
📖 학습주제
빅데이터 처리 시스템, Hadoop, Spark (3)
Spark SQL
SQL
- 데이터 분야에서 일하고자 하면 반드시 익혀야할 기본 기술
- 구조화된 데이터를 다루는한 SQL은 데이터 규모와 상관없이 쓰임
- 모든 대용량 데이터 웨어하우스는 SQL 기반
- Redshift, Snowflake, BigQuery
- Hive/Presto - Spark도 마찬가지
- Spark SQL이 지원됨
Spark SQL이란?
- Spark SQL은 구조화된 데이터 처리를 위한 Spark 모듈
- 데이터 프레임 작업을 SQL로 처리 가능
- 데이터프레임에 테이블 이름 지정 후 sql함수 사용가능
- HQL(Hive Query Language)과 호환 제공
Aggregation, JOIN, UDF
Aggregation
- Group By
- Window
- Rank
- DataFrame이 아닌 SQL로 작성하는 것을 추천
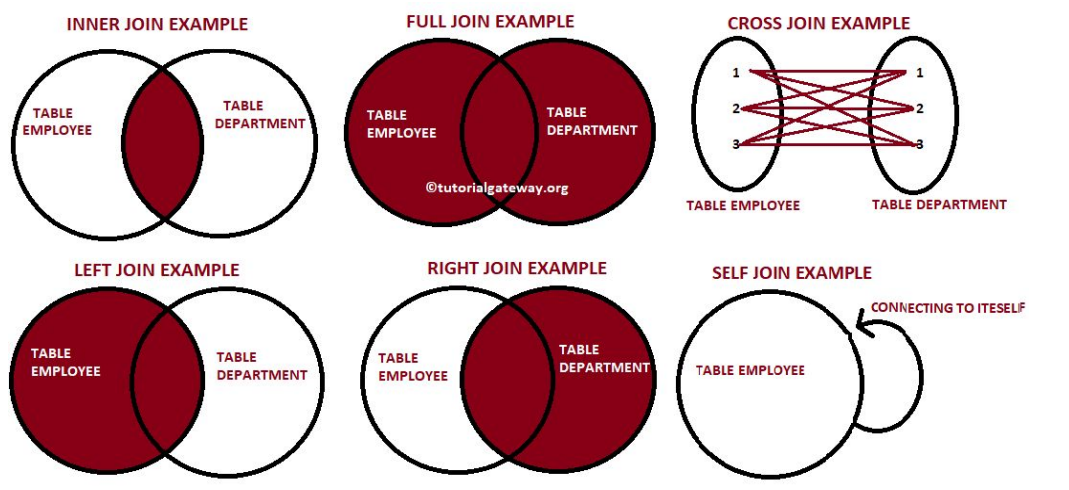
JOIN
- 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 머지
- 스타 스키마로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용
- 왼쪽 테이블을 LEFT라고 하고 오른쪽 테이블을 RIGHT이라고 하면
- JOIN의 결과는 방식에 따라 양쪽의 필드를 모두 가진 새로운 테이블을 생성
- 조인의 방식에 따라 다음 두 가지가 달라짐
◦ 어떤 레코드들이 선택되는지?
◦ 어떤 필드들이 채워지는지?
다양한 종류의 조인
최적화 관점에서 본 조인의 종류들
Shuffle JOIN
- 일반 조인 방식
- Bucket JOIN: 조인 키를 바탕으로 새로 파티션을 새로 만들고 조인을 하는 방식
Broadcast JOIN
- 큰 데이터와 작은 데이터 간의 조인
- 데이터 프레임 하나가 충분히 작으면 작은 데이터 프레임을 다른 데이터 프레임이 있는 서버들로 뿌리는 것 (broadcasting)
-spark.sql.autoBroadcastJoinThreshold파라미터로 충분히 작은지 여부 결정
UDF
- User Defined Function
- DataFrame이나 SQL에서 적용할 수 있는 사용자 정의 함수
- Scalar 함수 vs. Aggregation 함수
- Scalar 함수 : UPPER, LOWER, …
- Aggregation 함수 (UDAF) : SUM, MIN, MAX, …
UDF 사용 방법
함수 구현
- 파이썬 람다 함수
- 파이썬 (보통) 함수
- 파이썬 판다스 함수:
-pyspark.sql.functions.pandas_udf로 annotation
- Apache Arrow를 사용해서 파이썬 객체를 자바 객체로 변환이 훨씬 더 효율적
함수 등록
pyspark.sql.functions.udf
- DataFrame에서만 사용 가능spark.udf.register
- SQL 모두에서 사용 가능
함수 사용
.withColumn,.agg- SQL
Hive 메타 스토어
Spark 데이터베이스와 테이블
카탈로그 : 테이블과 뷰에 관한 메타 데이터 관리
- 기본으로 메모리 기반 카탈로그 제공 - 세션이 끝나면 사라짐
- Hive와 호환되는 카탈로그 제공 - Persistent
테이블 관리 방식
- 테이블들은 데이터베이스라 부르는 폴더와 같은 구조로 관리 (2단계)
메모리 기반 테이블/뷰
- 임시 테이블
스토리지 기반 테이블
- 기본적으로 HDFS와 Parquet 포맷을 사용
- Hive와 호환되는 메타스토어 사용
- 두 종류의 테이블이 존재 (Hive와 동일한 개념)
- Managed Table
- Spark이 실제 데이터와 메타 데이터 모두 관리
- Unmanaged (External) Table
- Spark이 메타 데이터만 관리
Spark SQL - 스토리지 기반 카탈로그 사용 방법
- Hive와 호환되는 메타스토어 사용
- SparkSession 생성시 enableHiveSupport() 호출
- 기본으로 “default”라는 이름의 데이터베이스 생성
Spark SQL - Managed Table 사용 방법
- 테이블 생성방법
- dataframe.saveAsTable("테이블이름")
- SQL 문법 사용 (CREATE TABLE, CTAS) spark.sql.warehouse.dir가 가리키는 위치에 데이터가 저장됨
- PARQUET이 기본 데이터 포맷- 선호하는 테이블 타입
- Spark 테이블로 처리하는 것의 장점 (파일로 저장하는 것과 비교시)
- JDBC/ODBC등으로 Spark을 연결해서 접근 가능 (태블로, 파워BI)
Spark SQL - External Table 사용 방법
- 이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용
- LOCATION이란 프로퍼티 사용 - 메타데이터만 카탈로그에 기록됨
- 데이터는 이미 존재
- External Table은 삭제되어도 데이터는 그대로임
유닛 테스트
유닛 테스트
- 코드 상의 특정 기능 (보통 메소드의 형태)을 테스트하기 위해 작성된 코드
- 보통 정해진 입력을 주고 예상된 출력이 나오는지 형태로 테스트
- CI/CD를 사용하려면 전체 코드의 테스트 커버러지가 굉장히 중요해짐
- 각 언어별로 정해진 테스트 프레임웍을 사용하는 것이 일반적
- JUnit for Java
- NUnit for .NET
- unittest for Python

.