
📖 학습주제
Kafka와 Spark Streaming 기반 스트리밍 처리 (1)
구글이 데이터 분야에 끼친 영향
구글 검색 엔진의 등장
- 1995년 스탠포드 대학에서 박사과정으로 있던 래리 페이지와 세르게이 브린이 1998년에 발표한 웹 검색 서비스
- 그 전까지의 검색 엔진은 기본적으로 웹 페이지 상의 텍스트를 보고 랭킹을 결정
- 알타비스타, 야후, Ask Jeeves, …
- 검색 결과 페이지에 온갖 종류의 스팸 웹 페이지들이 넘쳐나기 시작 - 구글은 웹 페이지들간의 링크를 기반으로 중요한 페이지를 찾아서 검색 순위 결정
- 이 알고리즘을 래리 페이지의 이름을 따서 페이지 랭크라고 부름
- 페이지 랭크 논문 발표으로 차세대 검색엔진들이 나옴 (중국의 바이두, 러시아의 얀덱스 등등) - 기존의 강자들을 넘어서 2004년부터 세계 최고의 검색엔진으로 등장
- 2004년 여름에 상장됨 ($23B)
- 2021년 2월 기준 $1.41T으로 급성장
◦ 검색 마케팅 플랫폼으로 확장 (Google Ads): 오버추어와 경쟁
◦ 안드로이드 개발로 모바일 생태계 지배
◦ Youtube 인수를 통한 스트리밍 시장 석권 - 다양한 논문 발표와 오픈소스 활동으로 개발자 커뮤니티에 큰 영향을 끼침
페이지 랭크
https://www.cis.upenn.edu/~mkearns/teaching/NetworkedLife/pagerank.pdf
(The PageRank Citation Ranking: bringing order to the web (1998))
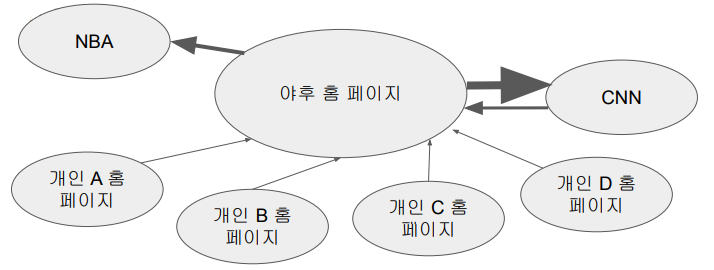
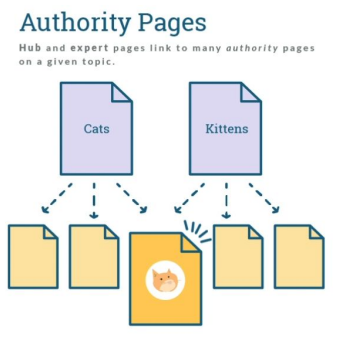
- 더 중요한 페이지는 더 많은 다른 사이트들로부터 링크를 받는다는 관찰에 기초
- 중요한 페이지가 링크를 건 페이지들 역시 상대적으로 중요한 페이지라는 관찰에 기초
- 이를 기반으로 계산을 반복하면 웹상의 모든 페이지들에 중요도 점수를 부여할 수 있음
- 페이지 랭크의 계산은 대용량 컴퓨팅 인프라와 소프트웨어 없이는 불가능
검색엔진의 데이터 처리 - 주기적 검색 인덱스 빌딩
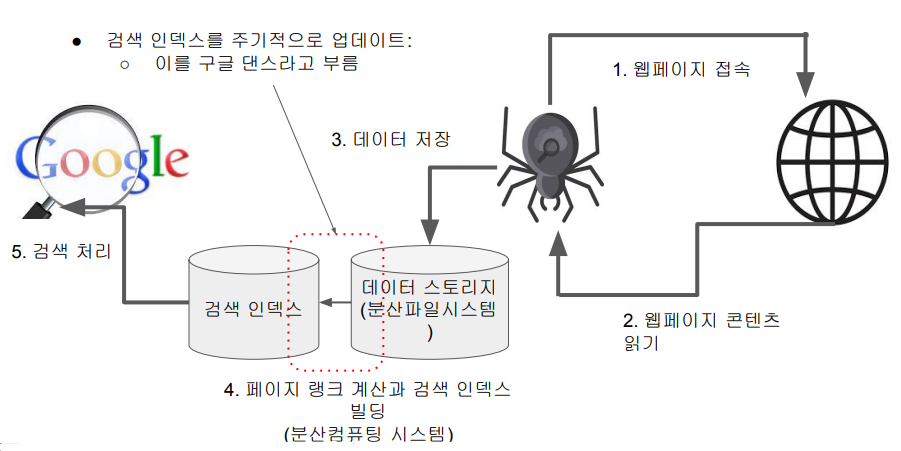
기술적 진보와 공유 : 빅데이터 시대의 도래
- 검색엔진은 기본적으로 대량의 데이터를 처리하게 됨
- 수백 조개의 웹페이지를 크롤하고 거기서 나온 텍스트로부터 색인 추출
- 웹페이지 그래프를 기반으로 페이지랭크 계산
- 검색시 대용량 인덱스를 뒤져서 최적의 결과를 찾아내야함
- 다양한 언어 지원이 필요
- 사용자 검색어와 클릭로그를 기반으로 한 각종 마이닝
