
📖 학습주제
Kafka와 Spark Streaming 기반 스트리밍 처리 (3)
Kafka
- 실시간 데이터를 처리하기 위해 설계된 오픈소스 분산 스트리밍 플랫폼
- 데이터 재생이 가능한 분산 커밋 로그 (Distributed Commit Log) - Scalability와 Fault Tolerance를 제공하는 Publish-Subscription 메시징 시스템
- Producer-Consumer - High Throughput과 Low Latency 실시간 데이터 처리에 맞게 구현됨
- 분산 아키텍처를 따르기 때문에 Scale Out이란 형태로 스케일 가능
- 서버 추가를 통해 Scalability 달성 (서버 = Broker) - 정해진 보유기한 (retention period) 동안 메시지를 저장
기존 메시징 시스템 및 데이터베이스와의 비교
- 기존 메시징 시스템과 달리, 카프카는 메시지를 보유 기간 동안 저장
- 소비자가 오프라인 상태일 때에도 내구성과 내결함성을 보장
- 기본 보유 기간은 일주일 - Kafka는 메시지 생산과 소비를 분리
- 생산자와 소비자가 각자의 속도에 맞춰 독립적으로 작업이 가능하도록 함
- 시스템 안정성을 높일 수 있음 - Kafka는 높은 처리량과 저지연 데이터 스트리밍을 제공
- Scale-Out 아키텍처 - 한 파티션 내에서는 메세지 순서를 보장해줌
- 다수의 파티션에 걸쳐서는 “Eventually Consistent”
- 토픽을 생성할 때 지정 가능 (Eventual Consistency vs. Strong Consistency) - 사내 내부 데이터 버스로 사용되기 시작
- 워낙 데이터 처리량이 크고 다수 소비자를 지원하기에 가능
Eventual Consistency
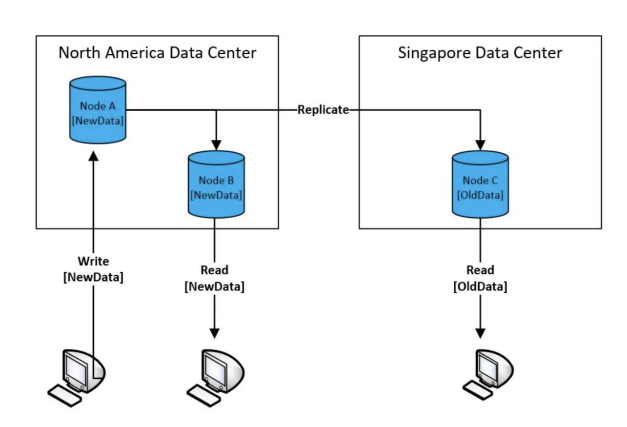
- 100대 서버로 구성된 분산 시스템에 레코드를 하나 쓴다면 그 레코드를 바로 읽을 수 있을까?
- 내가 쓴 레코드가 리턴이 될까? 이를 결정하는 것이 Consistency
- 보통 하나의 데이터 블록은 여러 서버에 나눠 저장됨 (Replication Factor)
◦ 그래서 데이터를 새로 쓰거나 수정하면 이게 전파되는데 시간이 걸림
- 보통 읽기는 다수의 데이터 카피 중에 하나를 대상으로 일어나기 때문에 앞서 전파 시간에 따라 데이터가 있을 수도 있고 없을 수도 있음 - Strong Consistency vs. Eventual Consistency
- 보통 데이터를 쓸때 복제가 완료될 때까지 기다리는 구조라면 Strong Consistency
- 그게 아니라 바로 리턴한다면 Eventual Consistency
Kafka의 주요 기능 및 이점
스트림 처리
- Kafka는 실시간 스트림 처리를 목표로 만들어진 서비스
- ksqlDB를 통해 SQL로도 실시간 이벤트 데이터 처리 가능
High Throughput (높은 처리량)
- Kafka는 초당 수백만 개의 메시지 처리 가능
Fault Tolerance (내결함성)
- Kafka는 데이터 복제 및 분산 커밋 로그 기능을 제공하여 장애 대응이 용이
Scalability (확장성)
- Kafka의 분산 아키텍처는 클러스터에 브로커를 추가하여 쉽게 수평 확장 가능
풍부한 생태계의 존재
