
📖 학습주제
데이터 파이프라인, Airflow (1)
데이터 파이프라인(ETL) 소개
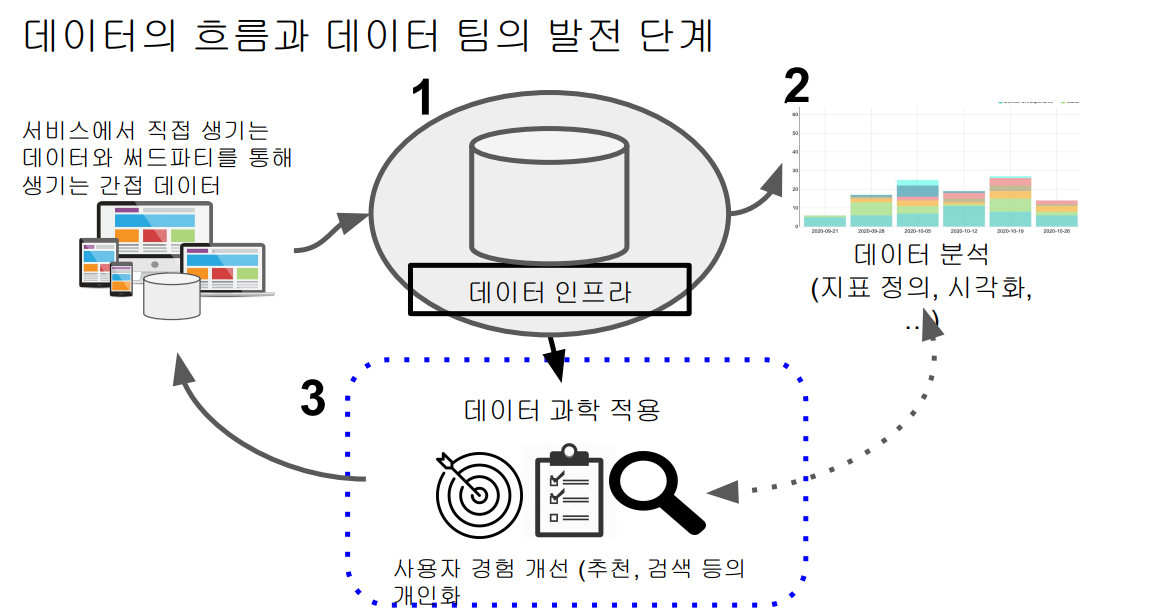
데이터의 흐름과 데이터 팀의 발전 단계
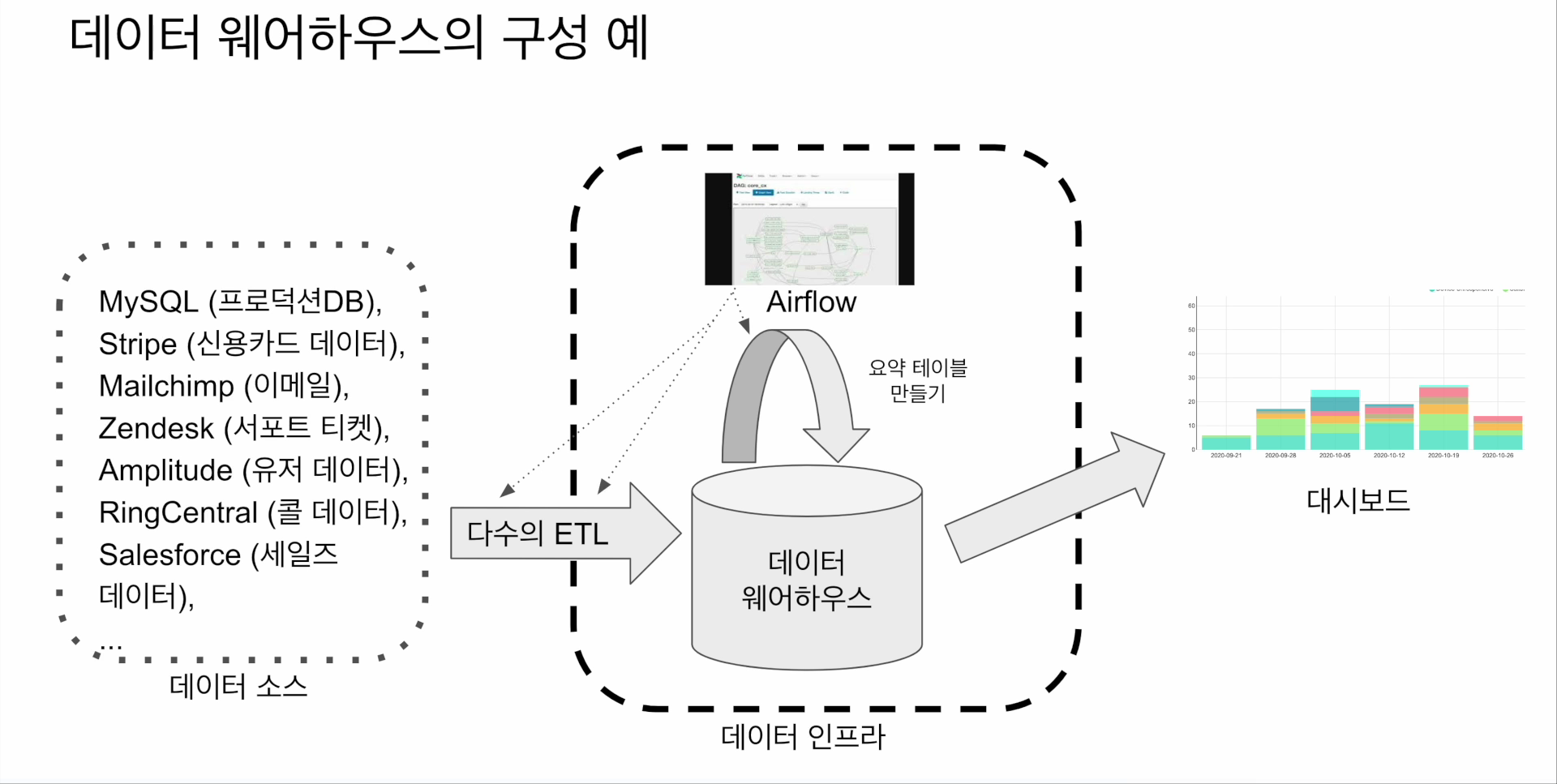
데이터 웨어하우스의 구성 예
데이터 파이프라인
ETL : Extract, Transform and Load
- Data Pipeline, ETL, Data Workflow, DAG(Airflow) 등으로도 부르기도 함
- Extract : 데이터 소스로부터 데이터를 dump
- Transform : Extract된 데이터를 원하는 format으로 변환함
- Load : 데이터 웨어하우스에 Extract,Transform한 데이터를 적재, 보통 테이블 형태로 저장됨
ELT
ETL vs ELT
- ETL: 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스
- 보통 데이터 엔지니어들이 수행함
- ELT: 데이터 웨어하우스 내부 데이터를 조작해서 (보통은 좀더 추상화되고 요약된) 새로운 데이터를 만드는 프로세스
- 보통 데이터 분석가들이 많이 수행
- 이 경우 데이터 레이크 위에서 이런 작업들이 벌어지기도 함
