
📖 학습주제
DBT 소개, 데이터 디스커버리, 툴 학습 (1)
프로덕션 사용을 위한 Airflow 환경설정
알아야 할 것
airflow.cfgis in/var/lib/airflow/airflow.cfg
- Any changes here will be reflected when you restart the webserver and scheduler
- [core] 섹션의 dags_folder가 DAG들이 있는 디렉토리가 되어야함 :/var/lib/airflow/dags
- dag_dir_list_interval: dags_folder를 Airflow가 얼마나 자주 스캔하는지 명시 (초 단위)
- Airflow Database upgrade
- Sqlite -> Postgres or MySQL (이 DB는 주기적으로 백업되어야함)
-sql_alchemy_conn in Core section of airflow.cfg
- SequentialExecutor 사용 (Sqlite 사용시에만)
- 다른거 사용시 LocalExecutor or CeleryExecutor- Airflow에 다수의 worker를 사용시 CeleryExecutor or KubernetesExecutor (LocalExecutor x)
- Enable Authentication & use a strong password
- In Airflow 2.0, authentication is ON by default
- 되도록이면VPN (Virtual Private Network) 뒤에 위치
- Large disk volume for logs and local data
- Logs ->/dev/airflow/logs in (Core section of airflow.cfg)
◦ base_log_folder
◦ child_process_log_directory
- Local data ->/dev/airflow/data
- Periodic Log data cleanup
- 위의 폴더들을 주기적으로 삭제 (아니면 S3와 같은 클라우드 스토리지로 복사)
- You can write a shell Operator based DAG for this purpose
- 용량부족시 From Scale Up 우선, 이후에 Scale Out
- Go for Cloud Airflow options (Cloud Composer or MWAA) or Docker/K8s - 주기적으로 Airflow metadata database 백업할 것
- Backup variables and connections (command lines or APIs) <- 중요
◦ airflow variables export variables.json
◦ airflow connections export connections.json
- health-check monitoring 추가
- https://airflow.apache.org/docs/apache-airflow/stable/logging-monitoring/check-health.html