- Kafka는 커넥터와 통합 도구로 구성된 풍부한 에코시스템을 갖추고 있어 다른 데이터 시스템 및 프레임워크와 쉽게 연동 가능
- Kafka Connect, Kafka Schema Registry
Kafka 아키텍처
데이터 이벤트 스트림
- 데이터 이벤트 스트림을 Topic이라고 부름
- Producer는 Topic을 만들고 Consumer는 Topic에서 데이터를 읽어들이는 구조
- 다수의 Consumer가 같은 Topic을 기반으로 읽어들이는 것이 가능
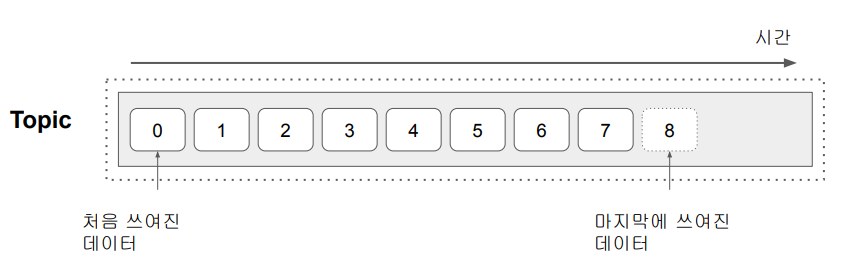
Message (Event) 구조: Key, Value, Timestamp
- 최대 1MB
- Timestamp는 보통 데이터가 Topic에 추가된 시점
- Key 자체도 복잡한 구조를 가질 수 있음
- Key가 나중에 Topic 데이터를 나눠서 저장할 때 사용됨 (Partitioning) - Header는 선택적 구성요소로 경량 메타 데이터 정보 (key-value pairs)
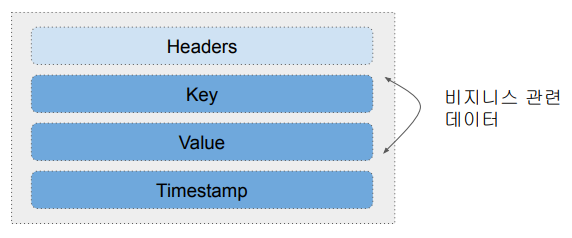
Topic과 Partition
- 하나의 Topic은 확장성을 위해 다수의 Partition으로 나뉘어 저장됨
- 메세지가 어느 Partition에 속하는지 결정하는 방식에 키의 유무에 따라 달라짐
- 키가 있다면 Hashing 값을 Partition의 수로 나눈 나머지로 결정
- 키가 없다면 라운드 로빈으로 결정
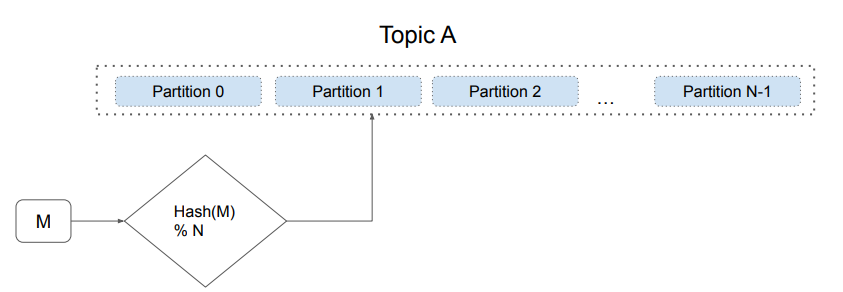
Topic과 Partition과 복제본
- 하나의 Partition은 Fail-over를 위해 Replication Partition을 가짐
- 각 Partition별로 Leader와 Follower가 존재
- 쓰기는 Leader를 통해 이뤄지고 읽기는 Leader/Follower들을 통해 이뤄짐
- Partition별로 Consistency Level을 설정 가능 (in-sync replica - “ack”)

Topic 파라미터
https://kafka.apache.org/documentation/#topicconfigs
Broker
- 실제 데이터를 저장하는 서버
- Kafka 클러스터는 기본적으로 다수의 Broker로 구성됨
- 여기에 원활한 관리와 부가 기능을 위한 다른 서비스들이 추가됨 (Zookeeper가 대표적)
- 한 클러스터는 최대 20만개까지 partition을 관리 가능
- Broker들이 실제로 Producer/Consumer들과 통신 수행 - 앞서 이야기한 Topic의 Partition들을 실제로 관리해주는 것이 Broker
- 한 Broker는 최대 4000개의 partition을 처리 가능 - Broker는 물리서버 혹은 VM 위에서 동작
- 해당 서버의 디스크에 Partition 데이터들을 기록함 - Broker의 수를 늘림으로써 클러스터 용량을 늘림 (Scale Out)
- 앞서 20만개, 4천개 제약은 Zookeeper를 사용하는 경우임
- 이 문제 해결을 위해서 Zookeeper를 대체하는 모드도 존재 (KRaft)
Broker와 Partition
- Kafka Broker를 Kafka Server 혹은 Kafka Node라고 부르기도 함
메타 정보 관리를 어떻게 할 것인가?