- 이런 프로세스 전용 기술들이 있으며 dbt(Data Build Tool)가 가장 유명(Analytics Engineering)
Data Lake vs. Data Warehouse
데이터 레이크 (Data Lake)
- 구조화 데이터 + 비구조화 데이터
- 보존 기한이 없는 모든 데이터를 원래 형태대로 보존하는 스토리지에 가까움
- 보통은 데이터 웨어하우스보다 몇배는 더 크고 싼 스토리지
데이터 웨어하우스 (Data Warehouse)
- 보존 기한이 있는 구조화된 데이터를 저장하고 처리하는 스토리지(관계형 DB)
- 단순 저장만이 아니라 처리도 함(SQL)
- 보통 BI 툴들(룩커, 태블로, 수퍼셋, …)은 데이터 웨어하우스를 백엔드로 사용함
Data Lake & ELT
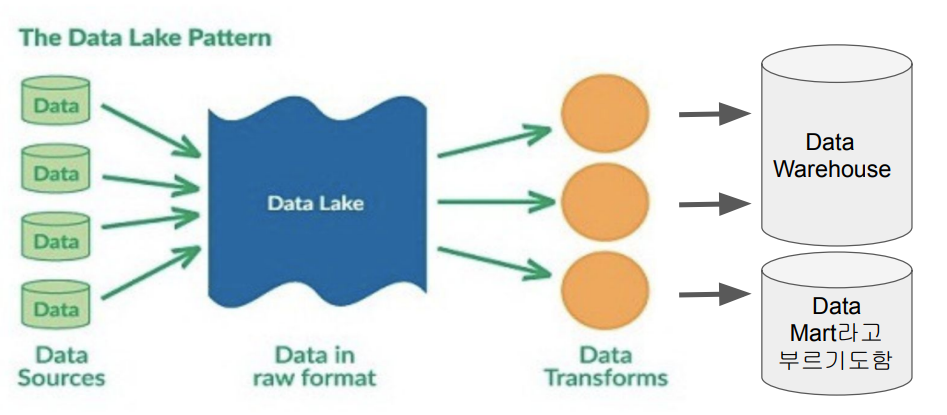
데이터 레이크에서 데이터 웨어하우스에 적재되는 과정을 크게 봤을 때 ELT라고 할 수 있음
이 때 다양한 데이터 파이프라인의 스케줄러와 관리 툴(Airflow 등)이 필요
Data Pipeline의 정의
- 데이터를 소스로부터 목적지로 복사하는 작업
- 이 작업은 보통 코딩 (파이썬 혹은 스칼라) 혹은 SQL을 통해 이뤄짐
- 대부분의 경우 목적지는 데이터 웨어하우스가 됨(종종은 외부 시스템이 되기도 함)