- 동의어 찾기
- 통계기반 번역 (statistical translation)
- 검색입력 자동 완성(auto-completion)
검색 기술과 검색 마케팅의 결합 - 구글 애드워즈
- 구글은 오버추어가 시작한 웹 검색 광고를 발전시켜 구글 애드워즈(AdWords) 라고 명명
- 지금은 이를 구글 애즈(Ads)라고 부름
- 사실은 오버추어의 기술을 무단 복사
◦ 오버추어가 2002년에 소송을 걸었고 2004년 야후(오버추어)의 승리로 마무리됨
◦ 구글이 2백70만개의 주식을 야후로 주는 것으로 정리됨 - 구글과 오버추어의 검색 마케팅 방법의 차이점은?
- 오버추어가 처음 시작했지만 검색어 경매 방식에 사람이 끼어들어야만 했기에
비효율적이었음
◦ 시간이 오래 걸리고 검색어 광고의 성능을 염두에 두지 못함
- 구글은 처음부터 웹기반 자동화를 염두에 두고 만들어 사람의 개입 없이 검색어 경매와 광고 시스템을 구축
◦ 검색어 광고의 성능에 따라 노출 빈도도 결정됨
데이터 처리의 발전 단계
데이터 처리의 일반적인 단계
- 데이터 수집 (Data Collection)
- 데이터 저장 (Data Storage)
- 데이터 처리 (Data Processing)
- 이 과정에서 서비스 효율을 높이거나 의사결정을 더 과학적으로 하게 됨
데이터 저장 시스템의 변천

데이터 처리의 고도화
- 처음에는 배치로 시작
- 이 경우 처리할 수 있는 데이터의 양이 중요 - 서비스가 고도화되면 점점더 실시간 처리 요구가 생기기 시작함
- Realtime 처리 vs. Semi Realtime 처리
- 동일 데이터 소비가 필요한 케이스 증가: 다수의 데이터 소비자 등장
처리량(Throughput) vs. 지연시간(Latency)
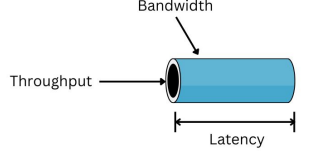
- 처리량은 주어진 단위 시간 동안 처리할 수 있는 데이터의 양
- 클수록 처리할 수 있는 데이터의 양이 큼을 의미. 배치 시스템에서 더 중요 (예: 데이터 웨어하우스) - 지연 시간은 데이터를 처리하는 데 걸리는 시간
- 작을수록 응답이 빠름을 의미. 실시간 시스템에서 더 중요함 (예: 프로덕션 DB) - 대역폭 (Bandwidth) = 처리량 x 지연시간
SLA (Service Level Agreement)
- 서비스 제공업체와 고객 간의 계약 또는 합의
- 서비스 제공업체가 제공하는 서비스 품질, 성능 및 가용성의 합의된 수준을 개괄적으로 기술
- SLA는 통신, 클라우드 컴퓨팅, 등 다양한 산업에서 사용됨 - 사내 시스템들간에도 SLA를 정의하기도 함
- 이 경우 지연시간 (Latency)나 업타임(Uptime)등이 보통 SLA로 사용됨
