
📖 학습주제
빅데이터 처리 시스템, Hadoop, Spark (4)
Spark 파일 포맷
파일 포맷
데이터는 디스크에 파일로 저장되고 일에 맞게 최적화 필요함
Unstructured
- Text
Semi-structured
- JSON
- XML
- CSV
이상 HUMAN READABLE (눈으로 확인 가능)
Structured
- PARQUET
- AVRO
- ORC
- SequenceFile
Structured data들은 BinaryFile이고 압축되어 있으며 내부에 스키마정보를 가지고 있음
Spark의 주요 파일 타입
| 특징 | CSV | JSON | PARQUET | AVRO |
|---|---|---|---|---|
| 컬럼 스토리지 | X | X | Y | Y |
| 압축 가능 | Y | Y | Y | Y |
| Splittable | Y* | Y* | Y | Y |
| Human readable | Y | Y | X | X |
| Nested structure support | X | Y | Y | Y |
| Schema evolution | X | X | Y | Y |
PARQUET : Spark의 기본 파일 포맷
Y* : 압축되면 Splittable 하지 않음 (압축 방식에 따라 다름 - snappy 압축이라면 Splittable)
Splittable : HDFS에서 데이터가 저장될 때 데이터 블록 단위로 나뉘게 되는데, 그 데이터 블록이 Spark에서 로딩 될 때 바로 파티션으로 올라갈 수 있는가
Parquet: Spark의 기본 파일 포맷
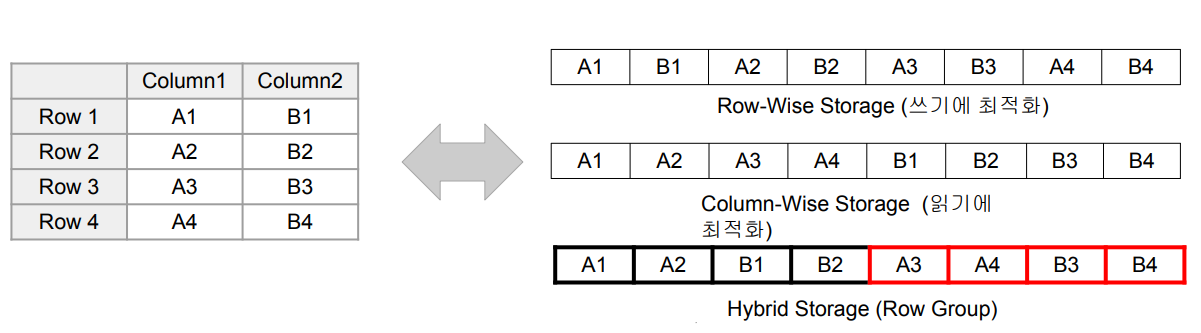
Hybrid Storage : Parquet가 사용하는 방식, 하나의 데이터 블록은 하나의 Row Group으로 구성됨
Execution Plan
Transformations and Actions
Transformations
- Narrow Dependencies : 독립적인 Partition level 작업
- select, filter, map 등 - Wide Dependencies : Shuffling이 필요한 작업
- groupby, reduceby, partitionby, repartition 등
Actions
- Read, Write, Show, Collect -> Job을 실행시킴 (실제 코드가 실행됨)
- Lazy Execution
- 장점 : 더 많은 오퍼레이션을 볼 수 있기에 최적화를 더 잘할 수 있음. 그래서 SQL이 더 선호됨
예시
spark.read.option("header", True).csv(“test.csv”). \
where("gender <> 'F'"). \