- 데이터 소스의 예 : Click stream, call data, ads performance data, transactions, sensor data, metadata, …
- More concrete examples: production databases, log files, API, stream data (Kafka topic)
- 데이터 목적지의 예 : 데이터 웨어하우스, 캐시 시스템 (Redis, Memcache), 프로덕션 데이터베이스, NoSQL, S3, …
데이터 파이프라인의 종류
Raw Data ETL Jobs
- 외부(회사 밖)와 내부(회사 내부)데이터 소스에서 데이터를 읽어다가 (많은 경우 API를 통하게 됨)
- 적당한 데이터 포맷 변환 후 (데이터의 크기가 커지면 Spark등이 필요해짐)
- 데이터 웨어하우스 로드
이 작업은 보통 데이터 엔지니어가 함
Summary/Report Jobs
- 데이터 웨어하우스(혹은 레이크)로부터 데이터를 읽어 다시 데이터 웨어하우스에 쓰는 ETL
- Raw Data를 읽어서 일종의 리포트 형태나 써머리 형태의 테이블을 다시
만드는 용도 - 특수한 형태로는 AB 테스트 결과를 분석하는 데이터 파이프라인도 존재
요약 테이블의 경우 SQL (CTAS를 통해)만으로 만들고 이는 데이터 분석가가 하는 것이 맞음.