◦ 예를 들어 업타임이라면 99.9% = 8시간 45.6분
◦ API라면 평균 응답 시간 혹은 99% 이상 0.5초 전에 응답이 되어야함 등이 예
- 데이터 시스템이라면 데이터의 시의성 (Freshness)도 중요한 포인트가 됨
배치 처리
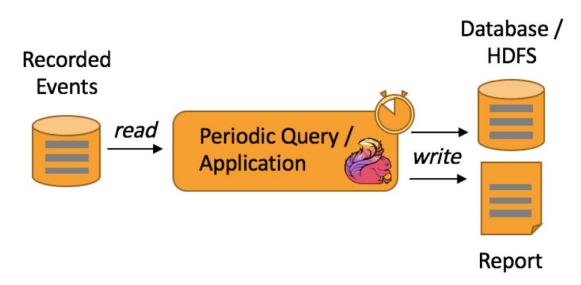
- 주기적으로 데이터를 한 곳에서 다른 곳으로 이동하거나 처리
- 처리량(Throughput)이 중요
데이터 배치 처리
- 처리 주기는 보통 분에서 시간, 일 단위
- 데이터를 모아서 처리
- 처리 시스템 구조
- 분산 파일 시스템(HDFS, S3)
- 분산 처리 시스템(MapReduce, Hive/Presto, Spark DataFrame, Spark SQL)
- 처리 작업 스케줄링에 보통 Airflow 사용
실시간 처리
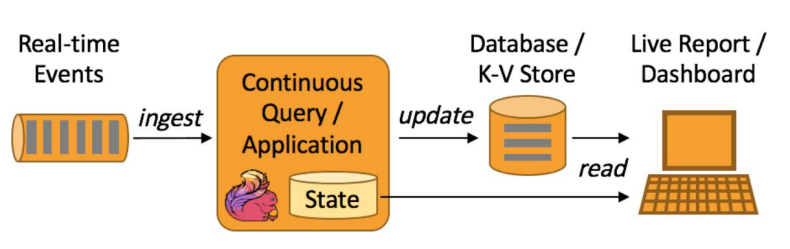
- 연속적인 데이터 처리
- realtime vs. semi-realtime (micro batch) - 이 경우 지연시간(처리속도, Latency)이 중요
데이터 실시간 처리
- 배치 처리 다음의 고도화 단계
- 시스템 관리 등의 복잡도가 증가 - 초단위의 계속적인 데이터 처리
- 이런 데이터를 보통 Event라고 부르며 이벤트의 특징은 바뀌지 않는 데이터라는 점 (Immutable)
- 계속해서 발생하는 Event들을 Event Stream이라고 부름

- 다른 형태의 서비스들이 필요해지기 시작함
- 이벤트 데이터를 저장하기 위한 메세지 큐들: Kafka, Kinesis, Pub/Sub, …
- 이벤트 처리를 위한 처리 시스템: Spark Streaming, Samza, Flink, …
- 이런 형태의 데이터 분석을 위한 애널리틱스/대시보드: Druid
- 처리 시스템 구조
- Producer(Publisher)가 있어서 데이터 생성
- 생성된 데이터를 메세지 큐와 같은 시스템에 저장
◦ Kafka, Kinesis, PubSub 등의 시스템 존재
◦ 데이터 스트림(Kafka에서는 토픽이라 부름)마다 별도의 데이터 보유 기한 설정
- Consumer (Subscriber)가 있어서 큐로부터 데이터를 읽어서 처리
◦ Consumer마다 별도 포인터 유지. 다수의 Consumer가 데이터 읽기를 공동 수행하기도 함

검색엔진의 데이터 처리 - 계속적인 검색 인덱스 업데이트
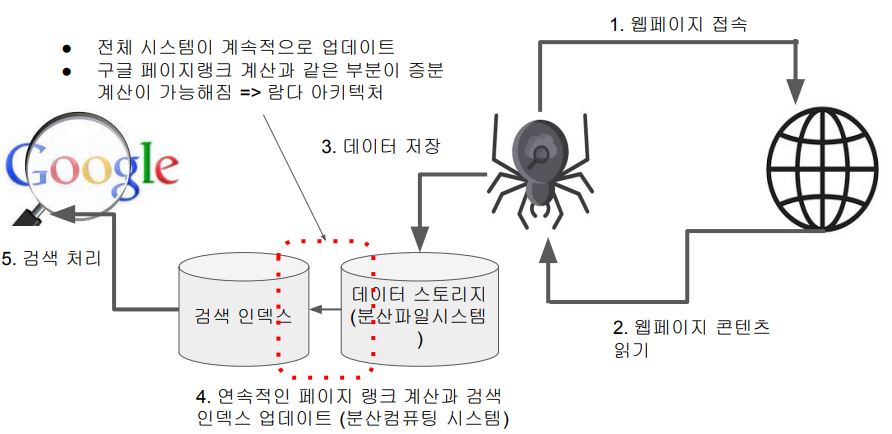
람다 아키텍처 (Lambda Architecture)
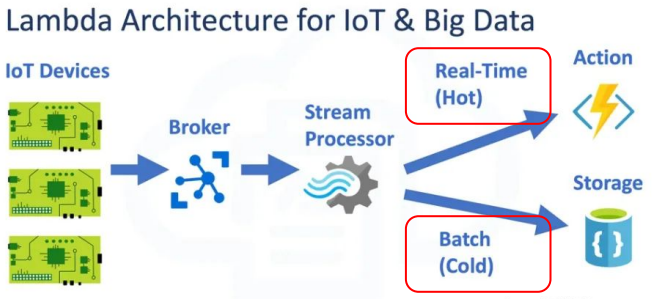
