
📖 학습주제
DBT 소개, 데이터 디스커버리, 툴 학습 (2)
dbt Seeds
Seeds
- 많은 dimension 테이블들은 크기가 작고 많이 변하지 않는데, Seeds는 이를 파일 형태로 데이터웨어하우스로 로드하는 방법
- Seeds는 작은 파일 데이터를 지칭 (보통 csv 파일) - dbt seed를 실행해서 빌드
dbt Sources
Sources
- Staging 테이블을 만들 때 입력 테이블들이 자주 바뀐다면, models 밑의 .sql 파일들을 일일이 찾아 바꿔주어야함
-> 이 번거로움을 해결하기 위한 것이 Sources (입력 테이블에 별칭을 주고 별칭을 staging 테이블에서 사용) - 기본적으로 처음 입력이 되는 ETL 테이블을 대상으로 함
- 별칭 제공
- 최신 레코드 체크 기능 제공 - 테이블 이름들에 별명(alias)을 주는 것
- 이를 통해 ETL단의 소스 테이블이 바뀌어도 뒤에 영향을 주지 않음
- 상화를 통한 변경처리를 용이하게 하는 것
- 이 별명은 source 이름과 새 테이블 이름의 두 가지로 구성됨 (이 맵핑을 해주는 파일이sources.yml)
e.g.) raw_data.user_metadata -> keeyong, metadata - Source 테이블들에 새 레코드가 있는지 체크해주는 기능도 제공
models/sources.yml 예
version: 2
sources:
- name:
schema: raw_data
tables:
- name: metadata
identifier: user_metadata
- name: event
identifier: user_event
- name: variant
identifier: user_variantraw_data.user_metadata는
JINJA에서 source(“keeyong”, “metadata”)로 지칭됨
Sources 최신성 (Freshness)
- 특정 데이터가 소스와 비교해서 얼마나 최신성이 떨어지는지 체크하는
기능 dbt source freshness명령으로 수행- 이를 하려면
odels/sources.yml의 해당 테이블 밑에 아래 추가
...
- name: event
identifier: user_event
# freshness를 결정해주는 필드
loaded_at_field: datestamp
freshness:
warn_after: { count: 1, period: hour }
error_after: { count: 24, period: hour }지금 raw_data.user_event 테이블에서 datestamp의 최대값이 현재 시간보다 1시간 이상 뒤쳐져 있지만 24시간은 아니라면 warning.
24시간 이상이라면 error
dbt Snapshots
데이터베이스에서의 스냅샷
- Dimension 테이블은 성격에 따라 변경이 자주 생길 수 있음
- dbt에서는 테이블의 변화를 계속적으로 기록함으로써 과거 어느 시점이건 다시 돌아가서 테이블의 내용을 볼 수 있는 기능을 이야기함
- 이를 통해 테이블에 문제가 있을 경우 과거 데이터로 롤백 가능
- 다양한 데이터 관련 문제 디버깅도 쉬워짐
SCD Type 2와 dbt
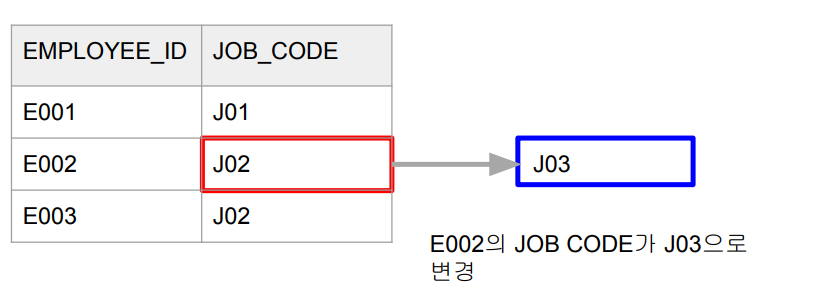
- Dimension 테이블에서 특정 entity에 대한 데이터가 변경되는 경우
- e.g.) employee_jobs 테이블
- 특정 employee_id의 job_code가 바뀌는 경우
- 변경시간도 같이 추가되어야함
- Dimension 테이블에서 특정 entity에 대한 데이터가 변경되는 경우
- 새로운 Dimension 테이블을 생성 (history/snapshot 테이블)
dbt의 스냅샷 처리 방법
- 먼저 snapshots 폴더에 환경설정이 됨
