
📖 학습주제
ETL, ELT, Redshift, 데이터 분석/처리용 고급SQL, BI대시보드 (5)
다양한 시각화 툴 소개
시각화 툴
- 대시보드 혹은 BI(Business Intelligence)툴이라고 부르기도 함
- KPI (Key Performance Indicator), 지표, 중요한 데이터 포인트들을 데이터를 기반으로 계산/분석/표시해주는 툴
- 테이블 형태로 알아보기 쉽게 해주는 것도 시각화임
- 결정권자들로 하여금 흔히 이야기하는 데이터 기반 의사결정을 가능하게 함
- 데이터 기반 결정 (Data-Driven Decision)
- 데이터 참고 결정 (Data-Informed Decision)
- 현업 종사자들이 데이터 분석을 쉽게 할 수 있도록 해줌 : Citizen Data Analyst/Scientist(현업 팀이 데이터 팀을 거치지 않고 데이터를 분석하고 활용)
- EDA(Exploratory Data Analysis) : 데이터를 사용하기 전에 데이터 특성을 파악
시각화 툴 종류
Excel, Google Spreadsheet
- 사실상 가장 많이 쓰이는 시각화 툴
Python
- 데이터 특성 분석(EDA: Exploratory Data Analysis)에 더 적합
Looker (구글)
- 2012년 미국 캘리포니아 산타크루즈에서 시작
- LookML이 자체언어로 데이터 모델을 만드는 것으로 시작
- 내부 고객뿐만 아니라 외부 고객을 위한 대시보드 작성가능
- 고가의 라이센스 정책을 갖고 있으나 굉장히 다양한 기능 제공
Tableau (세일즈포스)
- 2002년 미국 캘리포니아 마운틴뷰에서 시작하여 2013년 상장
- 다양한 제품군 보유. 일부는 사용이 무료
- 제대로 배우려면 시간이 꽤 필요하지만 강력한 대시보드 작성가능
- Looker가 뜨기 전까지 오랫동안 마켓 리더로 군림
Mode Analytics
- 2013년에 샌프란시스코에서 창업됨(https://mode.com/)
- SQL, R, Python 등을 기반으로 데이터 분석 가능
- 조금더 테크니컬한 인력을 대상으로한 애널리틱스 기능 제공
- KPI 대시보드라기 보다는 EDA (Exploratory Data Analysis) 툴에 가까움
ReDash
- 오픈소스로 시작: https://github.com/getredash/redash
- 이를 바탕으로 서비스를 제공하는 같은 이름의 회사 존재
- Superset과 상당히 흡사
- 더 강력한 쿼리 에디터 제공하지만 사용자 권한 관련 기능은 부족
그 외
- Google Studio
- AWS Quicksight
- Power BI (마이크로소프트)
- Apache Superset (오픈소스)
Superset
- 다양한 형태의 visualization와 손쉬운 인터페이스 지원
- 대시보드 공유 지원
- 엔터프라이즈 수준의 보안과 권한 제어 기능 제공
- SQLAlchemy와 연동 : 다양한 데이터베이스 지원
- Druid.io와 연동하여 실시간 데이터의 시각화도 가능함
- API와 플러그인 아키덱처 제공으로 인한 확장성이 좋음
Superset 구조와 용어
- Flask와 React JS로 구성됨
- 기본으로 sqlite을 메타데이터 데이터베이스로 사용
- Redis를 캐싱 레이어로 사용
- SqlAlchemy가 백엔드 DB 접근에 사용됨
- Database/Dataset
- Database == 관계형 데이터베이스
- Dataset == 테이블
- Dashboard/Chart
- Dashboard는 하나 이상의 chart로 구성
Superset 설치
