_users ADD USER username;모든 그룹을 리스트하기 : select * from pg_group;
역할(Role) 생성/설정
- 역할은 그룹과 달리 계승 구조를 만들 수 있음
- 역할은 사용자에게 부여될 수도 있고 다른 역할에 부여될 수도 있음
- 한 사용자는 다수의 역할에 소속가능함
CREATE ROLE staff;
CREATE ROLE manager;
CREATE ROLE external;
GRANT ROLE staff TO username;
GRANT ROLE staff TO ROLE manager;
모든 역할을 리스트하기: select * from SVV_ROLES;
Redshift COPY 명령으로 테이블에 레코드 적재하기
COPY 명령을 사용해 raw_data 스키마 밑 3개의 테이블에 레코드를 적재해볼 예정
- 각 테이블을 CREATE TABLE 명령으로 raw_data 스키마 밑에 생성
- 이때 각 테이블의 입력이 되는 CSV 파일을 먼저 S3로 복사해야함
- 그래서 S3 버킷부터 미리 생성 (S3 웹콘솔)
- S3에서 해당 테이블로 복사를 하려면 Redshift가 S3 접근권한을 가져야함
- 먼저 Redshift가 S3를 접근할 수 있는 역할을 만들고 (IAM 웹콘솔)
- 이 역할을 Redshift 클러스터에 지정 (Redshift 웹콘솔)
raw_data 테스트 테이블 만들기
테이블 생성
- raw_data 스키마에 아래 세 테이블 만들기
- 보통 이런 테이블들은 ETL을 통해 데이터 소스에서 복사해오는 형태로 이뤄짐
CREATE TABLE raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
);
CREATE TABLE raw_data.session_timestamp (
sessionid varchar(32) primary key,
ts timestamp
);
CREATE TABLE raw_data.session_transaction (
sessionid varchar(32) primary key,
refunded boolean,
amount int
);S3 버킷 생성과 파일 업로드
Redshift의 COPY SQL을 사용해서 앞서 3개의 테이블 내용을 적재한다.
- 먼저 입력이 되는 CSV 파일들을 적당한 위치에 다운로드 받기
- user_session_channel.csv
- session_timestamp.csv
- session_transaction.csv - AWS 콘솔에서 S3 bucket 하나 만들고 거기로 업로드하기
Redshift에 S3 접근 권한 설정
- Redshift가 앞서 만든 S3 버킷을 접근할 수 있어야함
- AWS IAM(Identity and Access Management)을 이용해 이에 해당하는 역할(Role)을 만들고 이를 Redshift에 부여해야함
Redshift의 S3 접근 권한용 IAM Role 만들기
- 웹 콘솔에서 IAM 방문
- 왼쪽 메뉴에서 역할 선택
- 역할 생성을 선택하고 S3 접근 권한을 지정한 Role 생성
- AWS 서비스 선택 -> Redshift 선택
- Redshift - Customizable 선택 -> 다음 버튼 클릭
- Filter Policies 박스에서 AmazonS3FullAccess를 찾아서 왼쪽의 체크박스를 선택하고 다음 버튼을 클릭
- 이름으로 redshift.read.s3을 지정하고 최종 생성
redshift.read.s3 역할을 Redshift 클러스터에 지정
Redshift 콘솔로 돌아가 해당 클러스터의 Default Namespace를 선택하고
“보안 및 암호화” 탭 아래 “IAM 역할 관리”라는 버튼을 선택
IAM 역할 관리 박스에서 “IAM 역할 연결” 메뉴를 선택하고 앞서 만든 redshift.read.s3 권한을 지정하고 “IAM 역할 연결” 버튼을 클릭
COPY 명령을 사용해 앞서 CSV 파일들을 테이블로 복사
- 앞서 생성한 테이블로 앞서 S3로 로딩한 파일을 벌크 업데이트 수행
- 이를 위해 COPY SQL 커맨드를 사용
- COPY SQL 문법은 https://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html 참조
- CSV 파일이기에 delimiter로는 콤마(,)를 지정한다
- CSV 파일에서 문자열이 따옴표로 둘러싸인 경우 제거하기 위해 removequotes 지정
- CSV 파일의 첫번째 라인(헤더)을 무시하기 위해 “IGNOREHEADER 1”을 지정
- credentials에 앞서 Redshift에 지정한 Role을 사용. 이때 해당 Role의 ARN을 읽어와야함
COPY raw_data.user_session_channel
FROM 's3://bucket-name/file_path/file_name.csv'
credentials 'aws_iam_role=arn:aws:iam:xxxxxxx:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes;- 만일 COPY 명령 실행 중에 에러가 나면 stl_load_errors 테이블의 내용을 보고 확인한다
SELECT * FROM stl_load_errors ORDER BY starttime DESC;
analytics 테스트 테이블 만들기
analytics 스키마에 새로운 테이블 만들기
- raw_data에 있는 테이블을 조인해서 새로 만들기 (ELT)
- 간단하게는 CTAS로 가능
CREATE TABLE analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;