- Broker 리스트 관리 (Broker Membership)
- 누가 Controller인가? (Controller Election) - Topic 리스트 관리 (Topic Configuration)
- Topic을 구성하는 Partition 관리
- Partition별 Replica 관리 - Topic별 ACL (Access Control Lists) 관리
- Quota 관리
Zookeeper와 Controller
- Kafka 0.8.2 (2015년)부터 Controller가 도입됨
- Controller는 Broker이면서 Partition 관리 - 장기적으로 Zookeeper의 사용을 최소화하거나 사용 자체를 없애려는 것이 목표
Zookeeper
- 분산 시스템에서 널리 사용되는 Distributed Coordination Service
- 동기화, 구성 관리, 리더 선출 등 분산 시스템의 관리하고 조율을 위한 중앙 집중 서비스 제공 - 다양한 문제가 존재
- 지원하는 데이터 크기가 작고 동기모드로 동작하기에 처리 속도가 느림
◦ 즉 어느 스케일 이상으로 확장성이 떨어짐
- 복잡한 환경설정
Kafka 중요 개념
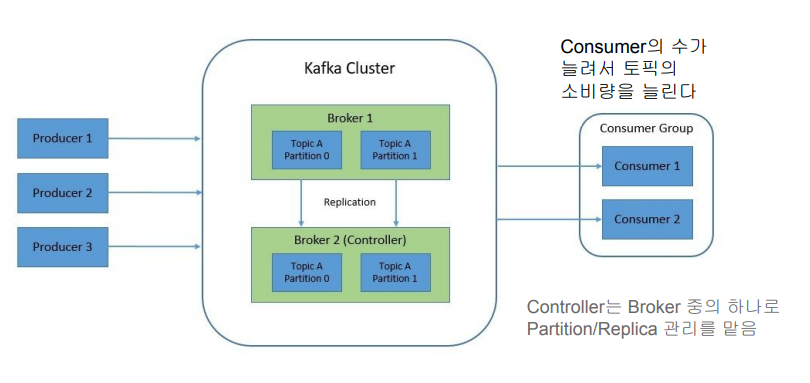
Topic
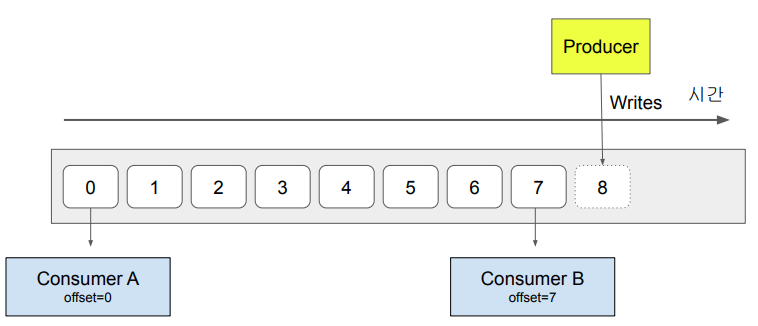
- Consumer가 데이터(Message)를 읽는다고 없어지지 않음
- Consumer별로 어느 위치의 데이터를 읽고 있는지 위치 정보를 유지함
- Fault Tolerance를 위해 이 정보는 중복 저장됨
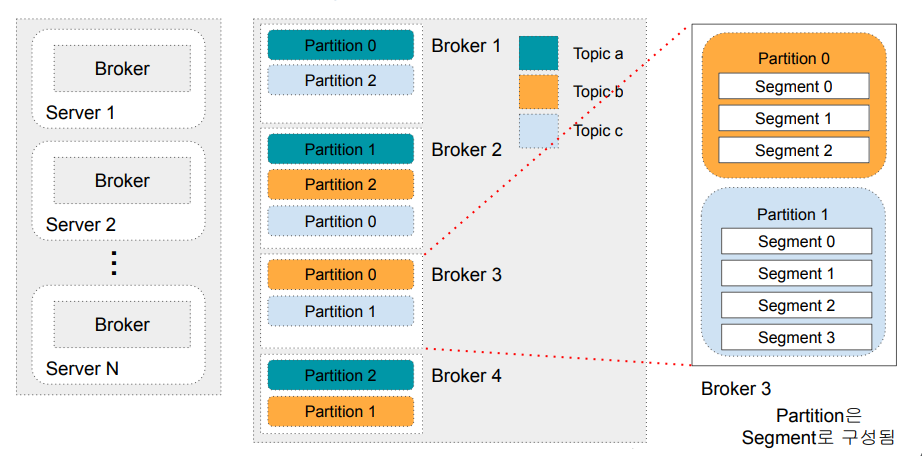
Topic과 Partition와 Replication
- 하나의 Topic은 다수의 Partition으로 구성 (Scalability)
- 하나의 Partition은 Fail-over를 위해 Replication Partition을 가짐
- 한 Partition에는 Leader와 Follower가 존재
- 쓰기는 Leader를 통해 하고 읽기는 모든 Leader와 Follower를 통해 함
Partition과 Segment
- 하나의 Partition은 다수의 Segment로 구성됨
- Segment는 변경되지 않는 추가만 되는 로그 파일이라고 볼 수 있음 (Immutable, Append-Only)
◦ Commit Log - 각 Segment는 디스크상에 존재하는 하나의 파일
- Segment는 최대 크기가 있어서 이를 넘어가면 새로 Segment 파일을 만들어냄
- 그래서 각 Segment는 데이터 오프셋 범위를 갖게 됨
- Segment의 최대 크기는 1GB 혹은 일주일치의 데이터
Commit Log
- Sequential, Immutable, Append-Only
- WAL (Write Ahead Logging)
- 데이터 무결성과 신뢰성을 보장하는 표준 방식
- 데이터베이스에 대한 모든 변경 사항을 먼저 Commit Log라는 추가 전용 파일에 기록 - Replication과 Fault Tolerance의 최소 단위
- Data Recovery나 Replay에 사용 가능
로그 파일의 특성 (Segment의 특성)
- 항상 뒤에 데이터(Message)가 쓰여짐: Append Only
- 한번 쓰여진 데이터는 불변 (immutable)