◦ API를 먼저 활성화하고 Health Check Endpoint API를 모니터링 툴과 연동
- 어느 정도 규모가 된다면 DataDog, Grafana등을 사용하는 것이 일반적 (DevOps팀과 협업)
Airflow 로그 파일 삭제하기
Airflow 로그 위치
- 두 군데(base_log_folder, child_process_log_directory)에 별도의 로그가 기록됨. 이를 주기적으로 삭제하거나 백업 (s3) 필요
# The folder where airflow should store its log files
# This path must be absolute
base_log_folder = /var/lib/airflow/logs
[scheduler]
child_process_log_directory = /var/lib/airflow/logs/scheduler- docker compose로 실행된 경우 logs 폴더가 host volume의 형태로 유지
Airflow 메타데이터 백업하기
- Airflow 메타데이터의 주기적인 백업이 필요함
- 이 데이터베이스가 외부에 있다면 (특히 AWS RDS라면), 거기에 바로 주기적인 백업 셋업
- Airflow와 같은 서버에 메타 데이터 DB가 있다면 (예를 들어 PostgreSQL), DAG등을 이용해 주기 백업 실행 (S3로 저장)
Airflow 대안
Airflow 이외의 다른 데이터 파이프라인 프레임워크
Prefect
- Open-Source
- Airflow와 상당히 흡사하며 좀 더 경량화된 버전
- 데이터 파이프라인을 동적으로 생성할 수 있는 강점이 있음
Dagster
- Open Source
- 데이터 파이프라인과 데이터를 동시 관리
Airbyte
- Open-Source
- 코딩 툴이라기 보다는 Low-Code 툴에 가까움
SaaS 형태의 데이터 통합 툴들
- FiveTran
- Stitch Data
- Segment
ELT의 미래 : 데이터 품질의 중요성 증대
- 입출력 체크
- 더 다양한 품질 검사
- 리니지 체크
- 데이터 히스토리 파악
- 데이터 품질 유지 -> 비용/노력 감소와 생산성 증대의 지름길
Database Normalization
Database Normalization
- 데이터베이스를 좀더 조직적이고 일관된 방법으로 디자인하려는 방법
- 데이터베이스 정합성을 쉽게 유지하고 레코드들을 수정/적재/삭제를 용이하게 하는 것 - Normalization에 사용되는 개념
- Primary Key
- Composite Key
- Foreign Key
1NF (First Normal Form)
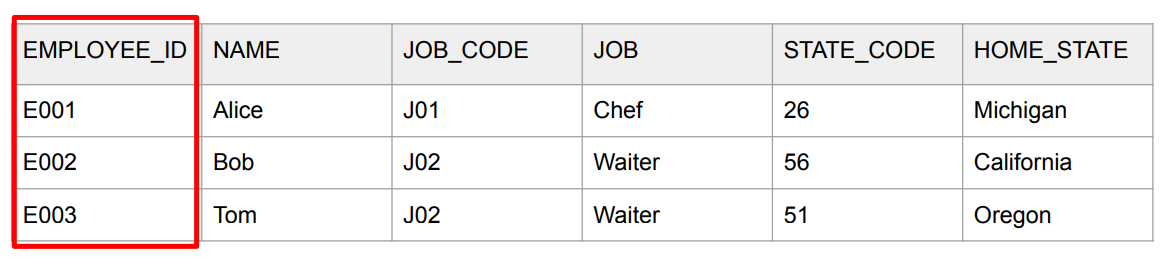
- 한 셀에는 하나의 값만 있어야함 (atomicity)
- Primary Key가 있어야함
- 중복된 키나 레코드들이 없어야함
2NF (Second Normal Form)
