
📖 학습주제
데이터 파이프라인, Airflow (5)
MySQL 테이블 복사하기
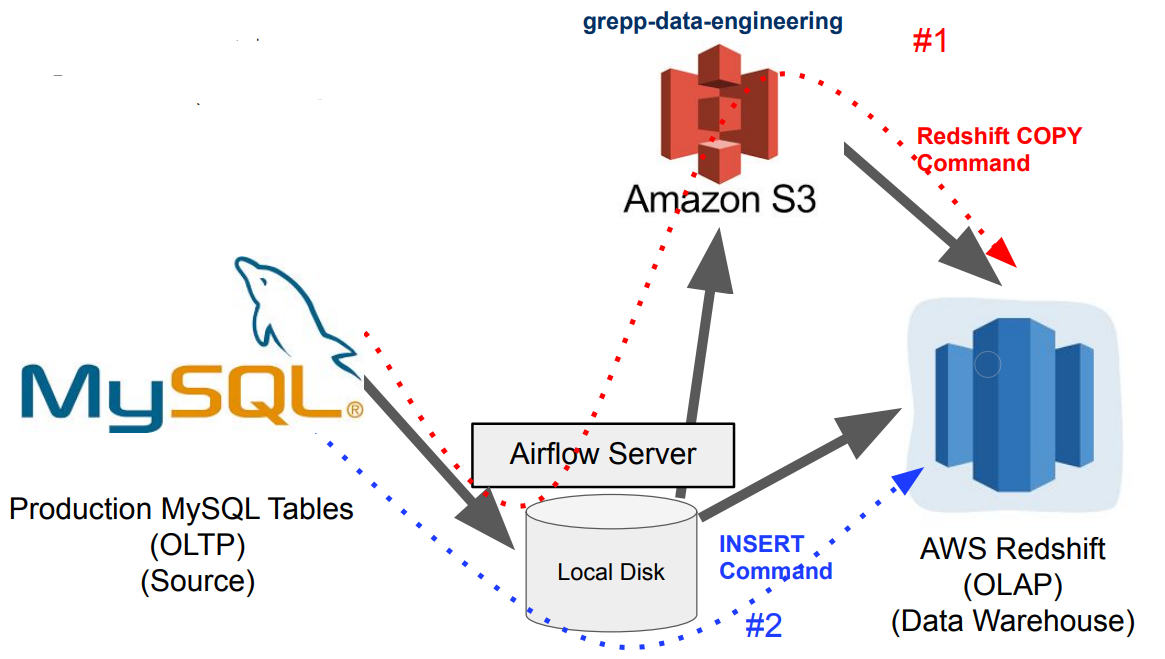
AWS 관련 권한 설정
Airflow DAG에서 S3 접근 (쓰기 권한)
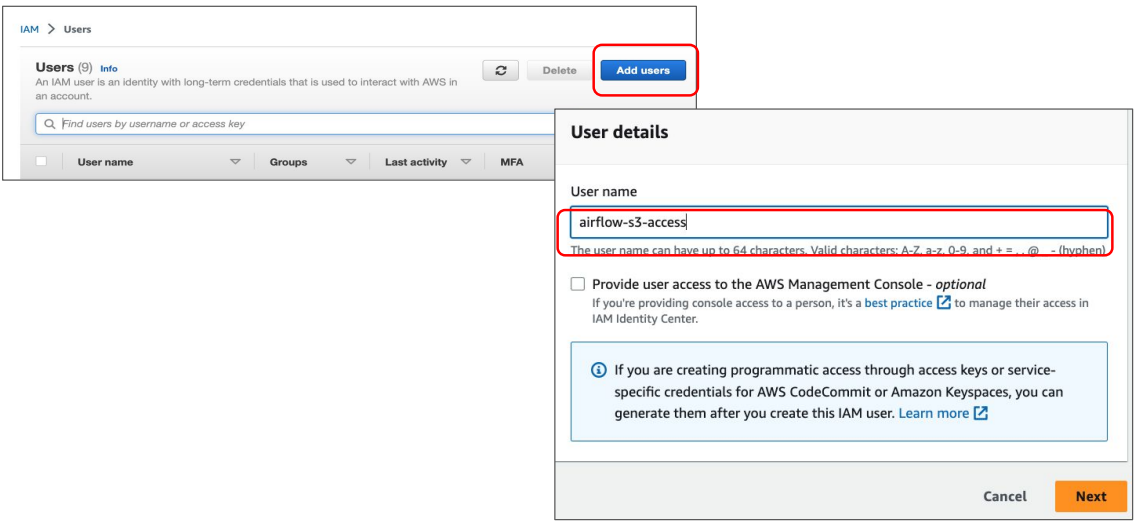
- IAM User를 만들고 S3 버킷에 대한 읽기/쓰기 권한 설정하고 access key와 secret key를 사용
Redshift가 S3 접근 (읽기 권한)
- Redshift에 S3를 접근할 수 있는 역할 (Role)을 만들고 이를 Redshift에 지정
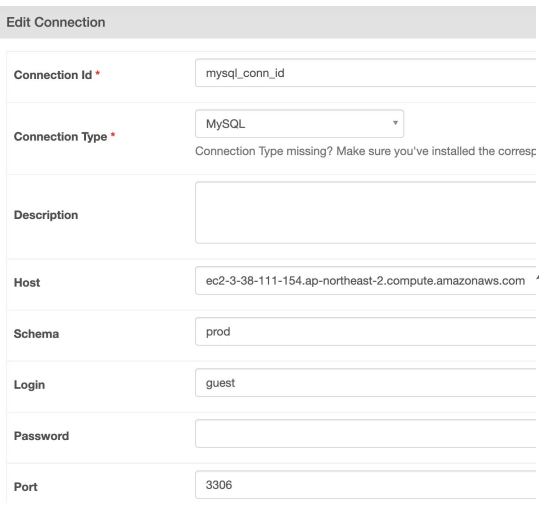
MySQL Connection 확인
IAM 사용자 설정
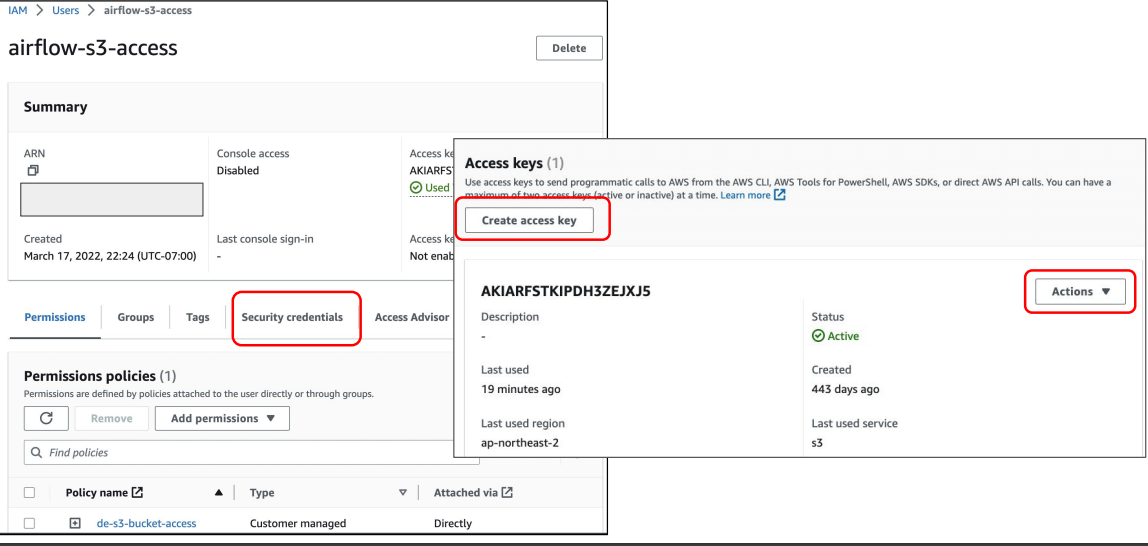
S3 Connection 설정
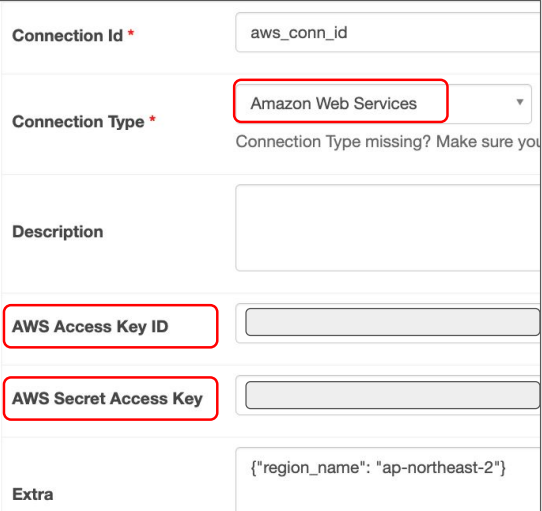
앞서 만든 IAM 사용자의 Access Key ID와 Secret Access Key를 사용
Redshift(OLAP, Data Warehouse)에 해당 테이블 생성
CREATE TABLE (본인의스키마).nps (
id INT NOT NULL primary key,
created_at timestamp,
score smallint
);
MySQL_to_Redshift DAG의 Task 구성
SqlToS3Operator
- MySQL SQL 결과 -> S3
- s3://s3_bucket/s3_key
S3ToRedshiftOperator
- S3 -> Redshift 테이블
- (s3://s3_bucket/s3_key) -> Redshift (본인스키마.nps)
- COPY command is used
코드
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
import json
dag = DAG(
dag_id = 'MySQL_to_Redshift',
start_date = datetime(2022,8,24), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 9 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
schema = "trick"