- Retention period에 따라 데이터를 제거하기도 함
- 데이터에는 번호(offset)가 주어짐
Broker의 역할
- Topic은 다수의 시간순으로 정렬된 Message들로 구성
- Producer는 Topic을 먼저 생성하고 속성 지정
- Producer가 Message들을 Broker로 전송
- Broker는 이를 Partition으로 나눠 저장 (중복 저장)
- Replication Factor: Leader & Follower - Consumer는 Broker를 통해 메세지를 읽음
- 하나의 Kafka 클러스터는 다수의 Broker로 구성됨
- 하나의 Broker는 다수의 Partition들을 관리/운영
- 한 Topic에 속한 Message들은 스케일을 위해 다수의 Partition들에 분산 저장
- 다수의 Partition들을 관리하는 역할을 하는 것이 Broker들
- 한 Broker가 보통 여러 개의 Partition들을 관리하며 이는 Broker가 있는 서버의 디스크에 저장됨
- Broker들 전체적으로 저장된 Partition/Replica의 관리는 Controller의 역할 - 하나의 Partition은 하나의 로그 파일이라고 볼 수 있음
- 각 Message들은 각기 위치 정보(offset)를 갖고 있음 - 이런 Message들의 저장 기한은 Retention Policy로 지정
Producer
Producer 기본
- 대부분의 프로그래밍 언어로 작성 가능
- Java, C/C++, Scala, Python, Go, .Net, REST API - Command Line Producer 유틸리티도 존재
Producer의 Partition 관리방법
- 하나의 Topic은 다수의 Partition으로 구성되며 이는 Producer가 결정
- Partition은 두 가지 용도로 사용됨
- Load Balancing
- Semantic Partitioning (특정 키를 가지고 레코드를 나누는 경우) - Producer가 사용 가능한 Partition 선택 방법
- 기본 Partition 선택: hash(key) % Partition의 수
- 라운드 로빈 : 돌아가면서 하나씩 사용
- 커스텀 Partition 로직을 구현할 수도 있음
Consumer
Consumer 기본
- Topic을 기반으로 Message를 읽어들임 (Subscription이란 개념 존재)
- Offset를 가지고 마지막 읽어들인 Message 위치정보 유지
- Command Line Consumer 유틸리티 존재
- Consumer Group라는 개념으로 Scaling 구현
- Backpressure 문제 해결을 위한 방법 - Consumer는 다시 Kafka에 새로운 토픽을 만들기도 함
- 아주 흔히 사용되는 방법으로 하나의 프로세스가 Consumer이자 Producer 역할 수행
Kafka 기타 기능
Kafka Connect
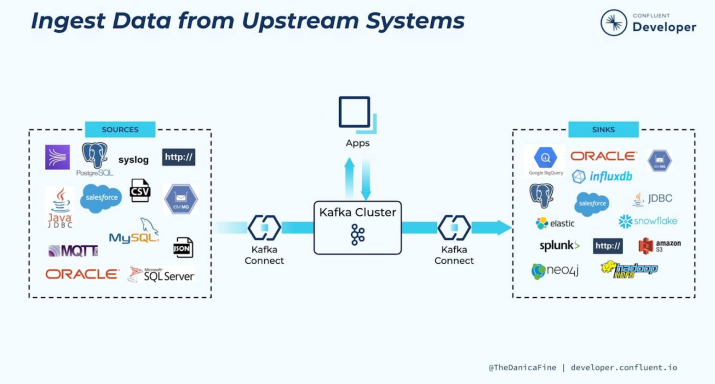
- Kafka 위에 만들어진 중앙집중 데이터 허브
- 별도의 서버들이 필요하며 Kafka Connect는 별도의 오픈소스 프로젝트임
- 데이터 버스 혹은 메세지 버스라고 볼 수 있음 - 두 가지 모드가 존재
- Standalone 모드 : 개발과 테스트
- Distributed 모드 - 데이터 시스템들 간의 데이터를 주고 받는 용도로 Kafka를 사용하는 것