- 배치 레이어와 실시간 레이어 두 개를 별도로 운영
데이터 실시간 처리의 장점
- 즉각적인 인사이트 발견
- 운영 효율성 향상
- 사고와 같은 이벤트에 대한 신속 대응
- 더 효율적인 개인화된 사용자 경험
- IoT 및 센서 데이터 활용
- 사기 탐지 및 보안
- 실시간 협업 및 커뮤니케이션
데이터 실시간 처리의 단점
- 전체적으로 시스템이 복잡해짐
- 배치 시스템은 주기적으로 동작하며 보통은 실제 사용자에게 바로 노출되는 일을 하지 않음
- 실시간 처리의 경우에는 실제 사용자와 관련된 일에 사용될 확률이 더 높기에 시스템 장애 대응이 중요해짐
◦ 배치 추천 vs. 실시간 추천
◦ DevOps의 영역으로 들어가기 시작함 - 이에 따른 운영 비용 증가
- 배치처리는 잘못 되어도 데이터 유실 이슈가 적지만 실시간 처리는 데이터 유실의 가능성이 커지기에 항상 데이터 백업에 신경을 써야함
데이터 실시간 처리: Realtime vs. Semi-Realtime
Realtime
- 짧은 Latency
- 연속적인 데이터 스트림
- 이벤트 중심 아키텍처: 수신 데이터 이벤트에 의해 작업이나 계산이 트리거되는 구조
- 동적 및 반응형: 데이터 스트림의 변화에 동적으로 대응하여 실시간 분석, 모니터링 및 의사 결정을 수행
Semi-Realtime
- 합리적인 Latency
- 배치와 유사한 처리 (Micro-batch)
- 적시성과 효율성 사이의 균형: 처리 용량과 리소스 활용도를 높이기 위해 일부 즉각성을 희생하기도 함
- 주기적인 업데이트
실시간 데이터 종류와 사용 사례
Events are everywhere
Online Service
- 온갖 종류의 Funnel Data
- Product Impressions, Clicks (Click Stream), Purchase, …
- User Registration (회원등록 버튼 클릭 => 상세정보 입력 => … => 등록 버튼) - Page Views and Performance Data
- 페이지별로 렌더링 시간을 기록하면 나중에 문제 발생시 원인 파악이 쉬워짐
◦ 이를 디바이스 타입에 따라 기록 (데스크탑, 모바일, …)
- 또한 페이지별로 에러발생시 에러 이벤트 등록 - 사용자 등록, 사용자 로그인, 방문자 발생
- 이런 사용자 행동 데이터들의 데이터 모델 정의와 수집이 중요해짐
- 데이터가 제대로 수집된 후에 저장과 소비도 가능 - 그러다보니 이벤트 데이터 수집만 전담하는 팀도 생기기 시작함
Retail Business
-
재고 업데이트
재고 추가 또는 품절과 같은 재고 수준의 변화를 반영하는 이벤트 -
주문 이벤트