Docker 이용 설치 vs. Preset.io에 있는 서비스 사용
- Docker에 익숙하고 개인컴퓨터 사양이 충분히 좋다면 Docker가 더 좋음
- 이 경우는 Superset 오픈소스를 그대로 쓰는 형태
- Preset.io는 무료 Starter 플랜이 있기는 하지만 회사 이메일이 있는 경우에만 사용 가능
- Superset 오픈소스를 기반으로 변경된 버전을 사용하는 형태. 하지만 오픈소스 버전과 크게 다르지 않음
Preset 셋업
- Preset.io 방문
- Free Starter 선택하고 기타 항목 입력
- WORKSPACE 생성
- 백엔드 데이터베이스로 Redshift 선택
- Snowflake 무료시험판 사용도 무방
Superset을 Docker로 설치
Docker를 실행하고 설정 메뉴에서 Resources를 선택하고 메모리 할당 부분을 체크
- 맥에서는 6GB가 필요
- 윈도우에서는 8GB가 필요
Superset의 Docker 기반 설치 문서 참조
1. 터미널 프로그램을 실행
2. 적당한 폴더로 이동
3. Superset Github repo를 클론
git clone https://github.com/apache/superset.git
4. superset 폴더로 이동
cd superset
5. 다음 2개의 명령을 수행
docker-compose -f docker-compose-non-dev.yml pull
docker-compose -f docker-compose-non-dev.yml up
아래는 최신 버전을 다운로드. 특정 버전을 다운로드하려면 아래를 먼저 실행
git checkout 1.4.0
6. http://localhost:8088으로 웹 UI 로그인
- admin:admin 사용
실습으로 만들 대시보드
만들어 볼 두 개의 차트와 하나의 대시보드
- Database로 Redshift 사용
- 채널별 Monthly Active User 차트
- 입력 테이블(Dataset)은 analytics.user_session_summary
- Monthly Cohort 차트
- 입력 테이블(Dataset)은 analytics.cohort_summary
두 개의 차트로 하나의 대시보드 생성
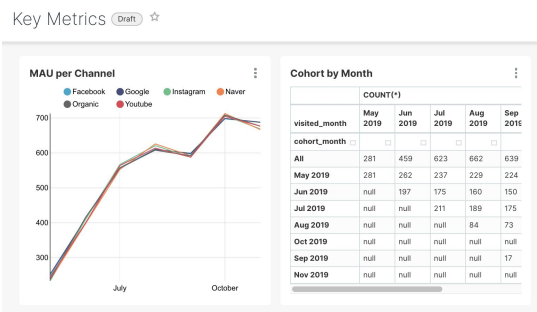
MAU 차트 입력: user_session_summary
CREATE TABLE analytics.user_session_summary AS
SELECT usc.*, t.ts
FROM raw_data.user_session_channel usc
LEFT JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionidsession 단의 완전한 정보를 갖게 만든 테이블
이를 바탕으로 시각화를 구현할 예정
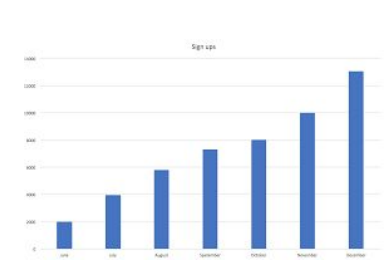
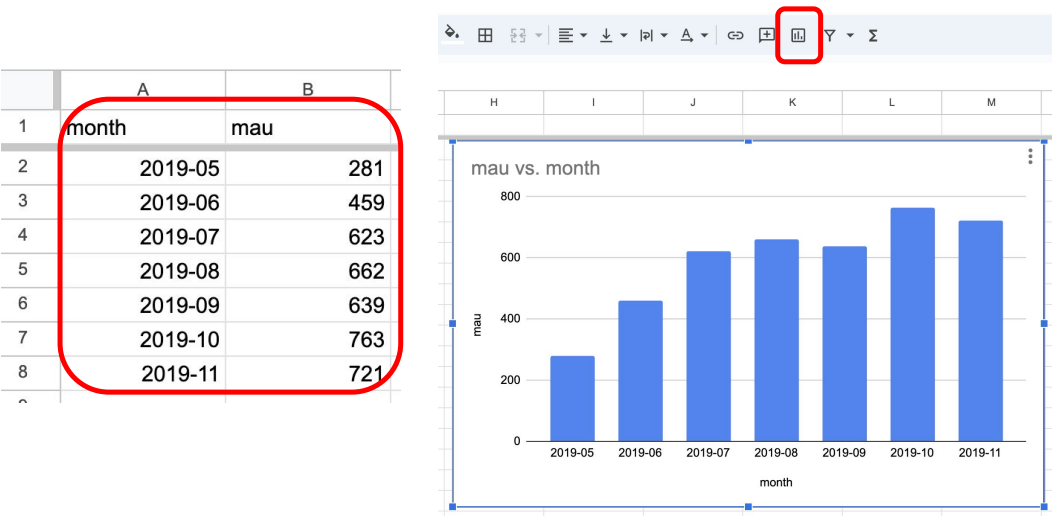
구글 스프레드시트로 해보는 MAU 시각화
SELECT
LEFT(ts, 7) "month",
COUNT(DISTINCT userid) mau
FROM analytics.user_session_summary
GROUP BY 1
ORDER BY 1;위의 내용을 다운로드 받아 mau.csv로 저장
이 파일을 Google Spreadsheet로 로딩, 이를 차트 기능을 사용해서 시각화 수행
방문한 사용자 수가 아니라 유의미한 행동을 한 사용자가 얼마나 되는지 분석 할 수 있다면 더 의미 있는 분석이 될 것이다.