- snapshots을 하려면 데이터 소스가 일정 조건을 만족해야함
- Primary key가 존재해야함
- 레코드의 변경시간을 나타내는 타임스탬프 필요 (updated_at, modified_at 등등) - 변경 감지 기준
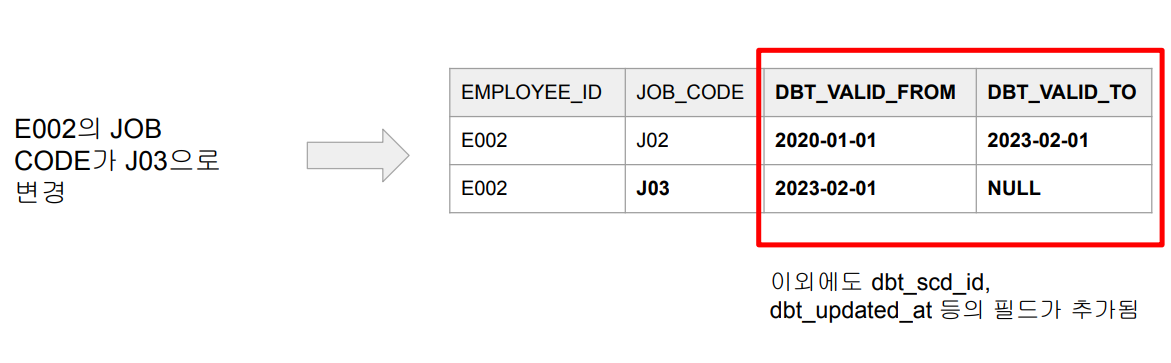
- Primary key 기준으로 변경시간이 현재 DW에 있는 시간보다 미래인 경우 - Snapshots 테이블에는 총 4개의 타임스탬프가 존재
- dbt_scd_id, dbt_updated_at
- valid_from, valid_to
dbt snapshot 적용해보기
e.g.) snapshots/scd_user_metadata.sql 편집
{% snapshot scd_user_metadata %}
{{
config(
target_schema='schema_name',
unique_key='user_id',
strategy='timestamp',
updated_at='updated_at',
invalidate_hard_deletes=True
)
}}
SELECT * FROM {{ source('keeyong', 'metadata') }}
{% endsnapshot %}dbt Tests
Tests 소개
- 데이터 품질을 테스트하는 방법
- 두 가지가 존재
내장 일반 테스트 (“Generic”)
- unique, not_null, accepted_values, relationships 등의 테스트 지원
- models 폴더
Generic Tests 구현 예
models/schema.yml 파일 생성
version: 2
models:
- name: dim_user_metadata
columns:
- name: user_id
tests:
- unique
- not_null
커스텀 테스트 (“Singular”)
- 기본적으로 SELECT로 간단하며 결과가 리턴되면 “실패”로 간주
- tests 폴더
Singular Tests 구현 예
tests/dim_user_metadata.sql 파일 생성
Primary Key Uniqueness 테스트
SELECT
*
FROM (
SELECT
user_id, COUNT(1) cnt
FROM
{{ ref("dim_user_metadata") }}
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1
)
WHERE cnt > 1dbt Documentation
dbt 문서화
- 기본 철학은 문서와 소스 코드를 최대한 가깝게 배치하자는 것
- 문서화 자체는 두 가지 방법이 존재
- 기존 .yml 파일에 문서화 추가 (선호되는 방식)
- 독립적인 markdown 파일 생성 - 이를 경량 웹서버로 서빙
- overview.md가 기본 홈페이지가 됨
- 이미지등의 asset 추가도 가능
dbt Expectations
dbt Expectations
- Great Expectations에서 영감을 받아 dbt용으로 만든 dbt 확장판
https://github.com/calogica/dbt-expectations - 설치 후 packages.yml에 등록
packages:
- package: calogica/dbt_expectationsversion: [">=0.7.0", "<0.8.0"]
- 보통은 앞서 dbt 제공 테스트들과 같이 사용
- models/schema.yml
데이터 카탈로그가 가져야할 기능
데이터 카탈로그
- 데이터 자산 메타 정보 중앙 저장소
- 데이터 거버넌스의 첫 걸음
- 많은 회사에서 데이터 카탈로그를 데이터 거버넌스 툴로 사용하거나 데이터 카탈로그 위에 커스텀 기능을 구현 - 데이터 카탈로그의 중요한 기능
- (반)자동화된 메타 데이터 수집!