- 데이터 시스템의 예 : 데이터베이스, 파일 시스템, 키-값 저장소, 검색 인덱스 등
- 데이터 소스와 데이터 싱크 - Broker들 중 일부나 별개 서버들로 Kafka Connect를 구성
- 그 안에 Task들을 Worker들이 수행. 여기서 Task들은 Producer/Consumer 역할
◦ Source Task, Sink Task
- 외부 데이터(Data Source)를 이벤트 스트림으로 읽어오는 것이 가능
- 내부 데이터를 외부(Data Sink)로 내보내어 Kafka를 기존 시스템과 지속적으로 통합 가능
◦ e.g.) S3 버킷으로 쉽게 저장
Kafka Schema Registry
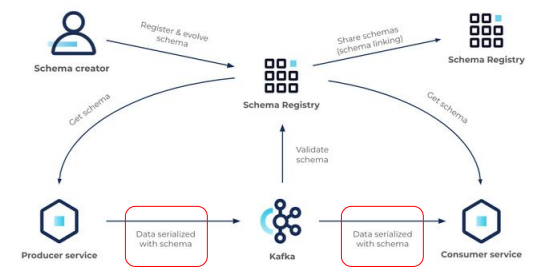
- Schema Registry는 Topic 메시지 데이터에 대한 스키마를 관리 및 검증하는데 사용
- Producer와 Consumer는 Schema Registry를 사용하여 스키마 변경을 처리
- Schema ID(와 버전)를 사용해서 다양한 포맷 변천(Schema Evolution)을 지원
- 보통 AVRO를 데이터 포맷으로 사용 (Protobuf, JSON) - 포맷 변경을 처리하는 방법
- Forward Compatibility : Producer부터 변경하고 Consumer를 점진적으로 변경
- Backward Compatibility : Consumer부터 변경하고 Producer를 점진적으로 변경
- Full Compatibility : 둘다 변경
Serialization (직렬화)
- 객체의 상태를 저장하거나 전송할 수 있는 형태로 변환하는 프로세스
- 보통 이 과정에서 데이터 압축등을 수행. 가능하다면 보내는 데이터의 스키마 정보 추가
Deserialization (역직렬화)
- Serialized된 데이터를 다시 사용할 수 있는 형태로 변환하는 Deserialization
- 이 과정에서 데이터 압축을 해제하거나 스키마 정보 등이 있다면 데이터 포맷 검증도 수행
Kafka 아키텍처
REST Proxy
- 클라이언트가 API 호출을 사용하여 Kafka를 사용 가능하게 해줌
- 메시지를 생성 및 소비하고, 토픽을 관리하는 간단하고 표준화된 방법을 제공
- REST Proxy는 메세지 Serialization과 Deserialization을 대신 수행해주고 Load Balancing도 수행 - 특히 사내 네트워크 밖에서 Kafka를 접근해야할 필요성이 있는 경우 더 유용
Kafka Streams
- Kafka Topic을 소비하고 생성하는 실시간 스트림 처리 라이브러리
ksqlDB
- Kafka Streams로 구현된 스트림 처리 데이터베이스로 KSQL을 대체
- SQL과 유사한 쿼리 언어. 필터링, 집계, 조인, 윈도우잉 등과 같은 SQL 작업 지원
- 연속 쿼리 : ksqlDB를 사용하면 데이터가 실시간으로 도착할 때 지속적으로 처리하는 연속 쿼리 생성 가능
- 지속 업데이트되는 뷰 지원 : 실시간으로 지속적으로 업데이트되는 집계 및 변환 가능 - Spark에서 보는 것과 비슷한 추세 : SQL이 대세
Kafka Python 프로그래밍
Kafka 프로그래밍 옵션들
Java
- Apache Kafka Java Client : 아파치 카프카의 공식 Java 클라이언트 라이브러리