데이터 엔지니어 관점에서는 어떻게 데이터 분석가들이 편하게 할 수 있는 환경을 만들어 주느냐가 관건
-> Analytics Engineer (DBT)
Production Data Jobs
-
DW로부터 데이터를 읽어 다른 Storage(많은 경우 프로덕션 환경)로 쓰는 ETL
- 써머리 정보가 프로덕션 환경에서 성능 이유로 필요한 경우
- 혹은 머신러닝 모델에서 필요한 피쳐들을 미리 계산해두는 경우 -
이 경우 흔한 타켓 스토리지
- Cassandra/HBase/DynamoDB와 같은 NoSQL
- MySQL과 같은 관계형 데이터베이스 (OLTP)
- Redis/Memcache와 같은 캐시
- ElasticSearch와 같은 검색엔진
데이터 파이프라인을 만들 때 고려할 점
이상과 현실간의 괴리
이상
- 내가 만든 데이터 파이프라인은 문제 없이 동작할 것이다.
- 내가 만든 데이터 파이프라인을 관리하는 것은 어렵지 않을 것이다.
현실
- 데이터 파이프라인은 많은 이유로 실패함
- 버그
- 데이터 소스상의 이슈 : What if data sources are not available or change its data format
- 데이터 파이프라인들간의 의존도에 이해도 부족
- 데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
- 데이터 소스간의 의존도가 생기면서 이는 더 복잡해짐. 만일 마케팅 채널 정보가 업데이트가 안된다면 마케팅 관련 다른 모든 정보들이 갱신되지 않음
- More tables needs to be managed (source of truth, search cost, …)
Best Practices
Full Refresh
- 가능하면 데이터가 작을 경우 매번 통채로 복사해서 테이블을 만들기
- Incremental update만이 가능하다면, 대상 데이터소스가 갖춰야할 몇 가지 조건이 있음
- 데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요
created (데이터 업데이트 관점에서 필요하지는 않음)
modified
deleted
- 데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야 함