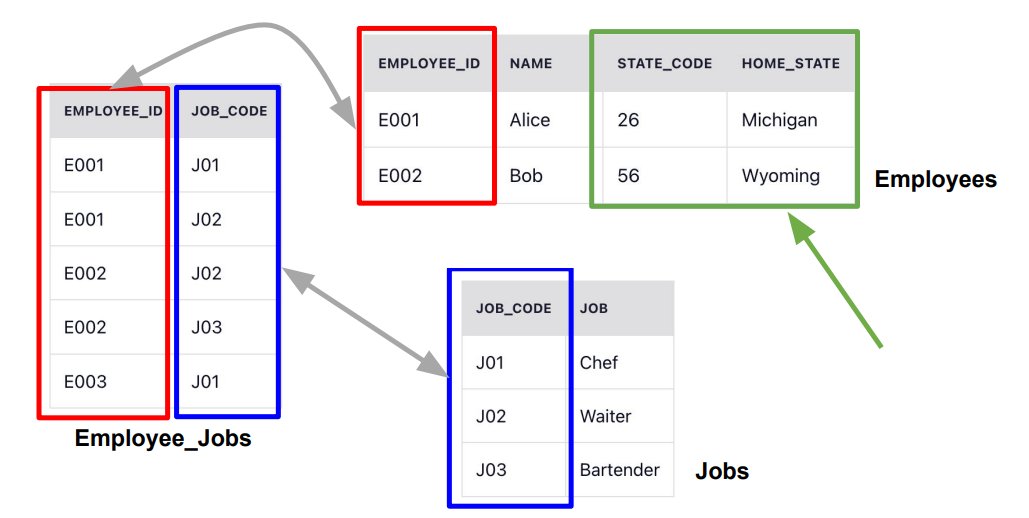
- 1NF를 만족
- 다음으로 Primary Key를 중심으로 의존결과를 알 수 있어야함
- 부분적인 의존도가 없어야함
- 모든 부가 속성들은 Primary key를 가지고 찾을 수 있어야함
- That is, all non-key attributes are fully dependent on a primary key
3NF (Third Normal Form)
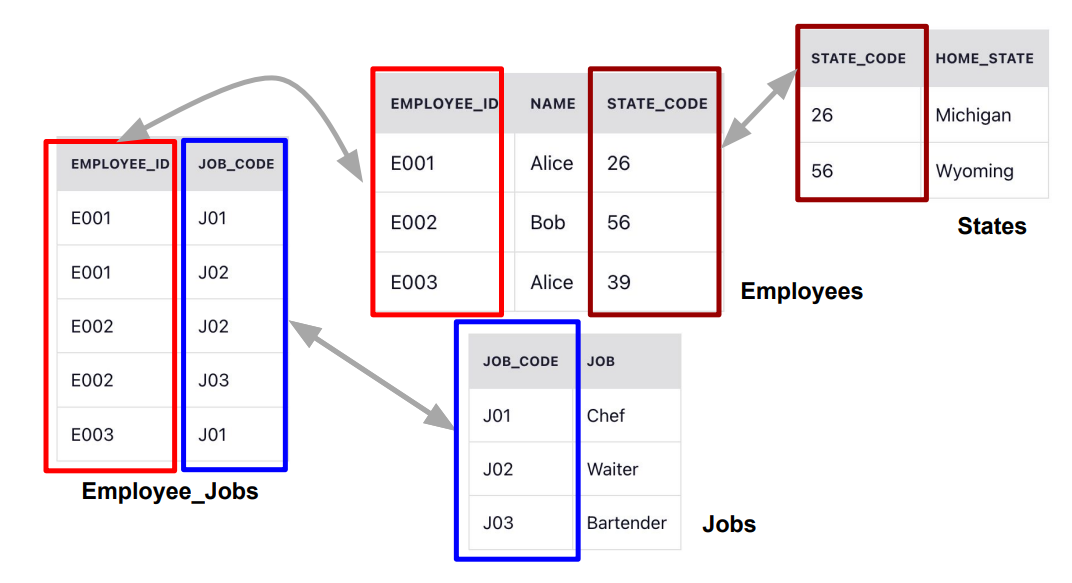
- 2NF를 만족
- 전이적 부분 종속성을 없어야함
- 2NF의 예에서 state_code과 home_state가 같이 Employees 테이블에 존재
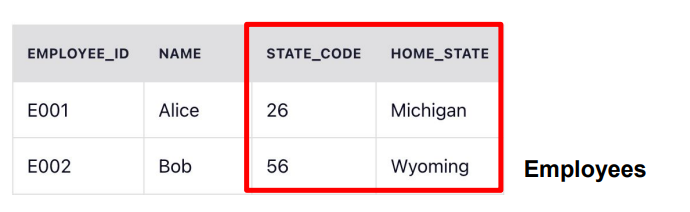
Slowly Changing Dimensions
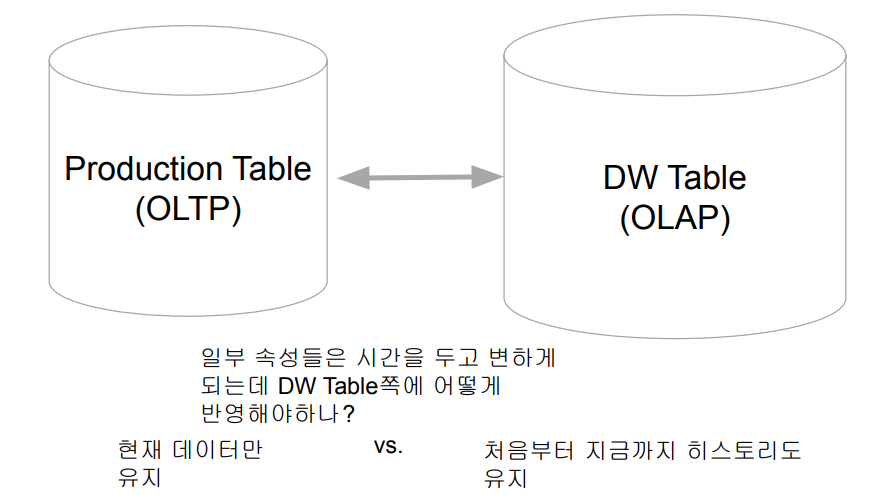
- DW나 DL에서는 모든 테이블들의 히스토리를 유지하는 것이 중요함
- 보통 두 개의 timestamp 필드를 갖는 것이 좋음
◦ created_at (생성시간으로 한번 만들어지면 고정됨)
◦ updated_at (꼭 필요 마지막 수정 시간을 나타냄) - 이 경우 컬럼의 성격에 따라 어떻게 유지할지 방법이 달라짐
SCD Type 0
- 한번 쓰고 나면 바꿀 이유가 없는 경우들
- 한번 정해지면 갱신되지 않고 고정되는 필드들
e.g.) 고객 테이블이라면 회원 등록일, 제품 첫 구매일
SCD Type 1
- 데이터가 새로 생기면 덮어쓰면 되는 컬럼들
- 처음 레코드 생성시에는 존재하지 않았지만 나중에 생기면서 채우는
경우
e.g.) 고객 테이블이라면 연간소득 필드
SCD Type 2
- 특정 entity에 대한 데이터가 새로운 레코드로 추가되어야 하는 경우
e.g.) 고객 테이블에서 고객의 등급 변화
- tier라는 컬럼의 값이 “regular”에서 “vip”로 변화하는 경우 변경시간도 같이 추가되어야함

SCD Type 3
- SCD Type 2의 대안으로 특정 entity 데이터가 새로운 컬럼으로 추가되는 경우
e.g.) 고객 테이블에서 tier라는 컬럼의 값이 “regular”에서 “vip”로 변화하는 경우
- previous_tier라는 컬럼 생성
- 변경시간도 별도 컬럼으로 존재해야함
SCD Type 4
- 특정 entity에 대한 데이터를 새로운 Dimension 테이블에 저장하는 경우
- SCD Type 2의 변종
e.g.) 별도의 테이블로 저장하고 이 경우 아예 일반화할 수도 있음
dbt(Data Build Tool)
dbt
- Data Build Tool (https://www.getdbt.com/)
- ELT용 오픈소스 : In-warehouse data transformation - 다양한 데이터 웨어하우스를 지원
- Redshift, Snowflake, Bigquery, Spark - 클라우드 버전도 존재
- dbt Cloud