주문 배치, 주문 상태 업데이트 및 주문 이행을 나타내는 이벤트 -
배송 이벤트
배송된 상품의 상태 및 위치 업데이트를 기록하는 이벤트
IoT (Internet of Things)
-
센서 판독값
IoT 장치에서 수집한 온도, 습도, 압력 등 측정값 기록 이벤트 -
장치 상태 업데이트
온라인/오프라인 상태 또는 배터리 잔량과 같은 장치 상태 이벤트 -
알람 이벤트
동작 감지나 임계값 초과하는 등 특정 조건에 의해 트리거되는 이벤트
Event 데이터 처리를 필요로 하는 유스 케이스
- Real-time Reporting
- A/B Test Analytics
- Marketing Campaign Dashboard
- Infrastructure Monitoring - Real-time Alerting
- Fraud Detection
- Real-time Bidding
- Remote Patient Monitoring - Real-time Prediction (ML Model)
- Personalized Recommendation
실시간 데이터 처리 챌린지
실시간 데이터 처리 단계
1. 이벤트 데이터 모델 결정
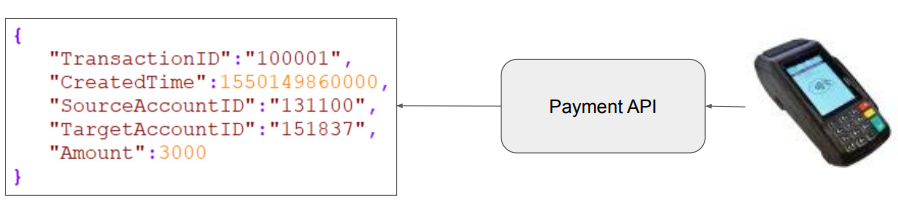
- 최소 Primary Key와 Timestamp가 필요
- 사용자 정보가 필요할 수도 있음
- 이벤트 자체에 대한 세부 정보 필요
2. 이벤트 데이터 전송/저장
Point to Point
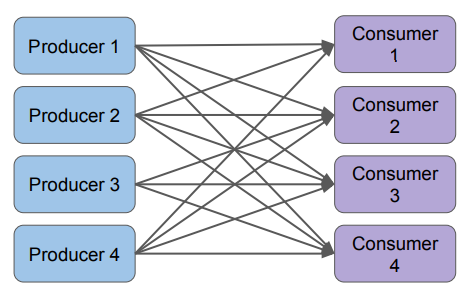
- Many to Many 연결이 필요
- Throughput은 중요하지만 Latency가 중요한 시스템에서 사용 가능
- 많은 API 레이어들이 이런 식으로 동작
- 다수의 Consumer들이 존재하는 경우 데이터를 중복해서 보내야함
Messaging Queue
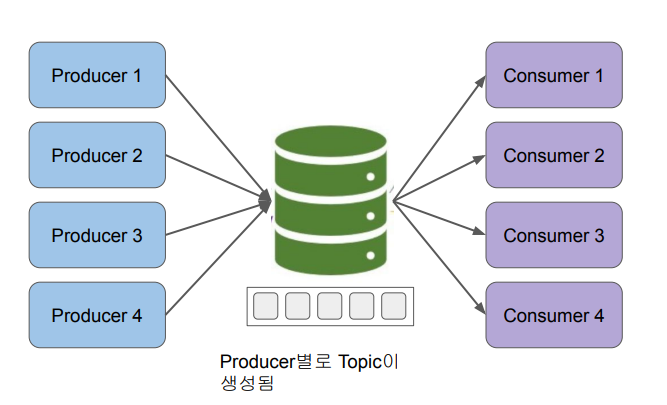
3. 이벤트 데이터 처리
- 앞서 데이터 저장 모델과 활용 사례에 데이터 처리 모델도 결정됨
Point-to-Point 형태의 경우
- Consumer쪽의 부담이 커지며 정말 바로바로 데이터가 처리되어야함 (Backpressure)
- 데이터 유실의 가능성이 큼 - Low Throughput Low Latency가 일반적
Messaging Queue의 경우
- 보통 micro-batch라는 형태로 아주 짧은 주기로 데이터를 모아서 처리
- Spark Streaming이 대표적 - 다수의 Consumer를 쉽게 만들 수 있다는 장점 존재
- Point-to-Point 보다는 운영이 용이
4. 이벤트 데이터 관리 이슈 모니터링과 해결

.