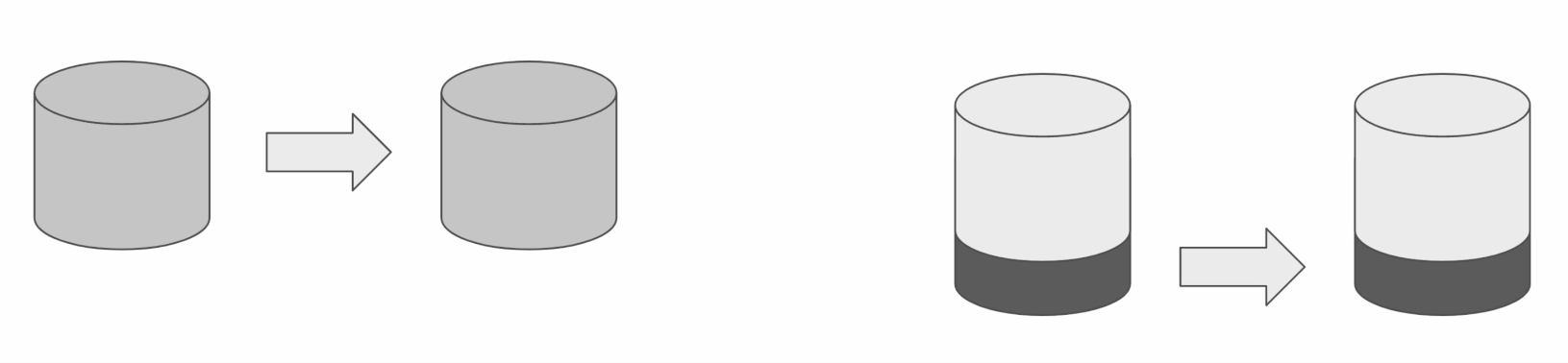
멱등성(Idempotency) 보장이 중요
- 멱등성
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함 (e.g.) 중복데이터가 생성되지 않아야 함)
- 중요한 포인트는 critical point들이 모두 one atomic action으로 실행이 되어야 한다는 것 (SQL의 transaction이 꼭 필요한 기술)
- 데이터 파이프라인이 문제가 있는 경우 데이터 정합성이 깨지지 않는 형태로 깔끔하게 실패해야 함
Backfill
- 실패한 데이터 파이프라인을 재실행이 쉬워야 함
- 과거 데이터를 다시 채우는 과정(Backfill)이 쉬워야 함
- Airflow는 이 부분(특히 backfill)에 강점을 갖고 있음
데이터 파이프라인의 입력과 출력을 명확히 하고 문서화
- 비지니스 오너 명시 : 누가 이 데이터를 요청했는지를 기록으로 남길 것
(vs 테크니컬 오너 : 코드를 작성하고 유지, 보수하는 데이터 엔지니어 중 한 사람)
- 이것이 나중에 데이터 카탈로그로 들어가서 데이터 디스커버리에 사용 가능함
- 데이터 리니지가 중요해짐 -> 이걸 이해하지 못하면 온갖 종류의 사고 발생
주기적으로 쓸모없는 데이터들을 삭제
- Kill unused tables and data pipelines proactively
- Retain only necessary data in Data Warehouse and move past data to Data Lake (or storage)
데이터 파이프라인 사고시 마다 사고 리포트(post-mortem) 쓰기
- 목적은 동일한 혹은 아주 비슷한 사고가 또 발생하는 것을 막기 위함
- 사고 원인(root-cause)을 이해하고 이를 방지하기 위한 액션 아이템들의 실행이 중요해짐
- 기술 부채의 정도를 이야기해주는 바로미터
중요 데이터 파이프라인의 입력과 출력을 체크하기 : 데이터 대상 유닛 테스트
- 아주 간단하게 입력 레코드의 수와 출력 레코드의 수가 몇개인지 체크하는 것부터 시작
- 써머리 테이블을 만들어내고 Primary key가 존재한다면 Primary key uniqueness가 보장되는지 체크하는 것이 필요함