select("name", "gender"). \
groupby("gender"). \
count(). \
show()
Jobs, Stages, Tasks
Action -> Job -> 1+ Stages -> 1+ Tasks
Action
- Job을 하나 만들어내고 코드가 실제로 실행됨
Job
- 하나 혹은 그 이상의 Stage로 구성됨
- Stage는 Shuffling이 발생하는 경우 새로 생김
Stage
- DAG의 형태로 구성된 Task들 존재
- 여기 Task들은 병렬 실행이 가능
Task
- 가장 작은 실행 유닛으로 Executor에 의해 실행됨
Bucketing과 Partitioning
Bucketing과 File System Partitioning
- 둘다 Hive 메타스토어의 사용이 필요: saveAsTable
- 데이터 저장을 이후 반복처리에 최적화된 방법으로 하는 것
Bucketing
- 먼저 Aggregation이나 Window 함수나 JOIN에서 많이 사용되는 컬럼이 있는지, 있다면 데이터를 이 특정 컬럼(들)을 기준으로 테이블로 저장
- 이 때의 버킷의 수도 지정
File System Partitioning
- 데이터의 특정 컬럼(들)을 기준으로 폴더 구조를 만들어 데이터 저장 최적화
- 위의 컬럼들을 Partition Key라고 부름
Bucketing
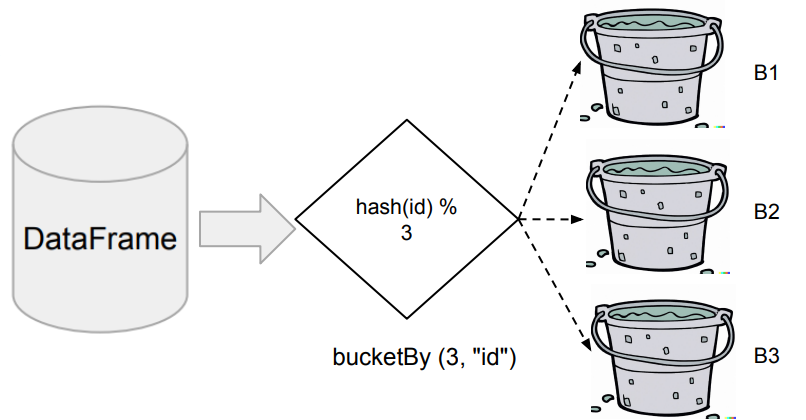
- DataFrame을 특정 ID를 기준으로 나눠서 테이블로 저장
- 다음부터는 이를 로딩하여 사용함으로써 반복 처리시 시간 단축
◦ DataFrameWriter의 bucketBy 함수 사용
◦ Bucket의 수와 기준 ID 지정 - 데이터의 특성을 잘 알고 있는 경우 사용 가능
File System Partitioning
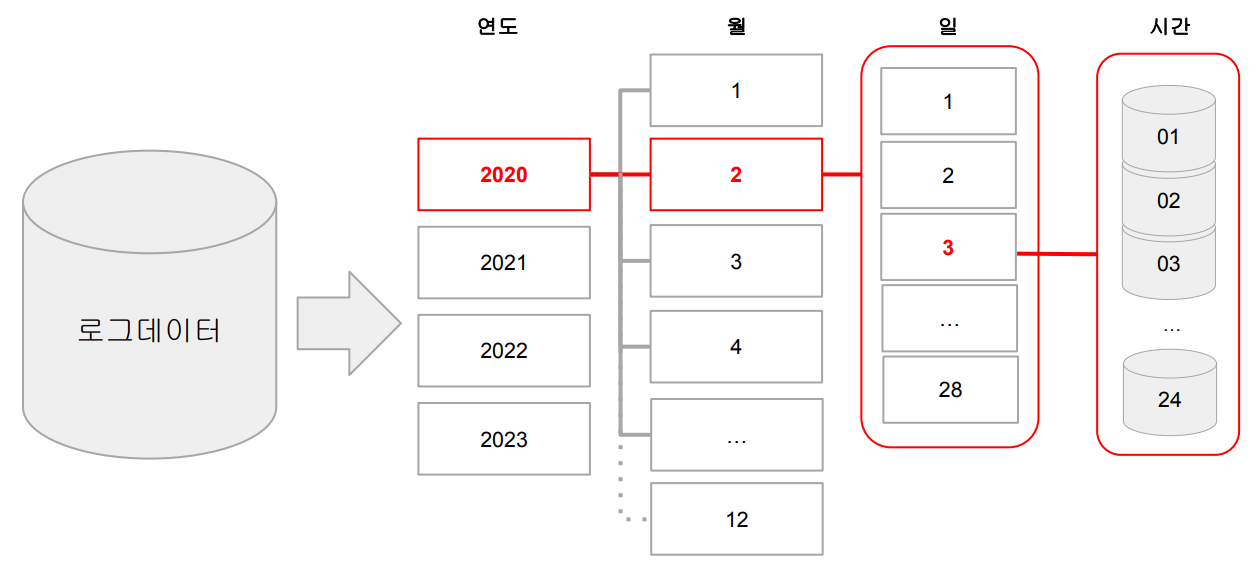
- 데이터를 Partition Key 기반 폴더 (“Partition") 구조로 물리적으로 나눠 저장
- Hive에서 사용하는 Partitioning을 말함
Partitioning의 예와 잇점
- 굉장히 큰 로그 파일을 데이터 생성시간 기반으로 데이터 읽기를 많이 한다면?
- 데이터 자체를 연도-월-일의 폴더 구조로 저장
- 보통 위의 구조로 이미 저장되는 경우가 많음 - 이를 통해 데이터를 읽기 과정을 최적화 (스캐닝 과정이 줄어들거나 없어짐)
- 데이터 관리도 쉬워짐 (Retention Policy 적용시)
DataFrameWriter의 partitionBy 사용
- Partition key를 잘못 선택하면 엄청나게 많은 파일들이 생성됨!

.