코호트 분석
코호트(Cohort)
- 특정 속성을 바탕으로 나뉘어진 사용자 그룹
- 보통 속성은 사용자의 서비스 등록월
코호트 분석
- 코호트를 기반으로 다음을 계산
- 사용자의 이탈률, 잔존률, 총 소비금액 등
코호트 기반 사용자 잔존률 (Retention)
- 보통 월기반으로 시각화해서보는 것이 일반적
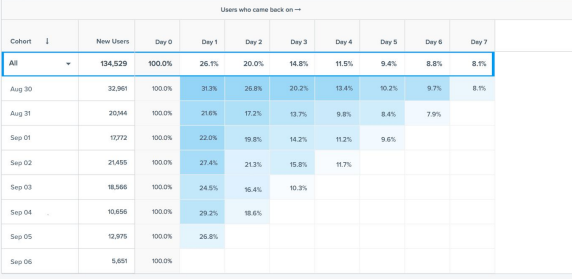
Cohort 차트 입력: cohort_summary
아래 summary 테이블을 Redshift 단에 생성
CREATE TABLE analytics.cohort_summary as
SELECT cohort_month, visited_month, cohort.userid
FROM (
SELECT userid, date_trunc('month', MIN(ts)) cohort_month
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
GROUP BY 1
) cohort
JOIN (
SELECT DISTINCT userid, date_trunc('month', ts) visited_month
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
) visit ON cohort.cohort_month <= visit.visited_month and cohort.userid = visit.userid;구글 스프레드시트로 해보는 코호트 시각화
아래 내용을 다운로드 받아서 cohort.csv로 저장
SELECT
DATEDIFF(month, cohort_month, visited_month) month,
cohort_month,
COUNT(userid) users
FROM analytics.cohort_summary
GROUP BY 1, 2
ORDER BY 1, 2;
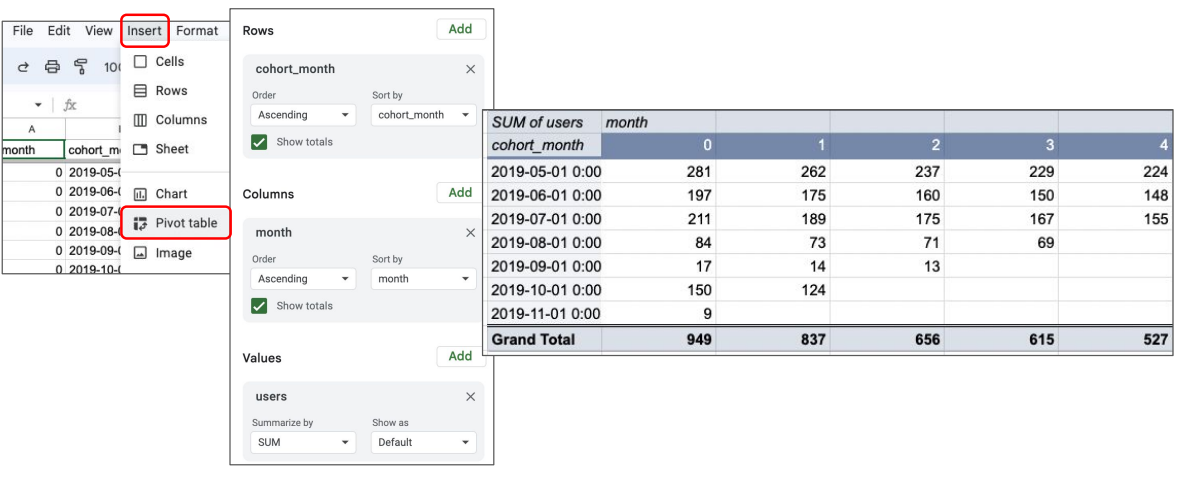
이 파일을 Google Spreadsheet로 로딩, 이를 피봇 테이블 기능을 사용해서 시각화 수행
Redshift 설정하고 MAU 차트 만들기
Database Connection 설정
우측 상단 Settings에서 Database Connections 클릭
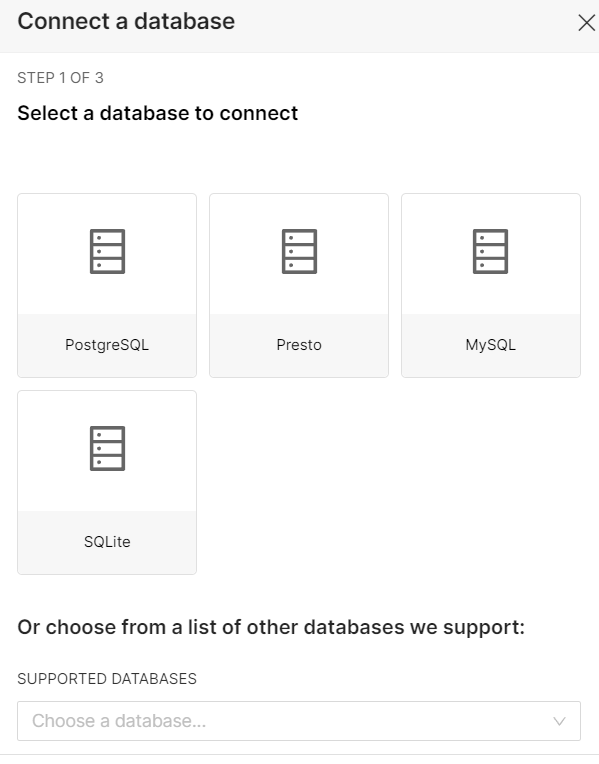