- 데이터 보안! 보통 메타 데이터만 읽어옴
데이터 자산의 종류
- 테이블 (데이터베이스)
- 대시보드
- 문서/메세지 (슬랙, JIRA, Github, …)
- ML 피쳐
- 데이터 파이프라인
- 사용자 (HR 시스템)
데이터 카탈로그 : 데이터 자산의 효율적인 관리 프레임워크
- 다양한 관점에서 데이터를 조직적으로 관리
- 비지니스/데이터 용어 vs. 태그
- 데이터 오너 (Business & Technical)
- 표준화된 문서 템플릿
데이터 카탈로그 주요 기능
주요 데이터 플랫폼 지원
- Data Warehouses & Data Lakes : Redshift, Snowflake, BigQuery
- BI Tools : Looker, Tableau, Redash, Power BI, Mode, Superset
- ELT : DBT, Spark, Hive, PrestoDB
- ETL Orchestration : Airflow
- NoSQL and others
- Cassandra, Druid, Elastic Search, Kafka Schema Registry, CSV - Users : Azure AD, LDAP, …
비지니스 용어집 (Business Glossary)
- 권한이 있는 사람만 용어 정의가 가능
- 계층구조로 관리할 수 있다면 더 유용
- DataHub의 경우 terms와 terms group 존재 - 비지니스 용어와 Entity 연결
- 나중에 다른 entity등과 연결 가능
협업
- 태그
- 태그 vs. 비지니스 용어 : 전자는 좀더 비공식적인 데이터 분류 방법, 보통 후자는 계층 구조 형태의 분류체계를 따라감 - 문서화 표준 제공
데이터 리니지
- Dataset-to-dataset
-보통 SQL 파싱으로 일어남 - Pipeline
- 입력 데이터셋 -> Data Pipeline -> 출력 데이터셋
- Airflow에 lineage backend라는 것이 존재 - Dashboard-to-chart
- 하나의 차트가 여러 대시보드에 소속가능하기에 필요한 리니지 - Chart-to-dataset
- Job-to-dataflow
- DBT에 특별한 리니지
그 외
- 데이터 모니터링, 감사, 트레이싱
- 강력한 검색 기능 (통합 검색, NLP 검색)
- 데이터 추천 기능
- 데이터 유저 퍼소나 (예: 마케팅 분석가)
데이터 거버넌스 관점에서 데이터 카탈로그의 중요성
- 우리가 갖고 있는 데이터 자산에 대한 통합 뷰를 제공
- 생산성 증대 : 설문이나 데이터 티켓의 감소로 확인
- 위험 감소 : 잘못된 결정과 개인정보등의 전파 방지
- 인프라 비용 감소 : 불필요한 정보의 생성 방지와 안 쓰이는 데이터셋 삭제
- 데이터 티켓 감소
- 데이터 변경으로 인한 이슈 감소
- 컬럼 레벨 리니지와 CI/CD 프로세스 연동
데이터 카탈로그 이후 다음 스텝
- 자동화된 데이터 거버넌스 관련 웍플로우를 추가
- 일단 시작으로 품질 관련 경보 시스템 구현
- 중요 메타데이터 변경이나 데이터 품질 이슈 발생시 경보
- 내가 관심있는 데이터 자산의 오너 변경시 경보 (예: 매출 정의 변경) - 데이터 관련 지표 리뷰 미팅 운영

.