
📖 학습주제
Kafka와 Spark Streaming 기반 스트리밍 처리 (2)
Udemy 데이터팀 빌딩 여정
2014년 8월 데이터 엔지니어링팀 처음 빌딩
▹ 데이터 웨어하우스 도입 (Redshift)
▹ ETL 프로세스 개발
- 처음에는 crontab으로 관리하다가 Pinterest의 Pinball로 이전
- 파이썬을 기본 개발 언어로 사용
- 지금은 Airflow 사용 - 처음에는 데이터 복사만 하다가 점차 중요 프로세스 개발도 시작
- B2B 강사 보수 계산 (소비율에 따라 나눠줌)
- 중요 파이프라인의 경우 SLA (Service Level Agreement) 설정하고 지표로 계산
▹ 주로 개인 네트워크를 활용하여 구인
▹ 데이터 소스 추가 요청을 받는 슬랙 채널 개설
▹ 백엔드/프런트엔드 엔지니어링팀과 다양한 협업 시작
- Incremental Update를 하기위해 프로덕션 DB 테이블 스키마 변경
- updated_at과 deleted 필드 추가 - 사용자 이벤트 로그를 프로덕션 DB에서 nginx 로그로 빼는 작업 수행
- 처음에는 이를 파이썬 스크립트로 처리
- 나중에 이를 Hadoop 클러스터를 만들고 HDFS로 복사한 다음에 Hive로 처리
- 궁극적으로는 Kafka에 적재하고 다수의 consumer로 처리 (Connect 사용)
- 사용자 이벤트를 처리하는 마이크로서비스를구현하고 K8s 위에서 실행
2015년 4월 데이터 분석팀 설립
▹ Decision Science 팀
▹ BI 툴 도입 (ChartIO => Tableau)
▹ 데이터 분석 요구 프로세스 도입
- 티켓의 수와 카테고리가 데이터 관련 만족도와 개선 방향의 중요 지표가 됨
- 투명성의 중요성
▹ 지표 표준화
- 매출, Active Students, Active Instructors 등
- 지표 기반 의사결정 방법 교육 -> Next Feature Fallacy
▹ 내부 직무 전환 제도를 이용해서 디지털 마케터들을 분석가로 많이 뽑음
▹ B2C 마케팅 기여도 분석 프로세스 정립
▹ B2B 세일즈 파이프라인 분석 프로세스 정립
▹ 현업 팀들과 협업 가속화
- 하이브리드 모델
- 하지만 현업팀들의 욕구를 채워주기에는 역부족
- 데이터 문해력 교육과 함께 Self-service 모델로 전환을 모색
- 자주 들어오는 질문은 대시보드로 만들기
- 필터 등의 비주얼한 부분에 대해 요청이 많은 경우 데이터 셋은 데이터팀이 제공해주지만 대시보드 비주얼 변경은 현업팀이 담당 - 매주 2번 데이터 관련 오피스 아워 진행
- 데이터 관련 요청이 모두 보이는 슬랙 채널 개설
2015년 4월 데이터 사이언스 팀 설립
▹ Product Science 팀
▹ ML 모델을 프로덕션에 사용하기 시작
▹ A/B 프로세스 도입
▹ ML 모델 배포 프로세스 도입
- 다른 엔지니어링 팀과 긴밀한 협업 시작 (문화의 중요성)
- MLOps 프로세스 정착
▹ 다양한 조직에서 ML 관련 도움 쇄도
- 역시 인력 부족
- 분산 환경으로 전환 필요성 절감
Udemy 추천엔진 1기

- 배치로 매일 밤에 지난 90일간 방문했던 사용자들과 어느 조건이 충족되는 강의들의 모든 페어에 대해 각종 확률을 예측 (3개의 모델을 실행)
- 이 데이터 처리와 모델 예측 계산은 하둡과 하이브(Hive)를 사용해 수행
- 이 정보를 캐싱시스템에 저장하고 이를 유닛 랭킹과 유닛내의 강의 소팅에사용
- 모델 개발부터 최종 론치까지 총 8개월 소요
- 다양한 엔지니어링팀과의 협업 - 회사 문화가 중요
- A/B 테스트 프레임워크도 동시 개발
- 사용자 이벤트 로깅 시스템도 동시 개발 - 추천엔진 성공 지표와 객관적인 측정 방법 마련
- A/B 테스트 프레임워크
- 먼저 A/B 테스트 프레임웍으로 다른 테스트 수행하여 신뢰를 높임
- 지표와 객관적인 측정 없이는 순조로운 론치가 쉽지 않음
기술 스택
- Hadoop/Hive: 로그처리와 추천 모델 실행
- 자바로 메모리기반 협업 필터링을 구현 => 아예 추천전용 마이크로서비스 구현
Udemy 추천엔진 1기 발전과정
2015년 5월 ML 추천 모델 개발 시작