+DATABASE를 누르고 PostgreSQL 선택해서 데이터베이스 생성
user_session_summary 테이블을 Dataset으로 추가
Datasets 탭에서 +DATASET 클릭
DATABASE에서 Redshift, SCHEMA에서 analytics 선택
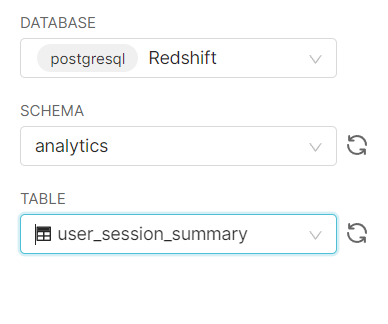
Select datbase table에서 user_session_summary 선택하고 CREATE DATASET AND CREATE CHART 실행
차트 생성: MAU
차트 유형을 선택하고 CREATE NEW CHART 클릭
다음과 같이 설정한다.
- 이름 : MAU(Monthly Active User)
- X-Axis(X축 컬럼) : ts
- Time Grain(단위) : month
- Metrics(Y축 값) : COUNT(DISTINCT userid)
- Dimension : channel
저장 후 확인
SAVE를 눌러 저장한다.
상단의 CHARTS에서 만든 차트를 확인할 수 있다.
Cohort 차트 만들고 대시보드 구성하기
위와 마찬가지로 cohort_summary 테이블을 Dataset으로 추가한다.
차트 생성
이번에는 다음과 같은 두가지 모양의 차트를 만든다.
첫번째는 특정 월에 방문한 사용자가 차례대로 그 다음 월에 얼마나 방문했는지 보여준다.
두번째는 cohort_month로 부터 특정 기간 후의 사용자 수를 보여준다.
차트 1 생성
차트 유형에서 pivot table을 선택한다.
다음과 같이 설정한다.
- 이름 : Monthly Cohort
- Columns: visited_month
- Rows: cohort_month
- Time Grain: Month
- Metrics: COUNT(*)
차트 2 생성
차트 1에서 Columns만 DATEDIFF(month, cohort_month,
visited_month)로 바꿔준다.
차트 2 저장
SAVE & GO TO NEW DASHBOARD를 선택하고 KPI Dashboard를 선택해 저장한다.
Dashboards에서 KPI Dashboard를 볼 수 있다.
KPI Dashboard에 MAU 차트 추가하기
Charts에서 MAU(Monthly Active User)를 선택해 마찬가지로 SAVE & GO TO NEW DASHBOARD 해준다.