dbt가 서포트해주는 데이터 시스템
https://docs.getdbt.com/docs/supported-data-platforms
dbt 구성 컴포넌트
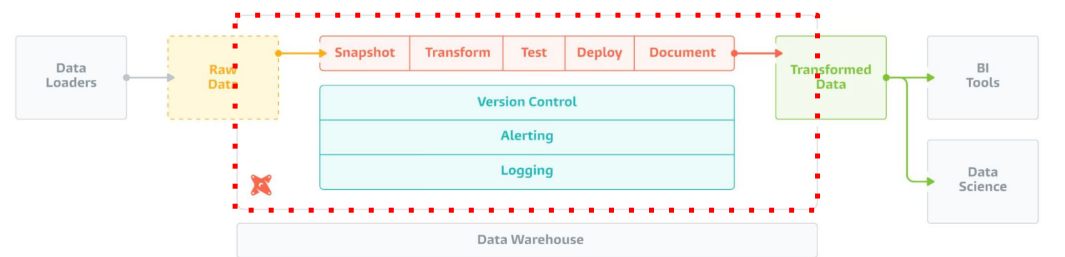
- 데이터 모델 (models) : 테이블들을 몇개의 티어로 관리
- 일종의 CTAS (SELECT 문들), Lineage 트래킹 - Table, View, CTE 등등
- 데이터 품질 검증 (tests)
- 스냅샷 (snapshots)
dbt 사용 시나리오
다음과 같은 요구조건 달성이 필요할 때
- 데이터 변경 사항을 이해하기 쉽고 필요하다면 롤백 가능
- 데이터간 리니지 확인 가능
- 데이터 품질 테스트 및 에러 보고
- Fact 테이블의 증분 로드 (Incremental Update)
- Dimension 테이블 변경 추적 (히스토리 테이블)
- 용이한 문서 작성
Fact 테이블과 Dimension 테이블
Fact 테이블
- 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이블
- 일반적으로 매출 수익, 판매량, 이익과 같은 측정 항목 포함. 비즈니스 결정에 사용
- Fact 테이블은 일반적으로 foreign key를 통해 여러 Dimension 테이블과 연결됨
- 보통 Fact 테이블의 크기가 훨씬 더 큼
- 한 번 기록이 되면 바뀔 일이 거의 없음
Dimension 테이블
- Fact 테이블에 대한 상세 정보를 제공하는 테이블
- 고객, 제품과 같은 테이블로 Fact 테이블에 대한 상세 정보 제공
- Fact 테이블의 데이터에 맥락을 제공하여 다양한 방식으로 분석 가능하게
해줌 - Dimension 테이블은 primary key를 가지며, fact 테이블에서 참조 (foreign key)
- 보통 Dimension 테이블의 크기는 훨씬 더 작음
- 대부분 시간이 지나면서 바뀜
dbt 환경 설정
dbt 사용절차
- dbt 설치
- dbt Cloud vs. dbt Core
- git을 보통 사용함
- dbt 환경설정
- Connector 설정
- Connector가 바로 바탕이 되는 데이터 시스템 (Redshift, Spark, …)
- 데이터 모델링 (tier)
- Raw Data -> Staging -> Core
- 테스트 코드 작성
- (필요하다면) Snapshot 설정
dbt init : 프로젝트 생성
% dbt init 프로젝트 이름
Which database would you like to use?
[1] redshift
[2] postgres
Enter a number:
host (hostname.region.redshift.amazonaws.com):
port [5439]:
user (dev username):
[1] password
[2] iam
Desired authentication method option (enter a number):1
password (dev password):