▹ Hadoop 클러스터 도입
- 클라우드가 아닌 On-prem에 직접 설치
- 배치 처리에 초점을 맞춤
- Hive와 Python 기반 UDF로 사용자 이벤트 데이터 처리
Nginx
-> 보통 웹서버 들의 앞단에 로드밸런서(Load Balancer)로 사용
-> 동시에 요청을 로그하는데 사용 (HTTP 요청헤더와 응답헤더 내용을 기록)
-> 보통 이 로그를 logstash등의 툴을 사용해서 HDFS나 Kafka로 푸시

▹ 먼저 A/B 프로세스 도입
- Data Driven Decision의 정점
- 객관적인 비교 프로세스를 도입하기 위함
- 자세한 분석을 위해 Tableau를 대시보드툴로 도입
▹ 동시에 모델 배포 프로세스에 대한 협의 시작
- 회사 문화의 중요성
- 처음에는 사용자별 추천 강의를 하루에 한번 저장하는 걸로 시작
- Daily Batch Processing
- 이 때 MLOps 프로세스 도입하여 매일 모델을 새로 훈련
- 하둡 클러스터의 도입없이는 불가능했음
▹ 모델 배포 프로세싱 과정
- R로 만든 모델 빌딩: 훈련 데이터는 Hive로 정제해서 만듬
- 이를 PMML이란 포맷으로 덤프
- PMML을 자바로 만든 추천 마이크로서비스에서 API 형태로 서빙
- 이를 백엔드 엔지니어링팀이 호출하고 모든 정보를 기록 (Impressions, Clicks, …)
- PMML을 자바에서 로딩해주는 오픈소스를 사용
▹ 2017년 여름에 실시간으로 추천 강의를 계산하는 걸로 고도화
Udemy 데이터 인프라 클라우드 이전
2016년 클라우드 이전
- CTO 설득에 시간이 오래 걸림
- 직접 데이터 센터를 운영하는 경우 서버 증설에 보통 2-3달이 걸림
- On-Prem과 클라우드의 하이브리드 모델에서 클라우드로 이전
- 기존 On-Prem 서버들은 개발용으로 전환
- 서버 용량 확장에 걸리는 시간 대폭 감소: 주문 => 배달 => 조립 => 설치 과정 불필요 - S3등을 사용하면서 데이터 시스템 발전에 큰 도움이 됨
2016년 데이터 레이크와 Spark 도입
- Hive 중심의 YARN/Hadoop 환경에서 Hive+Spark 중심으로 변화
- Spark 트레이닝 과정을 모든 데이터 엔지니어들과 원하는 데이터 과학자들에게 제공
- S3를 데이터 레이크와 HDFS를 사용
- Hive meta-store 중심으로 테이블들을 저장 - 여전히 Redshift를 정제된 구조화 데이터 분석을 위한 DW로 사용
- Data Engineer들을 중심으로 Spark 교육 시작
- 처음에는 Scala로 개발했으나 후에 PySpark으로 넘어감
- Notebook 환경으로 데이터 과학자들도 Spark ML을 직접 사용하기 시작
◦ 주피터 노트북과 제플린 노트북
Udemy 추천엔진 2기
추천 계산을 실시간으로 바꿈
- 배치 추천에 비해 많은 장점이 존재
- 유데미를 사용하는 모든 사용자에게 추천 제공
- 사용자가 로그인하거나 홈페이지를 방문하는 순간 추천 시작
- 불필요한 데이터 인프라 비용 절감 - 시스템의 복잡도가 올라감
- Kafka와 Cassandra와 같은 메세지큐와 NoSQL을 사용하기 시작
- 새로운 서비스들의 모니터링이 필요 - 각종 모델 예측 기능을 API로 노출
일부 피쳐는 배치로 여전히 매일매일 계산
- 하둡과 Spark을 사용 (모델 빌딩과 서빙과 협업 필터링)
- 이런 피쳐들은 Cassandra라는 NoSQL에 저장됨
추천/검색 관련 BE/FE 엔지니어들을 데이터팀 밑으로 이동
- 이 엔지니어들이 속한 팀을 Discovery Engineering 팀이라고 부름
- 이 팀이 나중에 사용자 이벤트 수집을 하는 마이크로서비스도 만듬
Udemy 추천엔진 2기 발전과정
2016년 Kafka 도입
▹ 점점더 실시간 데이터 처리에 대한 요구 증대: Kafka 도입
- 모든 사용자 이벤트 데이터는 모두 먼저 Kafka에 저장
2016년 Kafka 기반으로 여러가지 기능 구현
▹ 이를 바탕으로 추천을 실시간으로 변경 (하루 한번 배치에서 실시간)
- 변경하는데 1년 이상 걸림. 인력 부족과 경험 부족. 모니터링 책임 논의도 오래 걸림
▹ 이 위에 Fraud detection 시스템도 추가
▹ CS 팀과 연동 => 특정 사용자가 어떤 페이지를 보았는지 확인 가능
...
2016년 Spark ML과 Spark Streaming 사용
▹ Spark이 도입되면서 ML 모델링과 스트림 데이터 처리도 시작
- Scikit-learn과 R 기반 모델링에서 Spark ML 기반으로 변경
▹ Spark-Streaming을 사용해서 추천 모델을 실시간으로 변경 (2017년 여름)
- Kafka를 사용했고 운영상의 이슈로 처음에는 쉽지 않았음 (문화의 중요성 절감)
- 일부 feature들은 배치로 계산해서 Cassandra에 저장
- Pre-computed features라 부르고 이는 Spark SQL과 UDF를 사용 - 일부 feature들은 실시간으로 계산해서 사용
- 이는 Spark Streaming과 Kafka 사용
실시간 추천 엔진 아키텍처
- 사용자가 나타나는 순간 실시간으로 추천 계산