table = "nps"
s3_bucket = "grepp-data-engineering"
s3_key = schema + "-" + table
mysql_to_s3_nps = SqlToS3Operator(
task_id = 'mysql_to_s3_nps',
query = "SELECT * FROM prod.nps",
s3_bucket = s3_bucket,
s3_key = s3_key,
sql_conn_id = "mysql_conn_id",
aws_conn_id = "aws_conn_id",
verify = False,
replace = True,
pd_kwargs={"index": False, "header": False},
dag = dag
)
s3_to_redshift_nps = S3ToRedshiftOperator(
task_id = 's3_to_redshift_nps',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = schema,
table = table,
copy_options=['csv'],
method = 'REPLACE',
redshift_conn_id = "redshift_dev_db",
aws_conn_id = "aws_conn_id",
dag = dag
)
mysql_to_s3_nps >> s3_to_redshift_npsMySQL 테이블의 Incremental Update 방식
ROW_NUMBER로 직접 구현하는 경우
- 먼저 Redshift의 A 테이블의 내용을 temp_A로 복사
- MySQL의 A 테이블의 레코드 중 modified의 날짜가 지난 일 (execution_date)에 해당하는 모든 레코드를 읽어다가 temp_A로 복사
- 아래는 MySQL에 보내는 쿼리. 결과를 파일로 저장한 후 S3로 업로드하고 COPY 수행 - SELECT * FROM A WHERE DATE(modified) = DATE(execution_date)
- temp_A의 레코드들을 primary key를 기준으로 파티션한 다음에 modified 값을 기준으로 DESC 정렬해서, 일련번호가 1인 것들만 다시 A로 복사
S3ToRedshiftOperator로 구현하는 경우
- query 파라미터로 아래를 지정
- SELECT * FROM A WHERE DATE(modified) = DATE(execution_date) - method 파라미터로 “UPSERT”를 지정
- upsert_keys 파라미터로 Primary key를 지정
코드
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
import json
dag = DAG(
dag_id = 'MySQL_to_Redshift_v2',
start_date = datetime(2023,1,1), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 9 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
schema = "trick"
table = "nps"
s3_bucket = "grepp-data-engineering"
s3_key = schema + "-" + table # s3_key = schema + "/" + table
sql = "SELECT * FROM prod.nps WHERE DATE(created_at) = DATE('{{ execution_date }}')"
print(sql)
mysql_to_s3_nps = SqlToS3Operator(
task_id = 'mysql_to_s3_nps',
query = sql,
s3_bucket = s3_bucket,
s3_key = s3_key,
sql_conn_id = "mysql_conn_id",
aws_conn_id = "aws_conn_id",
verify = False,
replace = True,
pd_kwargs={"index": False, "header": False},
dag = dag
)
s3_to_redshift_nps = S3ToRedshiftOperator(
task_id = 's3_to_redshift_nps',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = schema,
table = table,
copy_options=['csv'],
redshift_conn_id = "redshift_dev_db",
aws_conn_id = "aws_conn_id",
method = "UPSERT",
upsert_keys = ["id"],
dag = dag
)
mysql_to_s3_nps >> s3_to_redshift_nps
.