dbname (default database that dbt will build objects in): dev
schema (default schema that dbt will build objects in):
threads (1 or more) [1]: 1~/.dbt/profiles.yml
- dbt 전체에 대해 커넥션 등의 정보들이 저장됨 (프로젝트 관련 정보는 프로젝트 yml 파일)
learn_dbt: # 프로젝트 이름
outputs:
dev:
dbname:
host:
password: ******
port:
schema:
threads: 1
type:
user:
target: dbt 파일과 폴더 설명
- dbt_project.yml: 메인 환경 설정 파일
- models
- seeds
- tests
- snapshots
- macros
- analyses
- README.md
dbt_project.yml
name: 'learn_dbt'
version: '1.0.0'
config-version: 2
profile: 'learn_dbt'
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # folder to store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
models:
learn_dbt:
example:
+materialized: viewdbt Models: Input/Output
Model
- ELT 테이블을 만듬에 있어 기본이 되는 빌딩블록
- 테이블이나 뷰나 CTE의 형태로 존재 - 입력,중간,최종 테이블을 정의하는 곳
- 티어 (raw, staging, core, …)
- raw => staging (src) => core
Model 구성 요소
Input
- 입력(raw)과 중간(staging, src) 데이터 정의
- raw는 CTE로 정의
- staging은 View로 정의
Output
- 최종(core) 데이터 정의
- core는 Table로 정의
이 모두는 models 폴더 밑에 sql 파일로 존재
- 기본적으로는 SELECT + Jinja 템플릿과 매크로
- 다른 테이블들을 사용 가능 (reference)
◦ 이를 통해 리니지 파악
Materialization
- 입력 데이터(테이블)들을 연결해서 새로운 데이터(테이블) 생성하는 것
- 보통 여기서 추가 transformation이나 데이터 클린업 수행 - 4가지의 내장 materialization이 제공됨
- 파일이나 프로젝트 레벨에서 가능
- 역시 dbt run을 기타 파라미터를 가지고 실행
Materialization 종류
- View
- 데이터를 자주 사용하지 않는 경우 - Table
- 데이터를 반복해서 자주 사용하는 경우 - Incremental (Table Appends)
- Fact 테이블
- 과거 레코드를 수정할 필요가 없는 경우 - Ephemeral (CTE)
- 한 SELECT에서 자주 사용되는 데이터를 모듈화하는데 사용

.