
📖 학습주제
Kafka와 Spark Streaming 기반 스트리밍 처리 (5)
Spark Streaming
Spark의 등장
- 버클리 대학의 AMPLab에서 아파치 오픈소스 프로젝트로 2013년 시작
- 나중에 Databricks라는 스타트업 창업 - 하둡의 뒤를 잇는 2세대 빅데이터 기술
- YARN등을 분산환경으로 사용
- Scala로 작성됨 - 빅데이터 처리 관련 다양한 기능 제공
Spark 3.0의 구성
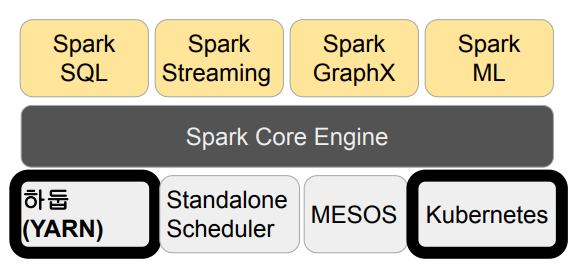
- Spark Core
- Spark SQL
- Spark ML
- Spark MLlib - Spark Streaming
- Spark GraphX
Spark Streaming

- 실시간 데이터 스트림 처리를 위한 Spark API
- Kafka, Kinesis, Flume, TCP 소켓 등의 다양한 소스에서 발생하는 데이터 처리 가능
- Join, Map, Reduce, Window와 같은 고급 함수 사용 가능
Spark Streaming 동작방식
- 데이터를 마이크로 배치로 처리
- 계속해서 위의 과정을 반복 (루프)
- 이렇게 읽은 데이터를 앞서 읽은 데이터에 머지
- 배치마다 데이터 위치 관리 (시작과 끝)
- Fault Tolerance와 데이터 재처리 관리 (실패시)
Spark Streaming의 내부 동작