- Spring Kafka : 스프링 프레임워크와 Kafka를 통합하기 위한 라이브러리
Python
- Confluent Kafka Python : Confluent에서 개발한 공식 Kafka Python 클라이언트 라이브러리
- Kafka-Python : 또다른 파이썬 기반 라이브러리
.NET
- Confluent Kafka .NET Client : Confluent에서 개발한 공식 Kafka .NET 클라이언트 라이브러리
Go
- Sarama : Go 언어용 Kafka 클라이언트 라이브러리로
Node.js:
- node-rdkafka : librdkafka를 기반으로 한 Node.js용 Kafka 클라이언트 라이브러리
- kafka-node : Node.js용 Kafka 클라이언트 라이브러리
Producer 예시
Python 모듈 설치 : pip3 install kafka-python
from time import sleep
from json import dumps
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'], # Broker들 중의 하나 이상을 지정하면 됨
value_serializer=lambda x: dumps(x).encode('utf-8')
)
# 로컬 Kafka 인스턴스를 연결하는 KafkaProducer 객체를 생성
# 전송하려는 데이터를 json 문자열로 변환한 다음 UTF-8로 인코딩하여 직렬화하는 방법을 정의
for j in range(999):
print("Iteration", j)
data = {'counter': j}
producer.send('topic_test', value=data) # key와 headers는 지정되어 있지 않음
sleep(0.5)
# 0.5초마다 "topic_test"라는 토픽과 반복 카운터를 데이터로 포함하는 이벤트를 전송.
# 데이터는 ‘counter’ 라는 키와 정수를 값으로 갖도록 구성
Comsumer 예시
from kafka import KafkaConsumer
from json import loads
from time import sleep
consumer = KafkaConsumer(
'topic_test',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest', # 'earliest' vs. 'latest'
enable_auto_commit=True, # enable_auto_commit=False라 면 commit 함수로 명시적으로 offset 위치를 커밋해야함
group_id='my-group-id',
value_deserializer=lambda x: loads(x.decode('utf-8') # 앞서 Producer에서 사용했던 value_serializer의 반대 작업 수행)
)
# 로컬 Kafka 인스턴스를 연결하는 KafkaConsumer 객체를 생성
# “topic_test” 토픽에서 가장 먼저 생긴 데이터부터 읽고 오프셋 정보는 계속해서 업데이트하고
# my-group-id라는 이름의 consumer group에 조인하도록 설정
for event in consumer:
event_data = event.value
# Do whatever you want
print(event_data)
sleep(2)
# 2초마다 "topic_test"라는 토픽에서 카운터 값을 읽도록 구성
.