- 중복 레코드 체크
Airflow 소개
- 파이썬으로 작성된 데이터 파이프라인 (ETL) 프레임워크
- Airbnb에서 시작한 아파치 오픈소스 프로젝트
- 가장 많이 사용되는 데이터 파이프라인 관리/작성 프레임워크
- 데이터 파이프라인 스케줄링 지원
- 정해진 시간에 ETL 실행 혹은 한 ETL의 실행이 끝나면 다음 ETL 실행
- 웹 UI를 제공하기도 함
- 데이터 파이프라인(ETL)을 쉽게 만들 수 있도록 해줌
- 다양한 데이터 소스와 데이터 웨어하우스를 쉽게 통합해주는 모듈 제공
https://airflow.apache.org/docs/
- 데이터 파이프라인 관리 관련 다양한 기능을 제공해줌 (특히 Backfill)
- Airflow에서는 데이터 파이프라인을 DAG(Directed Acyclic Graph)라고 부름
- 하나의 DAG는 하나 이상의 태스크로 구성됨
- Airflow 버전 선택 방법 : 큰 회사에서 사용하는 버전이 무엇인지 확인
https://cloud.google.com/composer/docs/concepts/versioning/composer-versions
Airflow 구성
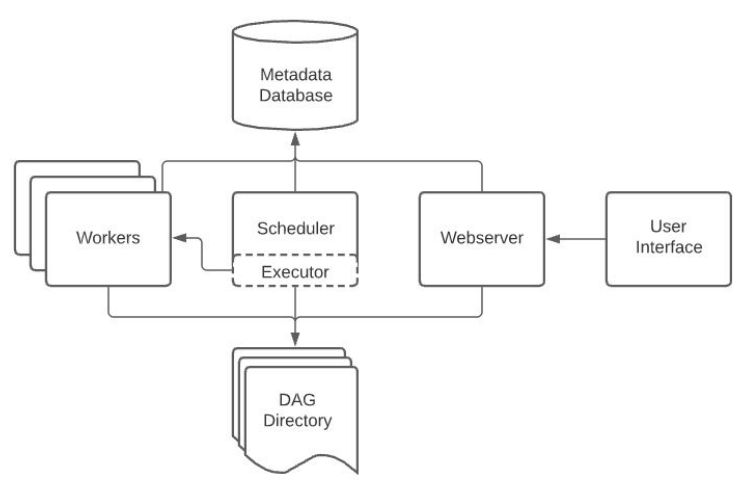
총 5개의 컴포넌트로 구성
- 웹 서버 (Web Server)
- 스케줄러 (Scheduler) : DAG들을 워커들에게 배정하는 역할을 수행(Executor를 통해 수행)
- 워커 (Worker) : 실제로 DAG를 실행하는 역할을 수행
- 메타 데이터 데이터베이스 : Sqlite가 기본으로 설치됨
- 큐 (다수서버 구성인 경우에만 사용됨)
-이 경우 Executor가 달라짐
웹 UI는 스케줄러와 DAG의 실행 상황을 시각화해줌
스케줄러와 각 DAG의 실행결과는 별도 DB에 저장됨
-> 기본으로 설치되는 DB는 SQLite, 실제 프로덕션에서는 MySQL이나 Postgres를 사용해야함
Executor 종류
- Sequential Executor : Default (SQLite하고만 작동)
- Local Executor
- Celery Executor
- Kubernetes Executor