- Spark Streaming은 실시간 입력 데이터 스트림을 배치로 나눈 다음
- Spark Engine에서 처리하여 최종 결과 스트림을 일괄적으로 생성
- DStream과 Structured Streaming 두 종류가 존재
Spark Structured Streaming
- Spark Streaming은 실시간 입력 데이터 스트림을 배치로 나눈 다음
- Spark Engine에서 처리하여 최종 결과 스트림을 일괄적으로 생성
| DStream | Structured Streaming |
|---|---|
| RDD 기반 스트리밍 처리 | DataFrame 기반 스트리밍 처리 |
| Spark SQL 엔진의 최적화 기능 사용불가 | Catalyst 기반 최적화 혜택을 가져감 |
| 이벤트 발생 시간 기반 처리 불가 | 이벤트 발생 시간 기반을 처리 가능 |
| 개발이 중단된 상태 (RDD 기반 모두에 적용됨) | 계속해서 기능이 추가되고 있음 |
Source & Sink
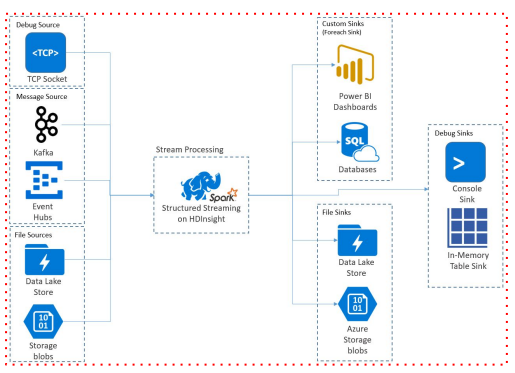
- 소스와 싱크는 외부 시스템(소스) 에서 스트리밍 데이터를 수집하고 처리된 데이터를 외부 시스템(싱크)으로 출력하는 것을 용이하게 하는 구성 요소
Source
- Source는 Kafka, Amazon Kinesis, Apache Flume, TCP/IP 소켓, HDFS, File 등을 Spark Structured Streaming에서 처리할 수 있도록 해줌
- 결국 Spark DataFrame으로 변환해줌
- e.g.) Kafka에서 Spark Structured Streaming으로 데이터를 수집하려는 경우, Kafka Source를 사용하여 Kafka 클러스터에서 하나 이상의 토픽에서 데이터를 가져와 DataFrame으로 변환 가능 - Spark DataFrame과 비교하면 readStream을 사용하는 점이 다름
example)
lines_df = spark.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", "9999") \
.load()Sink
- Sink는 Spark Structured Streaming에서 처리된 데이터를 외부 시스템이나 스토리지로 출력 가능하게 해줌
- Sink는 변환되거나 집계된 데이터가 어떻게 쓰이거나 소비되는지를 정의
- Source와 마찬가지로, Sink는 Kafka, HDFS, Amazon S3, Apache Cassandra, JDBC 데이터베이스 등과 같은 다양한 대상에 대해 사용 가능
- e.g.) Kafka Sink를 사용하여 Spark Structured Streaming에서 처리된 데이터를 Kafka Topic으로 쓰는 것이 가능 - OutputMode: 현재 Micro Batch의 결과가 Sink에 어떻게 쓰일지 결정
- Append
- Update : UPSERT 같은 느낌
- Complete : FULL REFRESH 같은 느낌
example)
word_count_query = counts_df.writeStream \
.format("console") \
.outputMode("complete") \
.option("checkpointLocation", "chk-point-dir") \
.start()전체 구조
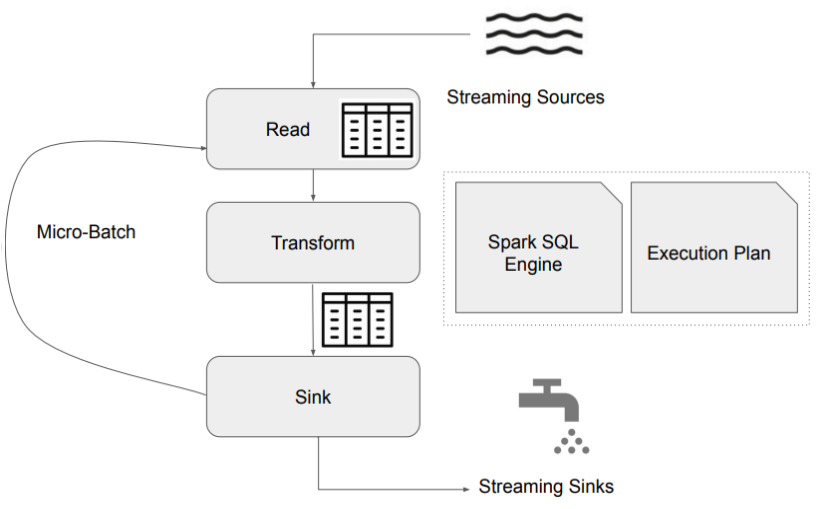
Micro Batch Trigger Option
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#triggers
- Unspecified : 디폴트 모드. 현재 Micro Batch가 끝나면 다음 Batch가 바로 시작
- Time Interval : 고정된 시간마다 Micro Batch를 시작. 현재 Batch가 지정된 시간을 넘어서 끝나면 끝나자마자 다음 Batch가 시작됨. 읽을 데이터가 없는 경우 시작되지 않음
- One Time => Available-Now: 지금 있는 데이터를 모두 처리하고 중단
- Continuous : 새로운 저지연 연속 처리 모드(https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#continuous-processing)에서 실행. 아직 베타/실험 버전
example)
# Default trigger (runs micro-batch as soon as it can)
df.writeStream \
.format("console") \
.start()
# ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream \
.format("console") \
.trigger(processingTime='2 seconds') \
.start()
# Available-now trigger
df.writeStream \
.format("console") \
.trigger(availableNow=True) \
.start()
# Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()Spark 환경 설정
Local Standalone Spark 소개
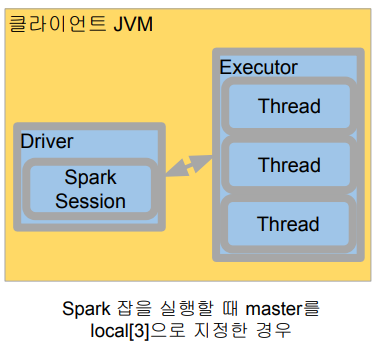
- Spark Cluster Manager로 local[n] 지정
- master를 local[n]으로 지정
- master는 클러스터 매니저를 지정하는데 사용 - 주로 개발이나 간단한 테스트 용도
- 하나의 JVM에서 모든 프로세스를 실행
- 하나의 Driver와 하나의 Executor가 실행됨
- 1+ 쓰레드가 Executor안에서 실행됨 - Executor안에 생성되는 쓰레드 수
- local:하나의 쓰레드만 생성
- local[*]: 컴퓨터 CPU 수만큼 쓰레드를 생성
Local Standalone Spark 설치
- Mac이라면 Mac Catalina 혹은 이후 버전 기준
- Z쉘이 기본으로 사용됨 (그전에는 Bash 쉘) - 자바 관련 설정
- JDK8/11이 필요: 터미널에서 java -version 명령으로 체크
- JAVA_HOME 환경변수를 Z쉘 시작 스크립트(~/.zshrc)에 등록
◦ echo export "JAVA_HOME=$(/usr/libexec/java_home)" >> ~/.zshrc - Spark 다운로드
https://spark.apache.org/downloads.html - 세부 설치 방법
- 맥
https://github.com/keeyong/beginner-spark-programming-with-pyspark/blob/main/spark/local_installation.md
- 윈도우
https://github.com/keeyong/beginner-spark-programming-with-pyspark/blob/main/spark/local_installation_windows.md
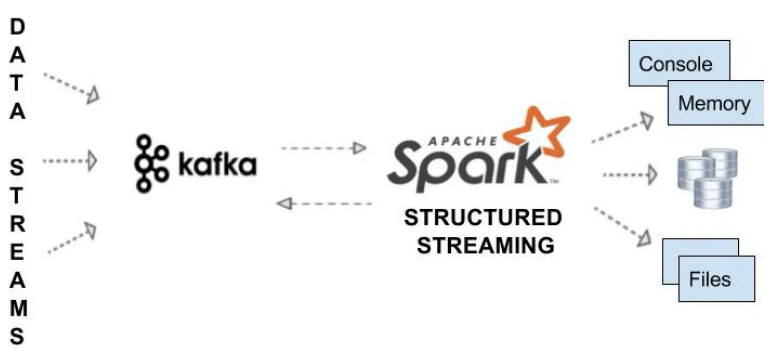
Kafka Stream
Kafka와 Spark Streaming 다이어그램
Spark Structured Streaming을 보통 사용함
정리
스트리밍 데이터 처리
- 배치 처리 vs. 실시간 (스트리밍) 처리
- Kafka
- 대량의 실시간 데이터를 저장/처리하는 분산 스트리밍 플랫폼
- Topic => Partition => Segment
- Event/Message: Key, Value, Timestamp, Headers
- Producers, Brokers (Controller), Consumers
- Schema Registry, Connect, REST Proxy, ksqlDB, Kafka Streams, … - Spark Streaming
- Micro-batch 형태로 데이터를 실시간 처리해주는 Spark 확장 모듈
- Kafka의 토픽에서 데이터를 읽어들여서 데이터 변환, 집계, 필터링 등의 작업 수행 가능
- 이제는 DStream이 아닌 Structured Streaming을 사용하는 것이 일반적

.