Udemy 이벤트 처리 시스템
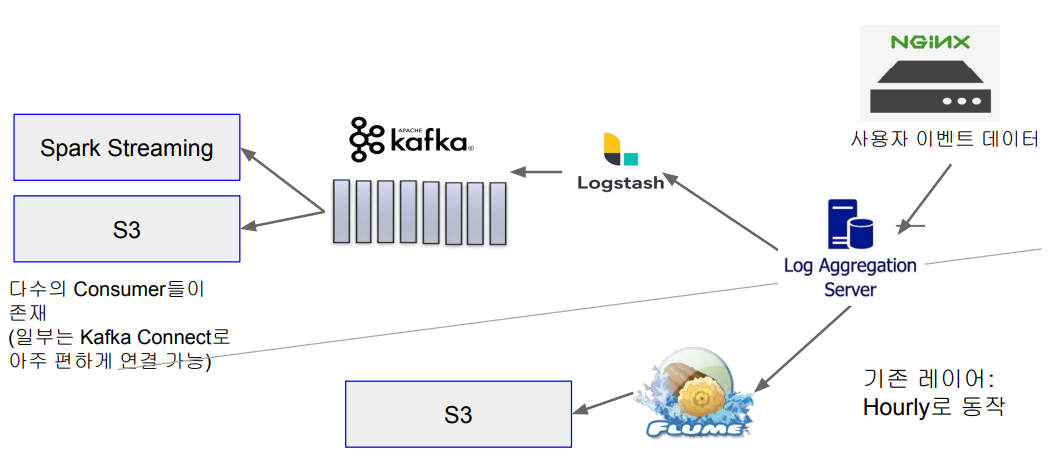
이벤트 처리 시스템 1기 시스템 구조
- 추천 엔진 2기 개발 때부터 2021년까지 사용한 구조
- Nginx를 사용해서 사용자 이벤트 수집
- 실시간처리와 배치처리를 위한 두 개의 시스템 존재
- 여러가지 문제점들이 존재
- 별도의 이벤트 수집 팀이 만들어지면서 Refactoring 시작 - 실시간처리와 배치처리를 위한 두 개의 시스템 존재
- 배치 처리는 syslog와 Flume을 사용 (nginx -> syslog -> Flume -> S3)
- 실시간 처리는 Kafka를 사용 (nginx -> syslog -> logstash -> Kafka)

이벤트 처리 시스템 1기 시스템 구조 (배치 처리)

Nginx 기반 시스템 1기의 문제점
▹ 낮은 확장성
- 기존 로그 집계 서버는 확장이 쉽지 않은 복잡한 구조. Nginx, Syslog, Logstash, Flume을 사용해서 Kafka와 S3로 별도로 적재
- 이벤트 로깅이 암묵적으로 이뤄지다보니 개발자들이 실수로 삭제하거나 내용을 모르고 수정하는 일이 빈번
▹ 낮은 데이터 품질
- 기존 시스템에는 실시간 이벤트 유효성 검사 메커니즘 부재. 스키마 검증
필요
- 다운스트림 소비자에게 장애가 발생해야만 이슈 인지
▹ 문서화 부족
Nginx 기반 시스템 1기 문제점 해결책
▹ Kafka를 더 많이 활용
- Kafka Schema Registry 사용하여 이벤트 데이터 유효성 검증
- Avro를 이벤트 데이터 포맷으로 사용하여 스키마 검증
- 두 개의 이벤트 스트림 Topic을 사용
- 하나는 원본, 다른 하나는 데이터가 추가된 버전
- 스키마 검증에 실패한 것들만 적재하는 Topic도 운영 - Kafka Connect를 사용하여 S3로 적재
▹ 이벤트 수집기를 별도 구현
- 프런트 엔드, 백엔드(Python, Kotlin), iOS, Android
- 이벤트 수집기를 K8s위에서 실행 (Auto-Scaling)
- AWS EKS(Elastic Kubernetes Service)를 사용
이벤트 처리 시스템 2기 시스템 구조


.