- CeleryKubernetes Executor
- Dask Executor
Airflow 구조 : 서버 한대
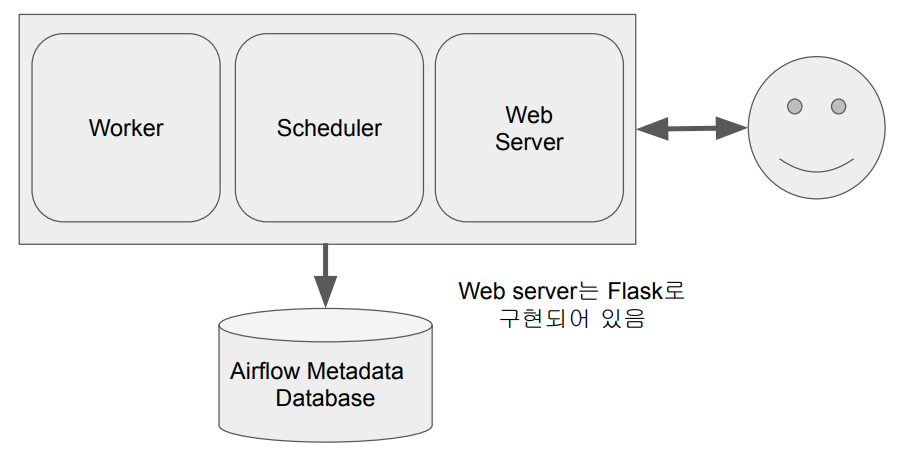
워커의 수 : 최대 웹 서버가 가지고 있는 CPU의 수까지
Airflow 스케일링 방법
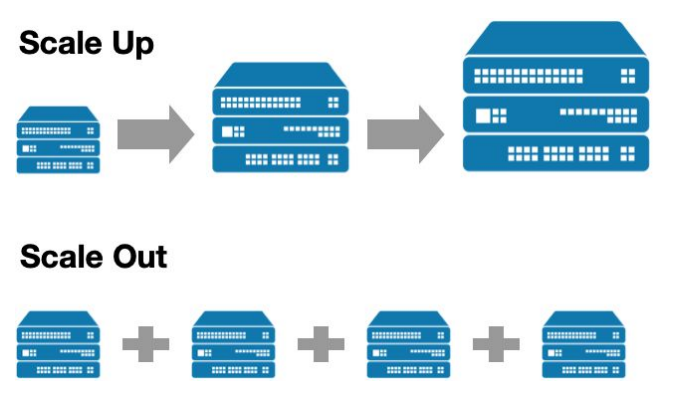
- 스케일 업 (더 좋은 사양의 서버 사용)
- 스케일 아웃 (서버 추가) : 늘어나는 서버는 워커 용도로 사용됨
Airflow 구조 : 다수 서버
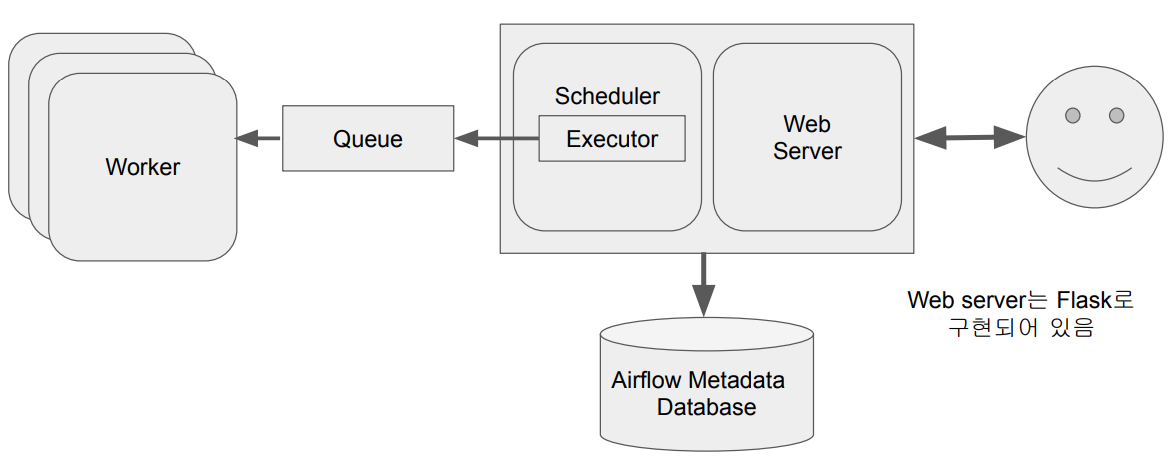
Airflow 개발의 장단점
장점
- 데이터 파이프라인을 세밀하게 제어 가능
- 다양한 데이터 소스와 데이터 웨어하우스를 지원
- 백필(Backfill)이 쉬움
단점
- 배우기가 쉽지 않음
- 상대적으로 개발환경을 구성하기가 쉽지 않음
- 직접 운영이 쉽지 않음. 클라우드 버전 사용이 선호됨
- GCP provides “Cloud Composer”
- AWS provides “Managed Workflows for Apache Airflow”
- Azure provides “Data Factory Managed Airflow”
DAG
- Directed Acyclic Graph의 줄임말
- Airflow에서 ETL을 부르는 명칭
- DAG는 태스크로 구성됨
- 예를 3개의 태스크로 구성된다면 Extract, Transform, Load로 구성
태스크
- Airflow의 오퍼레이터(Operator)로 만들어짐
- Airflow에서 이미 다양한 종류의 오퍼레이터를 제공함
- 경우에 맞게 사용 오퍼레이터를 결정하거나 필요하다면 직접 개발
- Redshift writing, Postgres query, S3 Read/Write, Hive query, Spark job, shell script, …
DAG의 구성 예 : 3개의 Task로 구성된 DAG
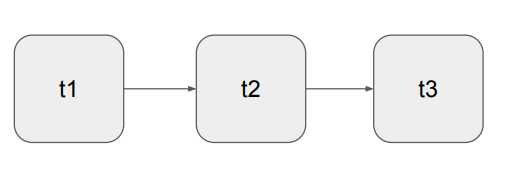
먼저 t1이 실행되고 t2, t3의 순으로 일렬로 실행
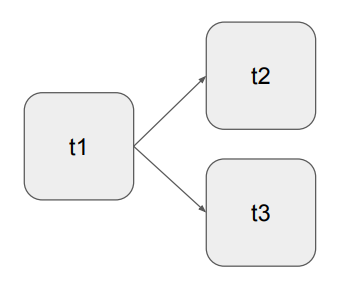
먼저 t1이 실행되고 여기서 t2와 t3로 분기

.